-
Notifications
You must be signed in to change notification settings - Fork 771
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Showing
4 changed files
with
613 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,31 @@ | ||
| # Text-to-speech (TTS) with Parler-TTS and OpenVINO™ | ||
|
|
||
| Parler-TTS is a lightweight text-to-speech (TTS) model that can generate high-quality, natural sounding speech in the style of a given speaker (gender, pitch, speaking style, etc). It is a reproduction of work from the paper [Natural language guidance of high-fidelity text-to-speech with synthetic annotations](https://www.text-description-to-speech.com/) by Dan Lyth and Simon King, from Stability AI and Edinburgh University respectively. | ||
|
|
||
| 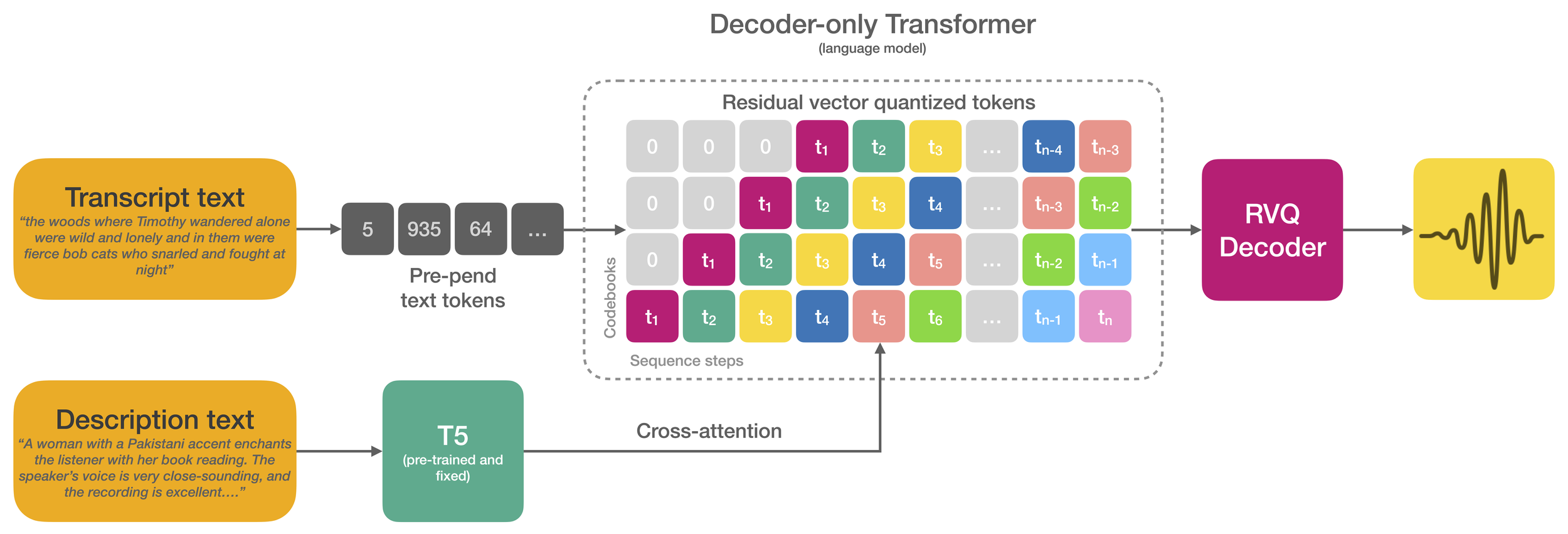 | ||
|
|
||
| Text-to-speech models trained on large-scale datasets have demonstrated impressive in-context learning capabilities and naturalness. However, control of speaker identity and style in these models typically requires conditioning on reference speech recordings, limiting creative applications. Alternatively, natural language prompting of speaker identity and style has demonstrated promising results and provides an intuitive method of control. However, reliance on human-labeled descriptions prevents scaling to large datasets. | ||
|
|
||
| This work bridges the gap between these two approaches. The authors propose a scalable method for labeling various aspects of speaker identity, style, and recording conditions. This method then is applied to a 45k hour dataset, which is used to train a speech language model. Furthermore, the authors propose simple methods for increasing audio fidelity, significantly outperforming recent work despite relying entirely on found data. | ||
|
|
||
|
|
||
| [GitHub repository](https://github.com/huggingface/parler-tts) | ||
|
|
||
| [HuggingFace page](https://huggingface.co/parler-tts) | ||
|
|
||
|
|
||
| ## Notebook Contents | ||
|
|
||
| This notebook demonstrates how to convert and run the Parler TTS model using OpenVINO. | ||
|
|
||
| Notebook contains the following steps: | ||
| 1. Load the original model and inference. | ||
| 2. Convert the model to OpenVINO IR. | ||
| 3. Compiling models and inference. | ||
| 4. Interactive inference. | ||
|
|
||
| ## Installation instructions | ||
|
|
||
| This is a self-contained example that relies solely on its own code.</br> | ||
| We recommend running the notebook in a virtual environment. You only need a Jupyter server to start. | ||
| For details, please refer to [Installation Guide](../../README.md). |
579 changes: 579 additions & 0 deletions
579
notebooks/parler-tts-text-to-speech/parler-tts-text-to-speech.ipynb
Large diffs are not rendered by default.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters