Importing a pool with corrupted log device #2099
Comments
|
@kartweel I agree, it would be nice to have an option for this in zpool import. It will result in data loss so it shouldn't be the default, but it seems like a reasonable option. This is also one of the reasons that log devices should be configured as mirrors is possible. |
|
There will be data loss only in case if the server was crashed before (in other words data should be read from the log device), am I wrong? |
|
@sopmot Your right. If there was no crash then there will be nothing on the log device which needs to be replayed. |
|
If no-one objects, I'd like to take a shot at this... |
|
Any ideas on how to simulate/reproduce this? I tried a VM with a 32GB pool disk and a 8GB slog disk. Set sync=always and started a big sequential write, then powered off the VM. Booted it from a rescue centos CD and overwrote a few hundred MB a couple of hundred MB into the log device (sdc), then rebooted into centos and tried to import the pool. It says the pool is faulted due to label issues and such. 'zpool status' doesn't even identify the presence of an slog device. I suspect I may have zeroed out too much stuff on /dev/sdc. If I export the pool and import it, it shows up OK including the presence of the log device. I'm wondering if I need to target the corruption more narrowly? |
|
@dswartz By all means. You should be able to cause this by powering off the VM while there are dirty records on the log device. Then before importing the pool I'd suggest damaging a few bytes in the label of the log device. This should cause it to fail the checksum and I'd expect recreate this issue. |
|
Okay, back to work on this :) |
|
Hmmm, not having a lot of luck with repro. Can you give me a hint as to how to find the label to damage it? I looked with zdb and it said there were 4 labels on /dev/sdc (the slog device). I got a bulk write going with sync=always dataset and confirmed traffic to the slog, but when I have managed to damage the slog device, it either doesn't show up at all, or it shows as faulted, but the pool mounts anyway? |
This is snippets from a script I wrote when I needed to backup the labels: |
|
Thanks for the tip. While thinking about this, I came up with a very simple way to simulate this. I added debug code to vdev_validate() to fake an error. Like so: diff --git a/module/zfs/vdev.c b/module/zfs/vdev.c
I booted with this zfs module. I then created a dataset with sync=always and started a dd from the root disk to a file on that dataset and confirmed it was using the SLOG. I then reset the VM. On reboot, I saw this: [root@zolbuild ~]# zpool status which certainly sounds like the OP's complaint. I then ran 'zpool clear' and get this: pool: git What is odd at this point is that it won't let me remove either 'sdc' or '5745074719075200392' from the pool. Giving either as 'zpool remove git xxx' gives no error but doesn't change the pool. I had to remove the virtual log disk and export/import the pool to get it back clean. |
|
It's even weirder than I thought! I did 'zpool export git', removed the virtual disk, did 'zpool import git' and got this (as expected): [root@zolbuild ~]# zpool import git So I re-did the import with '-m' and now: [root@zolbuild ~]# zpool status So it still insists on the log disk, and I still can't remove it. I think I need to re-add the virtual disk and do a replace? |
|
Wow, something is wrong - even that didn't work. I could NOT get rid of the log disk. I wonder if that is because I had that debug code in vdev_validate? Even if so, why would it need to validate a device being removed from the pool? |
|
Ok, there may be a bug there (inability to remove the log disk from the pool with no errors), but I cannot reproduce it (I have tried several times.) So here is where I am at: I can reproduce a faulted pool with the message about bad intent log. But the error message tells me to do 'zpool clear'. Doing so leaves the log disk faulted but the pool present (and degraded). You can then remove and re-add the log disk. So I am working on how to leverage '-f' to force the log device to be re-initialized cleanly... |
|
Hello, Referring to the following, above: #2099 (comment), more specifically to that part:
I'm having the exact same issue with one of my pools here, running ZoL's latest stable (0.6.5.3) installed from the official repo on EL6. The only difference is that, contrary to @dswartz, I tried to export the pool, remove the log device and then import it back in, but still the "zpool remove" accomplishes nothing and the device keeps showing on zpool status. I've posted extensively about the problem on a zfs-discuss mailing list thread starting here: http://list.zfsonlinux.org/pipermail/zfs-discuss/2015-December/024006.html I'm going ahead and opening a new issue for this, referring to this one, and to the above mail thread. Cheers, |
|
I am also running into this - cannot remove an OFFLINE zil device. I am using version 0.6.5.6-0ubuntu14. |
|
I am having a (real-life) problem importing a pool with a corrupted ZIL at the moment. ZFS v0.8.2-1 on Debian 9 My log device corrupted due to a power outage and the pool will now not import even with the The closest I get is with: which returns the command I also tried reformatting the log partition but that doesn't seem to help. I don't mind losing whatever transactions were in the log waiting to be written. additional: |
|
@zeigerpuppy you're absolutely on the right track, the Assuming that fails, please grab the kernel debug log by dumping This should give us a better indication of exactly what the issue is. |
|
Thanks for the tip. I have also included the output of zdb (sanitised serial numbers) for reference: The pool recently had two drives replaced and resilvered, which all went well. |
|
Thus far I haven't been able to reproduce the issue locally, but there are a few more things I'd like to try. In the meanwhile, would you mind checking if you can import the pool readonly. |
|
unfortunately read-only doesn't seem to work either (same errors as before in outputs |
|
For the record, after keeping my bad pool around (see #4067) for the best part of 4 years, a few months ago I migrated it to another machine/disk set and erased the previous one :-P so I can no longer help to debug this. Anyway, trying to reproduce the issue here with a testpool (creating a 2-disk mirror with a separate log device, then exporting, then first removing the log device from the system and trying to import the pool back, then ditto but purposefully corrupting the log device with |
|
I'm wondering if there is a brute-force way to export this pool and then reimport. Still stuck with trying to get the pool to load with the corrupted log device. |
|
having a look at logs in more detail, I think I may be on to something: note the line I guess the guid has changed, so that may be causing the inability to use allow the missing device... I will try looking for a way to set the guid. |
|
scrub that idea, I erased the label and it didn't help when attempting to import again, the error does change, as is to be expected: It does make me wonder if there's a manual way of setting the header/label on the log partition... maybe that would fool Could I use |
|
Additional: I noticed this command from the Oracle docs, but it is not implemented in zfsonlinux:
This would seem to allow recovering metadata from one device to another, is there any equivalent in zfsonlinux? I guess that if this were available, then something like the following would help: |
|
@zeigerpuppy I wasn't aware of the It's also surprising that a readonly import would fail. When importing readonly the log device cannot be replayed so it's skipped in this circumstance. Looking at the logs you posted it also appears that the import attempted to rewind several txgs to import. This is expected for a power failure, it's not impossible that there is an issue in the import path when handling both failures. Can you try importing the pool at a specific transaction group. Based on your logs you'll want to try If you're willing to privately share the pool metadata for debugging purposes there is some additional investigation which could be done. The If you're game, you can generate the vdev dump like this: |
|
@behlendorf I tried both: and but they both return error: there's no new messages in I am happy to share the metadata, however, when I tried dumping the metadata with the commands: I get error: there is a small |
|
›I have this same issue due to power cuts. The log ssd has been faulted, pool will not import
|
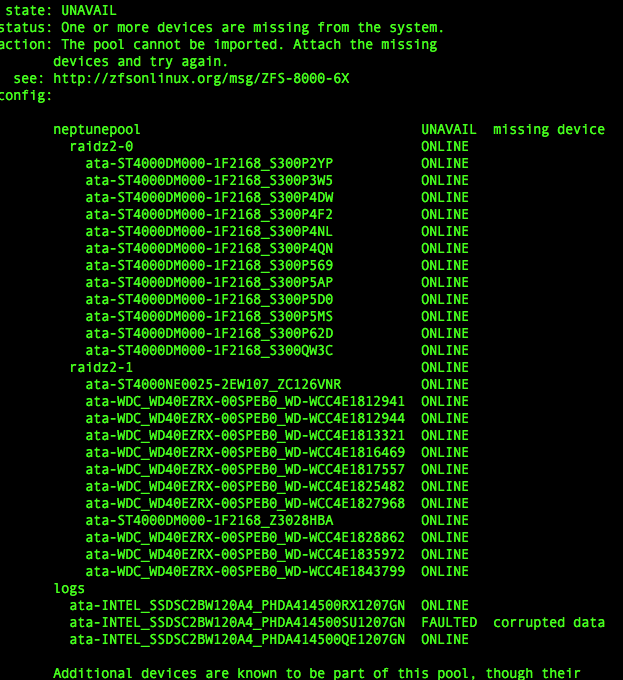
|
Resolved. The import issue was solved by destroying the faulted log disk's file system completely. zpool add working-pool-name cache disk-id-of-broken-zil -f Now that the corrupted disk was completely forced out of its old pool, zpool import was then able to import and bring the faulty pool back online by rolling back to the other 2 uncorrupted log disks "See screenshot from my previous post". zpool import -fF -m fautly-pool-name The lesson here is to mirror the log disks, although that might have given me 3 corrupted mirrors. To prevent this problem happening again on this live production pool, ZIL logs have been removed until further DR tests can be conducted. Here is the now fully functional and healthy repaired pool |

|
On 18 Jan 2020, at 12:25, OCDPro ***@***.***> wrote:
The import issue was solved by destroying the faulted log disk's file system completely.
How did you do that? I thought you said you had ‘dd’ the device before trying to import the pool.. ?
removing it would have been a waste.
You could have removed the disk, imported the pool and then put the disk back. If you have
hot-swap bays that is…
A ‘eject’ command could also have been done. In the SCSI subsystem, you can easily remove
and attach a device from the command line by utilising the /sys FS..
The lesson here is to mirror the log disks, although that might have given me 3 corrupted mirrors.
Not necessarily.. The replication isn’t always instantaneous.. Or?
|
No, that was someone else's issue in this thread where "dd" did not work. I think @zeigerpuppy, who only has 1 log disk in the pool.
Thank you, I will read up more on /sys FS. The ssd's are not hot swap and the system is remote so anything that can save a drive to site is welcome advice :)
Agreed, not always instant replication. |
|
@OCDPro I tried your idea of moving the corrupted log device to another pool: As you suggested, this now changes the device from UNAVAIL to FAULTED in my However, in my case, this still doesn't allow the importing of the faulty pool. returns and p.s. I have updated to the latest zfs release 0.8.4-1 I would like to try removing the device altogether, but I'm not sure that will help and it's also a bit difficult as it also has some system partitions on the same SSD. The dump of |
|
Have you tried completely deleting the partition ......FXXX-part6 with fdisk or cfdisk? So that there is no longer a "part6" This should make the faulted log disk go missing to the zfs pool, then try import again zpool import -f -F -m poolname Not sure if this will work without a secondary log device to roll back to. |
|
Thanks for the suggestion @OCDPro. |
This absolutely should not be the case. IMHU, A log device is considered to be expendable.
And even so, the data loss 'window' is much smaller than most people think: as everything that's written on the ZIL is also kept in memory (and committed from there to the pool data area), the only way to lose data due to a failed/lost log device is for the machine to crash (panic, AC power loss, etc) while there this data is still being committed and then losing the log device when the machine comes back up and ZFS tries to access the ZIL to commit the transactions from there (since it lost them in RAM due to the crash). |
If a log device is corrupted, zpool import will refuse to import the pool. The workaround is to remove the actual device from the system, then zpool import -m to import the pool with the missing device.
It would be great to be able to zpool import -f (Or some other flag like -m) and import the pool regardless of the corrupt log device. The pool could then just import in a degraded state (like when a device is missing).
It just appears to be a hole in the zpool import command. Although data corruption in the log device could result in lost data, the only thing that you can really do in this case is import the pool regardless and continue on with the lost data.
The text was updated successfully, but these errors were encountered: