![]()

Zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in service architectures. Features include both the collection and lookup of this data.
If you have a trace ID in a log file, you can jump directly to it. Otherwise, you can query based on attributes such as service, operation name, tags and duration. Some interesting data will be summarized for you, such as the percentage of time spent in a service, and whether operations failed.
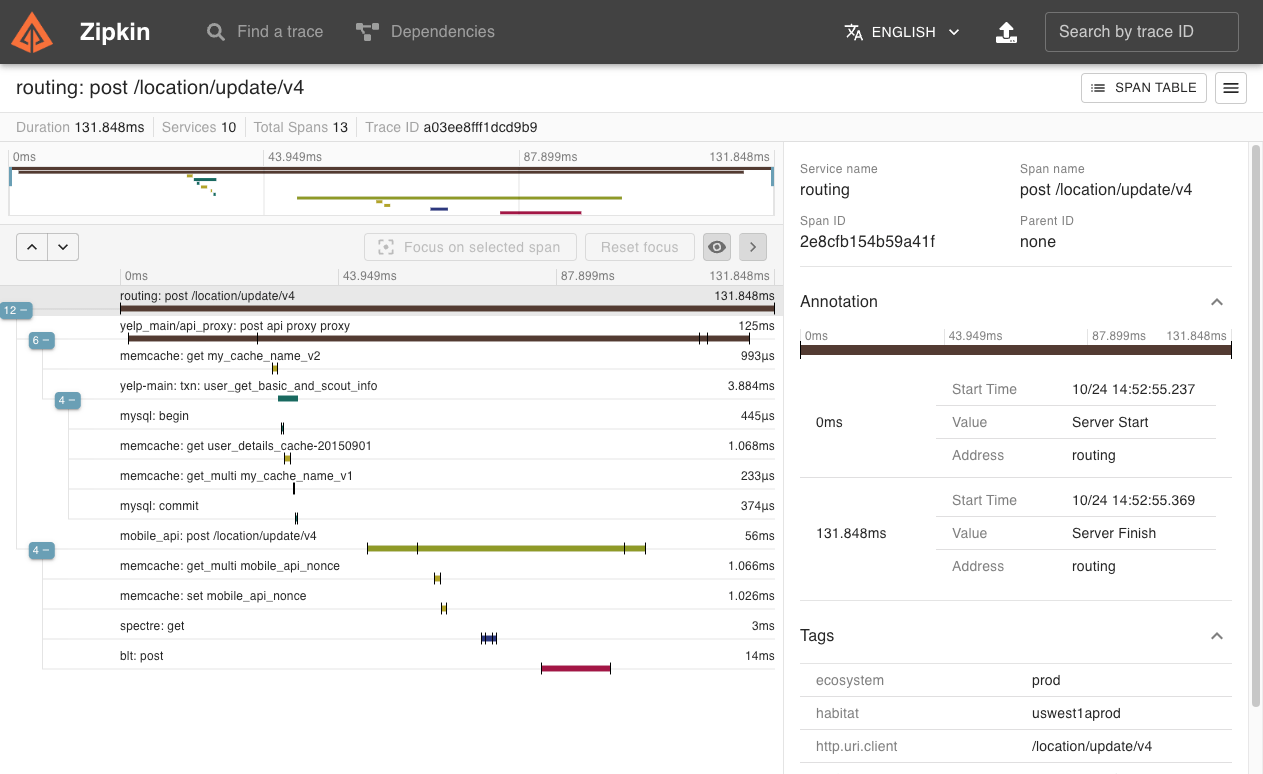
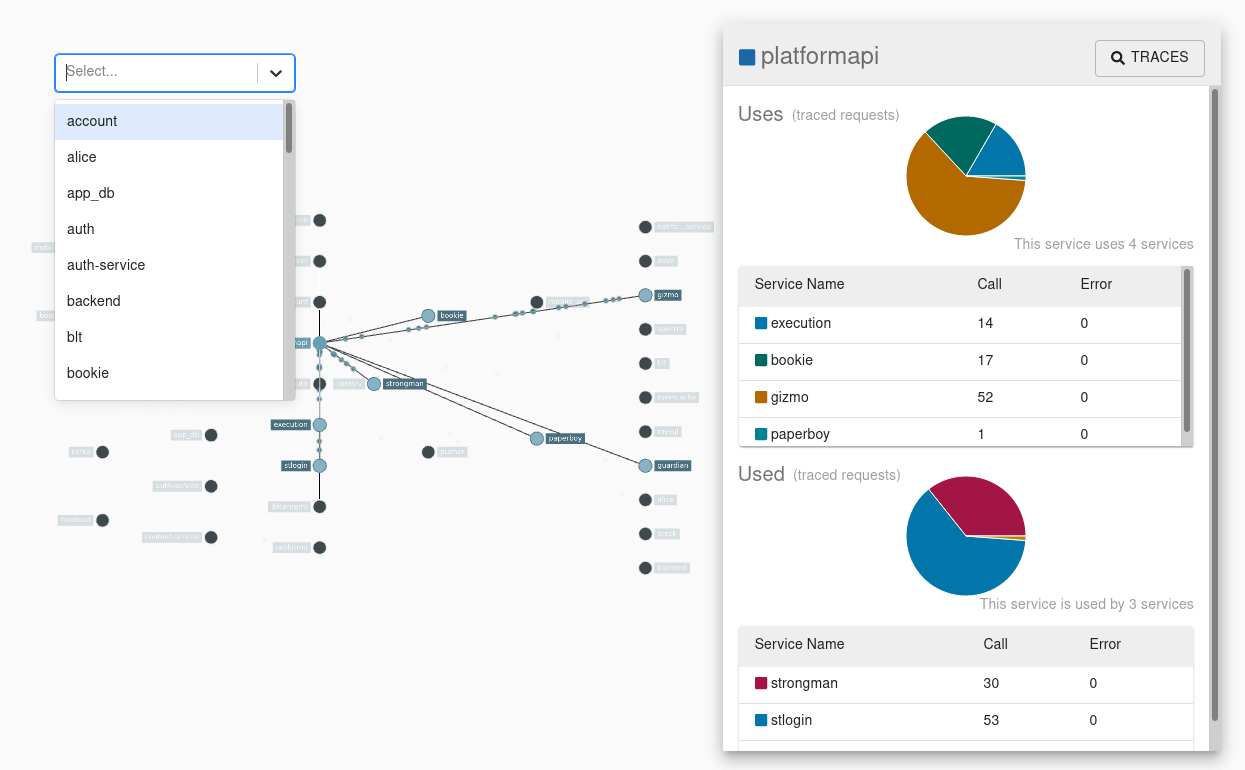
The Zipkin UI also presents a dependency diagram showing how many traced requests went through each application. This can be helpful for identifying aggregate behavior including error paths or calls to deprecated services.
Application’s need to be “instrumented” to report trace data to Zipkin. This usually means configuration of a tracer or instrumentation library. The most popular ways to report data to Zipkin are via http or Kafka, though many other options exist, such as Apache ActiveMQ, gRPC and RabbitMQ. The data served to the UI is stored in-memory, or persistently with a supported backend such as Apache Cassandra or Elasticsearch.
The quickest way to get started is to fetch the latest released server as a self-contained executable jar. Note that the Zipkin server requires minimum JRE 17+. For example:
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jarYou can also start Zipkin via Docker.
# Note: this is mirrored as ghcr.io/openzipkin/zipkin
docker run -d -p 9411:9411 openzipkin/zipkinOnce the server is running, you can view traces with the Zipkin UI at http://localhost:9411/zipkin.
If your applications aren't sending traces, yet, configure them with Zipkin instrumentation or try one of our examples.
Check out the zipkin-server documentation for configuration details, or Docker examples for how to use docker-compose.
The slim build of Zipkin is smaller and starts faster. It supports in-memory and Elasticsearch storage, but doesn't support messaging transports like Kafka or RabbitMQ. If these constraints match your needs, you can try slim like below:
Running via Java:
curl -sSL https://zipkin.io/quickstart.sh | bash -s io.zipkin:zipkin-server:LATEST:slim zipkin.jar
java -jar zipkin.jarRunning via Docker:
# Note: this is mirrored as ghcr.io/openzipkin/zipkin-slim
docker run -d -p 9411:9411 openzipkin/zipkin-slimRunning via Homebrew:
brew install zipkin
# to run in foreground
zipkin
# to run in background
brew services start zipkinThe core library is used by both Zipkin instrumentation and the Zipkin server.
This includes built-in codec for Zipkin's v1 and v2 json formats. A direct dependency on gson (json library) is avoided by minifying and repackaging classes used. The result is a 155k jar which won't conflict with any library you use.
Ex.
// All data are recorded against the same endpoint, associated with your service graph
localEndpoint = Endpoint.newBuilder().serviceName("tweetie").ip("192.168.0.1").build()
span = Span.newBuilder()
.traceId("d3d200866a77cc59")
.id("d3d200866a77cc59")
.name("targz")
.localEndpoint(localEndpoint)
.timestamp(epochMicros())
.duration(durationInMicros)
.putTag("compression.level", "9");
// Now, you can encode it as json
bytes = SpanBytesEncoder.JSON_V2.encode(span);Note: The above is just an example, most likely you'll want to use an existing tracing library like Brave
The minimum Java language level of the core library is 8. This helps support those writing agent instrumentation. Version 2.x was the last to support Java 6.
Note: zipkin-reporter-brave does not use this library. So, brave still supports Java 6.
Zipkin includes a StorageComponent, used to store and query spans and dependency links. This is used by the server and those making collectors, or span reporters. For this reason, storage components have minimal dependencies, though require Java 17+.
Ex.
// this won't create network connections
storage = ElasticsearchStorage.newBuilder()
.hosts(asList("http://myelastic:9200")).build();
// prepare a call
traceCall = storage.spanStore().getTrace("d3d200866a77cc59");
// execute it synchronously or asynchronously
trace = traceCall.execute();
// clean up any sessions, etc
storage.close();The InMemoryStorage component is packaged in zipkin's core library. It is neither persistent, nor viable for realistic work loads. Its purpose is for testing, for example starting a server on your laptop without any database needed.
The Cassandra component uses Cassandra 3.11.3+ features, but is tested against the latest patch of Cassandra 4.1.
This is the second generation of our Cassandra schema. It stores spans using UDTs, such that they appear like Zipkin v2 json in cqlsh. It is designed for scale, and uses a combination of SASI and manually implemented indexes to make querying larger data more performant.
Note: This store requires a job to aggregate dependency links.
The Elasticsearch component uses Elasticsearch 5+ features, but is tested against Elasticsearch 7-8.x.
It stores spans as Zipkin v2 json so that integration with other tools is straightforward. To help with scale, this uses a combination of custom and manually implemented indexing.
Note: This store requires a spark job to aggregate dependency links.
The following API endpoints provide search features, and are enabled by default. Search primarily allows the trace list screen of the UI operate.
GET /services- Distinct Span.localServiceNameGET /remoteServices?serviceName=X- Distinct Span.remoteServiceName by Span.localServiceNameGET /spans?serviceName=X- Distinct Span.name by Span.localServiceNameGET /autocompleteKeys- Distinct keys of Span.tags subject to configurable whitelistGET /autocompleteValues?key=X- Distinct values of Span.tags by keyGET /traces- Traces matching a query possibly including the above criteria
When search is disabled, traces can only be retrieved by ID
(GET /trace/{traceId}). Disabling search is only viable when there is
an alternative way to find trace IDs, such as logs. Disabling search can
reduce storage costs or increase write throughput.
StorageComponent.Builder.searchEnabled(false) is implied when a zipkin
is run with the env variable SEARCH_ENABLED=false.
The following components are no longer encouraged, but exist to help aid transition to supported ones. These are indicated as "v1" as they use data layouts based on Zipkin's V1 Thrift model, as opposed to the simpler v2 data model currently used.
The MySQL v1 component uses MySQL 5.6+ features, but is tested against MariaDB 10.11.
The schema was designed to be easy to understand and get started with; it was not designed for performance. Ex spans fields are columns, so you can perform ad-hoc queries using SQL. However, this component has known performance issues: queries will eventually take seconds to return if you put a lot of data into it.
This store does not require a job to aggregate dependency links. However, running the job will improve performance of dependencies queries.
The Zipkin server receives spans via HTTP POST and respond to queries from its UI. It can also run collectors, such as RabbitMQ or Kafka.
To run the server from the currently checked out source, enter the following. JDK 17+ is required to compile the source.
# Build the server and also make its dependencies
$ ./mvnw -q --batch-mode -DskipTests --also-make -pl zipkin-server clean install
# Run the server
$ java -jar ./zipkin-server/target/zipkin-server-*exec.jarServer artifacts are under the maven group id io.zipkin
Library artifacts are under the maven group id io.zipkin.zipkin2
Releases are at Sonatype and Maven Central
Snapshots are uploaded to Sonatype after commits to master.
Released versions of zipkin-server are published to Docker Hub as openzipkin/zipkin and GitHub
Container Registry as ghcr.io/openzipkin/zipkin. See docker for details.
Helm charts are available via helm repo add zipkin https://zipkin.io/zipkin-helm.
See zipkin-helm for details.
https://zipkin.io/zipkin contains versioned folders with JavaDocs published on each (non-PR) build, as well as releases.