{kind=link}
{kind=link}
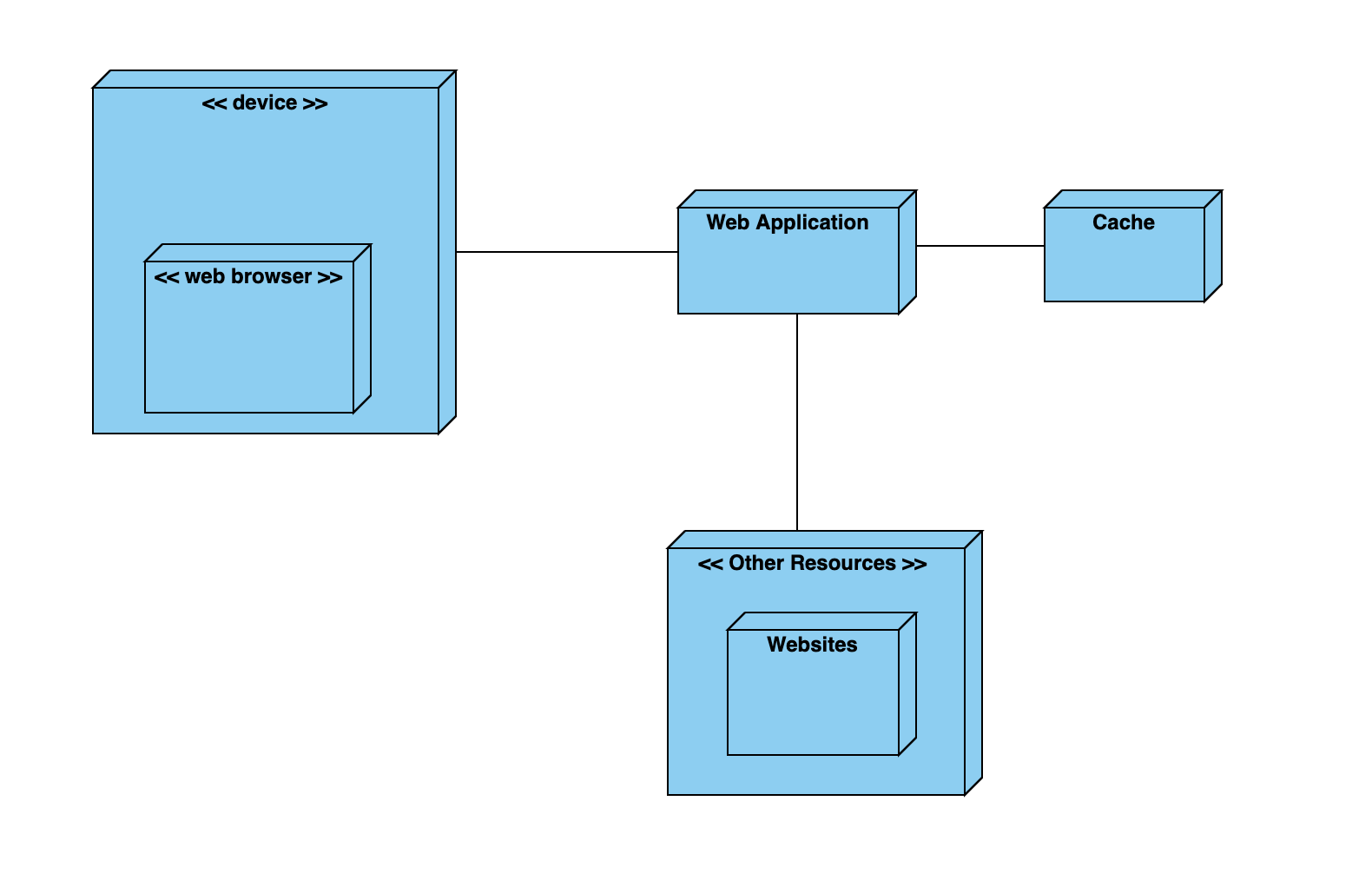
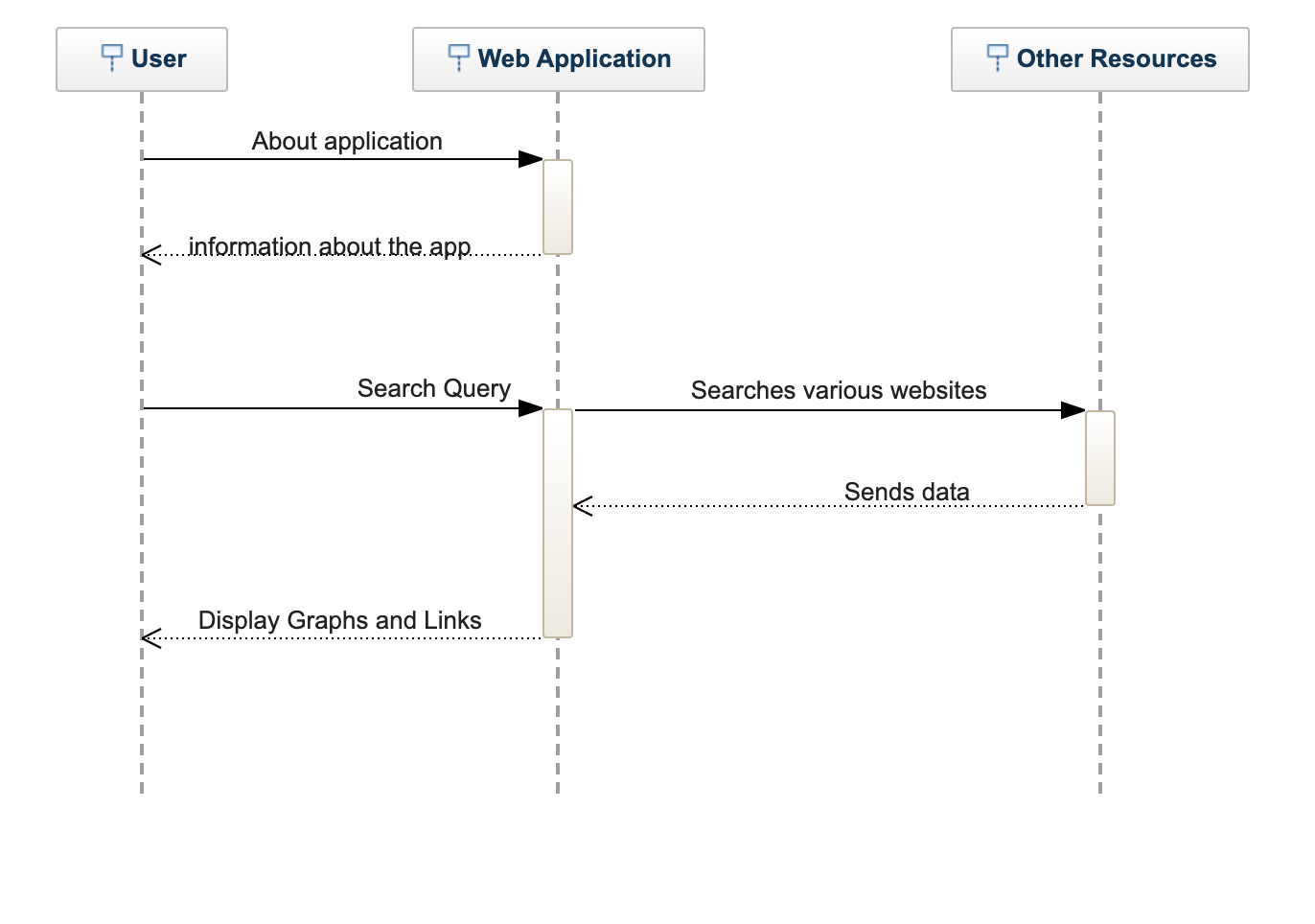
The purpose of this project is to help identify trends in popular culture to assist educators in finding ways to better introduce STEAM concepts to children. Via webscraping and API calls, this project gathers information from Reddit, IMDb, Wikipedia, Steam, YouTube, Twitter, Google Trends, Nasa.gov, Teachengineering.org, and AskDrUniverse.com. This information includes links to relevant popular posts and data regarding the relative popularity of said posts or given query words which are then graphically displayed, as well as links to related learning resources. The application is accessed via a Heroku deployment and includes the necessary web files, but can also be configured to run locally. Generated URL links are stored in a .csv file, and graphs are saved as a .png. Any query word may be used and information is gathered live, though runtime can be near 30 seconds. As such, we have also included a list of suggested topics, as gathered through mining documents pertaining to California's educational curriculum, whose results have already been generated and thus may be accessed more quickly, though are not gathered in realtime and so may become outdated.
- Fork this repository.
- Create a free Heroku account and add a new app.
- Connect your app to your fork using the GitHub option under your app's "Deploy" tab.
- Under your app's "Settings" tab, add the following buildpacks:
heroku/python https://github.com/heroku/heroku-buildpack-google-chrome https://github.com/heroku/heroku-buildpack-chromedriver - Under your app's "Settings" tab, add the following Config Variables:
CHROMEDRIVER_PATH : /app/.chromedriver/bin/chromedriver GOOGLE_CHROME_BIN : /app/.apt/usr/bin/google-chrome - Under "Deploy" press "Deploy Branch".
- Install required dependencies listed in requirements.txt.
pip install -r /path/to/requirements.txt- Note: Due to a bug with the existing twitterscraper library on PyPi, it has been modified and included in the project files. - Install the version of Chromedriver relevant to your operating system: https://chromedriver.chromium.org/
- In "websites_scraper.py", remove line 28
chrome_options.binary_location = os.environ.get("GOOGLE_CHROME_BIN") - In the same file, change line 36 and 79 from
browser = webdriver.Chrome(executable_path = os.environ.get("CHROMEDRIVER_PATH") ,options=chrome_options)tobrowser = webdriver.Chrome(executable_path = PATH\TO\DRIVER ,options=chrome_options), replacing the path with the location of the driver you installed previously. - Use the "app" method in "maindata.py".
All contributions are welcome!
- Pull Requests to this repository
- Furthering the project in your own repository
- Joining Opportunity Hack!