{kind=link}
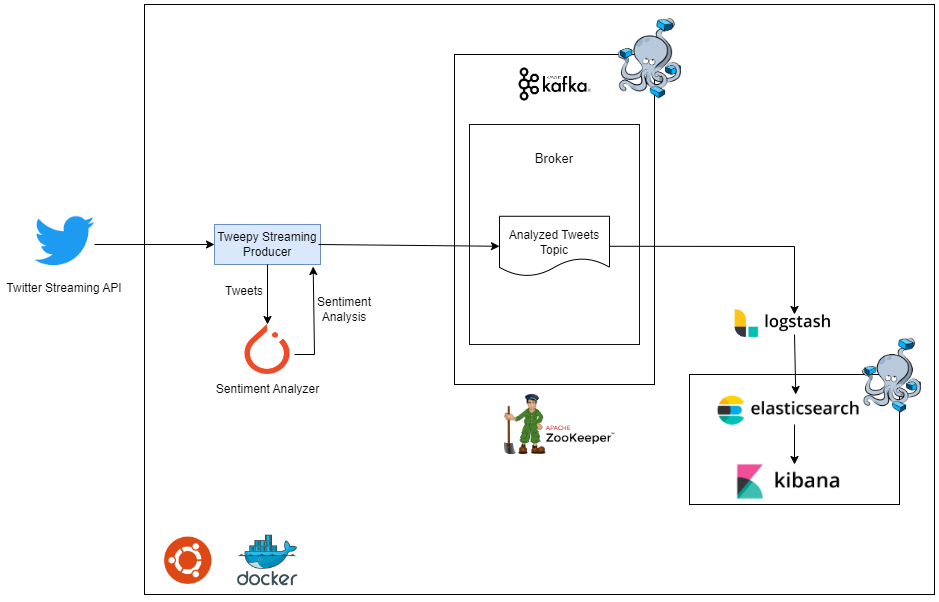
The goal of this project is to extract tweets about various electronic products using the Tweepy Python library. Once the tweets are collected, we apply a pre-trained NLP model called ReBERTa to analyze the sentiment of each tweet. The sentiment analysis results are categorized as negative, neutral, or positive.
The tweets and their corresponding sentiment analysis results are then sent to a Kafka topic. The consumer of the Kafka topic in our case is an ETL tool called Logstash. The role of Logstash is to transform the messages received from the Kafka topic into a JSON format and load the documents into Elasticsearch.
Finally, the data stored in Elasticsearch is visualized on a Kibana dashboard.