In this work, we provide a linguistic based approach to analyze the Brazilian Congress members' discourse on social media. We use a lexicon-based approach to generate features, and provide model explanations using SHAP (Lundberg and Lee, 2017).
We considered different linguistic aspects in our analysis, namely: argumentation, presupposition, modalization, sentiment, valuation, vagueness, and outrage. For each linguistic aspect we introduced the corresponding lexicon for Portuguese, and with Words Mover’s Distance (Kusner et al.,2015) we could expand the size of our lexicon, as demonstrated by (Amorim et al., 2018) and (Caio L.M. Jeronimo, 2019) it is a effective method to work expand lexicons. Our main idea is to employ these lexicons as features to represent declarations posted by the members of the Brazilian Congress, so that we can learn machine learning models to predict the popularity of a tweet.
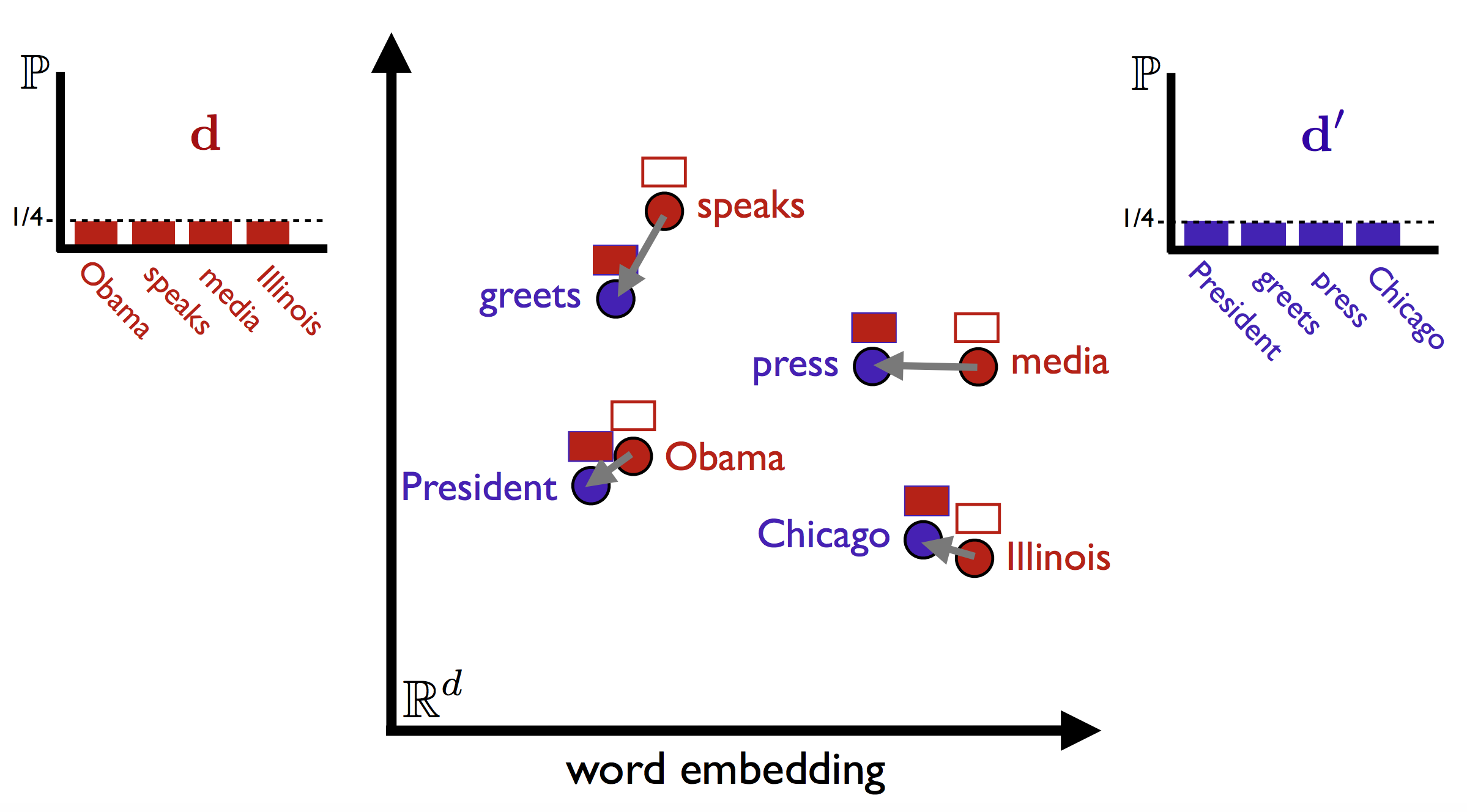
The WMD allow us to access the similarity between two sentences in a meaningful way, even when they have no specific words in common. The main idea behind the algorithm is that it uses word vectors to find the minimum "travel distance" between a declaration and a lexicon.
To investigate model decisions, we use SHAP summary plots, which allows us (i) to summarize the importance of a feature, and (ii) to associate low/high feature values to an increase/decrease in output values, through color-coded violin plots built from all predictions. We will further see that different members of parliament have a different summary plot, which shows different strategies between members to engage the public.
Hidden Topics (Gong et al.,2018)
The Hidden Topics is another document similarity metric designed for texts with varying lengths. This method solves the problem of high correlation between the text length and predicted similarity that the WMD has. The Hidden Topics is also a embedding-based model that compares the texts in a common space of hidden topics vectors, which are used to establish a common ground to capture as much information of the long document and the short document as possible and measure the relevance of each pair, allowing a multi-view generalization of the documents (Gong et al.,2018).
Adapting this model to our Brazilian Congress problem, we use the lexicons as the "long documents", and the Congress memebers' tweets as the "short documents", so the hidden topics model can measure the similarity of each pair of tweet and lexicon and give a score for each pair. In the end, each tweet has a score of similarity for each lexicon they interacted with.
The choice of certain words in discourse defines the discourse of a subject, thereby the bias and intentions can be tracked by lexicons. The theory of argumentation and pragmatics assume implicit markers of positioning in language as clues to the speakers subjectivity. Thus, we developed a list of seven lexicons for Portuguese:
Argumentation: markers of argumentative discourse,including lexical expressions and connectives.
Presupposition: markers that suggest the assumption that something is true.
Modalization: expressions that indicates that the writer exhibits a stance towards its statement.
Sentiment: includes markers that indicate a state of mind, emotion or a sentiment of the speaker.
Valuation: assigns a value to the facts.
Vagueness: includes words and expressions that could indicate vague claims in the discourse.
Outrage: includes markers of insult, offense and indignation.
pip3 install -r requirements.txt
python3 wmd.py --dataset YOUR_DATASET.csv --col TEXT_COLUMN_NAME --emb YOUR_WORD_EMBEDDING --bin 0 --out OUTPUT_FILE.csv
-
--dataset: Dataset in csv format -
--col: Column name containing the text to apply the wmd for feature extraction.- Default :
text
- Default :
-
--emb: Word embedding file loadable via gensim's KeyedVectors. -
--bin: Embedding file is in binary format or not.- Options :
0or1
- Options :
-
--out: Output file name- Default :
wmd.csv
- Default :
Hidden Topics (Hongyu Gong et al.,2018)
python3 main.py --embedding_path skip_s300.txt --input_csv YOUR_DATASET.csv --binary_embedding --is_refine_short --is_refine_long --short_word_limit INTEGER --long_word_limit INTEGER --topic_num INTEGER --out OUTPUT_FILE.csv
-embedding_path : Word embedding file loadable via gensim's KeyedVectors.
-input_csv : Dataset in csv format (text column name should be "text")
-binary_embedding : Embedding file is in binary format
-is_refine_short : Refine short documents using tf-idf
-is_refine_long : Refine long documents using tf-idf
-short_word_limit : Word limit for the short documents
-long_word_limit : Word limit for the long documents
-topic_num : Number of topics to be discovered
-out : Output file name
-
Tweets of the National Congress of Brazil members, 2019-2020
-
Generated wmd from the Tweets of the National Congress of Brazil members
-
Generated hidden topics from the Tweets of the National Congress of Brazil members
E. Amorim, M. Cançado, and A. Veloso. 2018. Automated essay scoring in the presence of biased ratings. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, pages 229–237
Caio L. M. Jeronimo, Claudio E. C. Campelo, Leandro Balby Marinho, Allan Sales, Adriano Veloso, and Roberta Viola. 2019. Computing with subjectivity lexicons.LREC.
S. Lundberg and S. Lee. 2017. A unified approach to interpreting model predictions. In Annual Conference on Neural Information Processing Systems, Neurips, pages 4765–4774.
M. Kusner, Y. Sun, N. Kolkin, and K. Weinberger. 2015. From word embeddings to document distances. In International Conference on Machine Learning, ICML, pages 957–966.
H. Gong, T. Sakakini, S. Bhat, J. Xiong. 2018. Document Similarity for Texts of Varying Lengths via Hidden Topics. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL, pages 2341–2351.