PDF comments not fully supported #288
Comments
|
I would go many extra miles before I blame the Go standard lib. Excellent feedback, thanks 💚 |
|
I am puzzled because I am having a different problem with this file:
Is this intentional? |
|
OK, looks like I am running into the same issue as you are. |
|
I think we must be looking at different files! The "xref" keyword is at 3369 (dec): |
|
not in the checked in version in the safedocs repo: |
|
After playing around with this file (using the mentioned last resort workaround pdfcpu provides to parse a file having a corrupt xref pointer and a patch for comment digestion) I am able to parse it now but it fails validation. 😞 It seems to be using the escape sequence
|
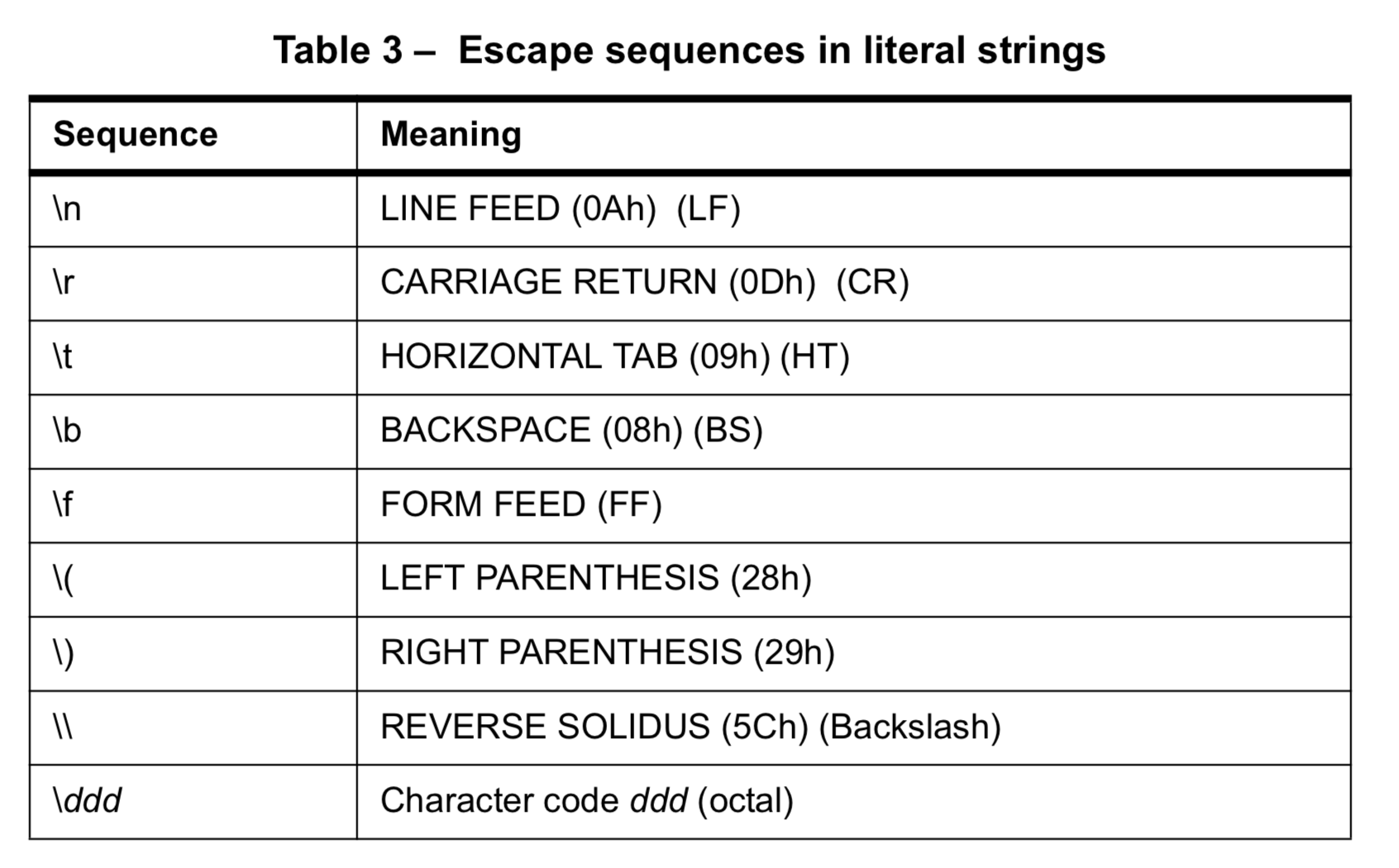
|
Great find! 🥇 I will fix that - thanks. I shouldn't blindly copy'n'paste from the files of others... Re the file in GitHub - I'm definitely looking at a file pulled down from GitHub via GitHub Desktop so it may be a config line ending issue with Git clients. I will try different clients and different platforms. Sigh. |
|
I cloned the repo via the git command line which should be the safest way |
|
OK - fixed after much faffing around. Looks like some different git-aware tools do their own thing in semi-platform dependent ways. Tested on Win10, WSL2-Ubuntu, native Ubuntu and multiple browsers with a total of 9 different git-aware tools via HTTPS and SSH (some tools seem to do different things on add/upload vs download!). Solution that now works for me across everything was to add a .gitattributes file and explicitly state *.pdf are always binary. |
Not all "token delimiter" characters are being correctly supported unless whitespace is additionally used which is not required by any PDF spec. Test file and detailed explanation is available in this Github repo.
I'm no Go expert, but I think this is because the standard Go RTL for strconv.ParseFloat has different lexical rules to PDF.
The text was updated successfully, but these errors were encountered: