To describe the architecture of persona and store configuration files.
bash install.shThe systemd services will be generated: persona-offline, persona-realtime, persona-flume and persona-backend.
And you can use them as service.
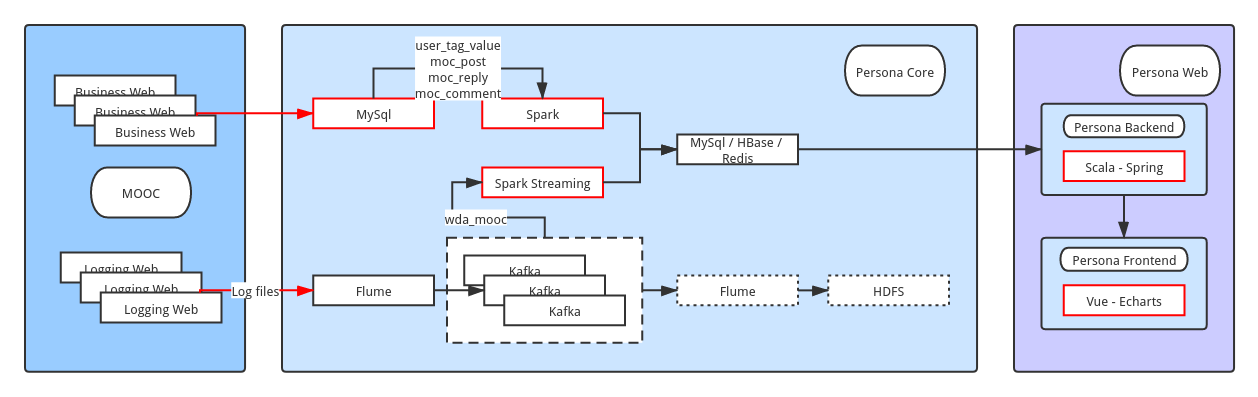
user_tag_value,moc_post,moc_reply,moc_commentcomes from moocMySql.wda_moocmaybe come from moocHDFS.Sparkused for off-line data processing.Spark Streamingused for real-time data processing.Redishas been chosen for data caching.
How to choose
MySql,HBaseandRedis?
-Redis: the data is easy to lose, but fastest.
-HBase: data not lose. Is its deployment easy?
-MySql: too slow.
- How to arrange
persona - mlmodule?