Podcasts are often mastered at fairly different, and even inconsistent levels. This is fairly easy to fix if you know the RMS level of each episode, but it can be resource-intensive and time consuming to read an entire episode (which is often an hour or more of audio) just to calculate the total RMS. The resource consumption problem is compounded by the fact that often podcasts are loaded directly onto phones, which are generally low-power devices.
However, in most cases, mastering problems are consistent throughout a podcast episode - it's rare that the audio levels vary dramatically within a given episode. As such, you only really need to process as much of the episode as it takes to get close to the true RMS of the entire episode. If you aren't concerned about intermittent clipping, this can be done using a very small subset of the episode.
This repository explores how to optimally sample the episode so as to get as close as possible to the true RMS in the smallest number of samples, using various different sampling techniques.
The demo uses the following podcasts, of various mastering qualities:1
- Serial, Season 1 Episode 7: The Opposite of Prosecution (
serial-episode-07.mp3, 32m 34s) - Seattle Library Podcast - October 28, 2014: Polio Then and Now: From Salk’s Game-Changing Vaccine to Today’s Resurgence (
seattle-library-podcast-2014-10-28.mp3, 1h 17m 02s) - Spy Museum Podcast - Author Debriefing: Good Hunting, An American Spymaster's Story (
spy-museum-podcast-2014-11-07.mp3, 1h 07m 42s) - Federalist Society Events Audio - Defining Regulatory Crimes (
federalist-society-events-2014-06-11, 1h 19m 06s)
To get an estimate of how many samples it takes to get close to the true value, I can calculate the true loudness of the file to start with, then try reading it out until I get close enough to the true value. Retrieving samples from the start, middle and end of each file, until I get to within 0.2 dB of the true value gives me:
>>> python run-demo.py -ds -sh -uc -uc -ms 100000000
serial-episode-07.mp3
True dBFS: -19.037004
Start number of samples: 23846 (-19.236950 dB)
Middle number of samples: 1187 (-18.840281 dB)
End number of samples: 131014 (-19.236404 dB)
seattle-library-podcast-2014-10-28.mp3
True dBFS: -34.131281
Start number of samples: 10215 (-34.331054 dB)
Middle number of samples: 86860 (-33.931294 dB)
End number of samples: 248471 (-34.331107 dB)
spy-museum-podcast-2014-11-07.mp3
True dBFS: -21.969535
Start number of samples: 7350369 (-22.169532 dB)
Middle number of samples: 78544 (-22.167233 dB)
End number of samples: 3105373 (-22.169480 dB)
federalist-society-events-2014-06-11.mp3
True dBFS: -25.349533
Start number of samples: 26262143 (-25.549532 dB)
Middle number of samples: 96944106 (-25.549533 dB)
End number of samples: 78138 (-25.545350 dB)
It seems like in many cases, if you're going to pick a place and start sampling, the middle is the best place to start - but the Federalist Society event podcast is a notable exception to this - with the middle being the absolute worst place to start. If you are willing to accept a bigger error factor, the "start" line gets close pretty quickly, but the "middle" has some long quiet period that will certainly take a while to average out:
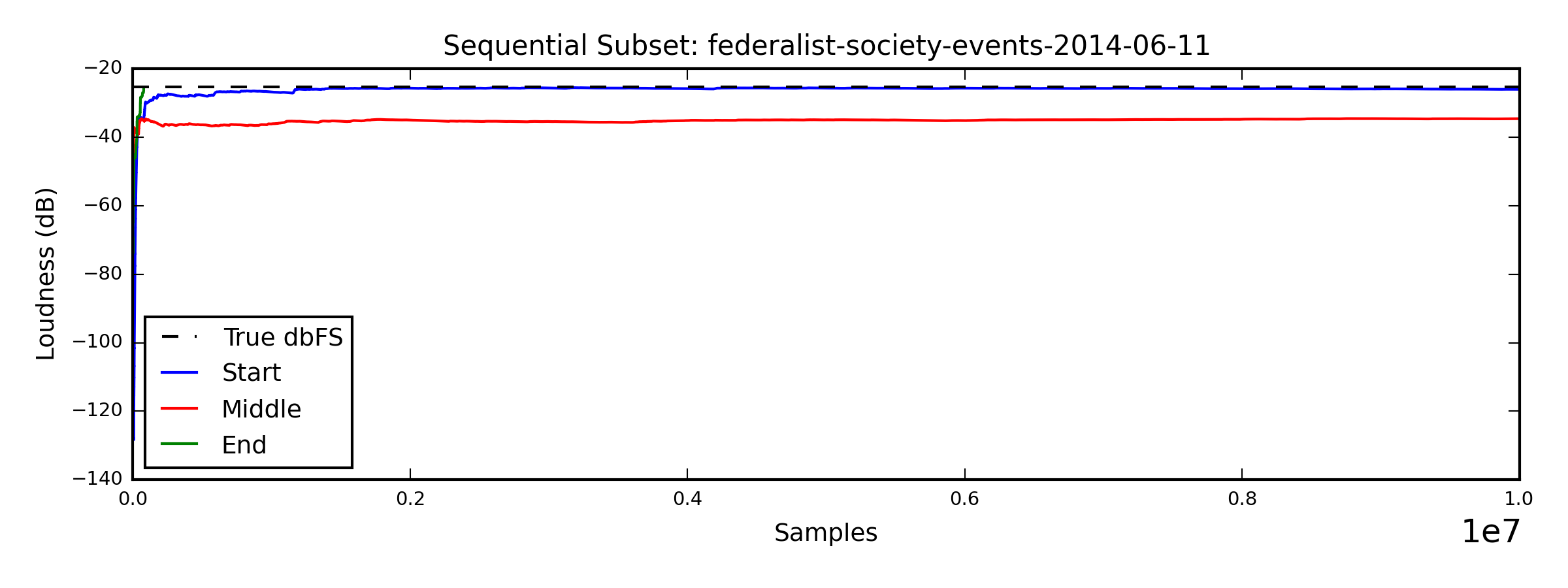
In any case, the worst case scenario here (the Federalist Society podcast, starting in the middle), still only takes 36 minutes of audio to get us the data we need - which isn't great, but it's still less than 50% of the total duration of the episode, so it's a start.
Rather than choosing samples sequentially, if we choose them at random, it's very unlikely that you'll take too many samples from any given quiet or loud region, so you should be able to get close to the true value much more quickly. Repeating the above test using random subsampling (and because it's not the same results every time, repeating that test 150 times), you get:
>>> python run-demo.py -dr -rr 150 -uc --min-samples 100
serial-episode-07.mp3
True dBFS: -19.037004
Final dBFS: -18.857259
Mean number of samples: 534.286667 (24.230688 ms)
Min number of samples: 101.000000 (4.580499 ms)
Max number of samples: 7666.000000 (347.664399 ms)
seattle-library-podcast-2014-10-28.mp3
True dBFS: -34.131281
Final dBFS: -33.936553
Mean number of samples: 1517.386667 (34.407861 ms)
Min number of samples: 101.000000 (2.290249 ms)
Max number of samples: 66808.000000 (1514.920635 ms)
spy-museum-podcast-2014-11-07.mp3
True dBFS: -21.969535
Final dBFS: -21.773998
Mean number of samples: 1000.406667 (22.684958 ms)
Min number of samples: 101.000000 (2.290249 ms)
Max number of samples: 31924.000000 (723.900227 ms)
federalist-society-events-2014-06-11.mp3
True dBFS: -25.349533
Final dBFS: -25.152401
Mean number of samples: 2160.993333 (49.002116 ms)
Min number of samples: 101.000000 (2.290249 ms)
Max number of samples: 38802.000000 (879.863946 ms)
So it looks like the absolute worst case performance here is about 1.5 seconds - considerably less than the 36 minutes from the sequential test! Of course, we can't assume that we know the true value of the loudness, since that's what we're trying to measure, so we have a question of when to stop taking random samples. For the moment, we can sidestep that problem by just choosing a fixed duration worth of random samples and seeing how close that gets us to the true value. Sampling 2 seconds (44,000 or 88,000 samples) worth of audio from each of these files 150 times gives the following results:
>>> python run-demo.py -dr -rr 150 -d 2.0
serial-episode-07.mp3
True dBFS: -19.037004
Mean dBFS: -19.040694 (Error: 0.003690)
Min dBFS: -19.162484 (Error: 0.125480)
Max dBFS: -18.903390 (Error: 0.133614)
Standard Deviation: 0.051996
seattle-library-podcast-2014-10-28.mp3
True dBFS: -34.131281
Mean dBFS: -34.115192 (Error: 0.016089)
Min dBFS: -34.311679 (Error: 0.180398)
Max dBFS: -33.937149 (Error: 0.194132)
Standard Deviation: 0.074995
spy-museum-podcast-2014-11-07.mp3
True dBFS: -21.969535
Mean dBFS: -21.961811 (Error: 0.007724)
Min dBFS: -22.102569 (Error: 0.133034)
Max dBFS: -21.791989 (Error: 0.177546)
Standard Deviation: 0.053758
federalist-society-events-2014-06-11.mp3
True dBFS: -25.349533
Mean dBFS: -25.344582 (Error: 0.004951)
Min dBFS: -25.604302 (Error: 0.254768)
Max dBFS: -25.089123 (Error: 0.260410)
Standard Deviation: 0.087513
Using mp3Gain on these same files and setting the target "normal" volume to be the value at which Serial is mastered, mp3Gain recommends a volume boost of 15.1 dB, 3 dB and 6 dB, respectively - almost exactly what this script would recommend. As you can see, the most naive method of random sampling, using only 0.04-0.1% of the total length of the file to ascertain the overall volume level with enough accuracy to significantly improve the quality of one's listening experience!