this is a work in progress.
supervised learning with:
- stochastic backpropagation
- cross validation
- k-fold cross-validation
see cross-validation.sh
phil@Eris:~/neural-network-light$ ./cross-validation.sh
[1418301930132 DataLoader main] loaded 150 training instances in 6ms.
[1418301930133 Data main] splitting data into training/testing subsets
[1418301930134 ANN main] initialising network with structure: [4, 10, 3]
[1418301930241 Train main] training complete. best epoch = 1000 training mse = 0.17841 testing mse = 0.35683 testing ae = 0.02 min = 0.00 max = 0.09
[1418301930241 Train main] training took 107ms.
[1418301930242 Report main] dumping errors to: reporter/model/errors.csv
[1418301930377 Report main] wrote data in 135ms
graph in reporter/model/error.png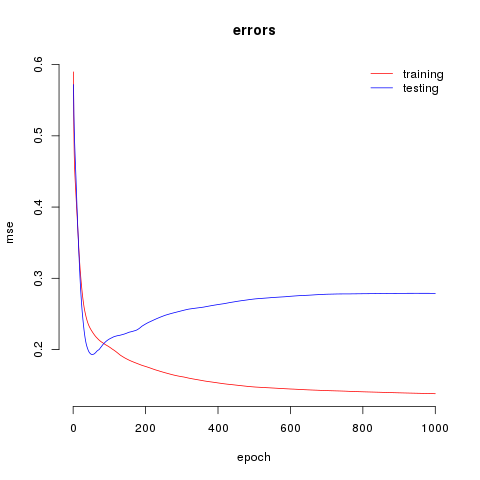
--file=<dataset.csv> location of dataset
--output_nodes=<#> number of network output nodes
--holdback=<0:1> ratio of data to holdback for test set
--k=<0:n> number of k-folds k<=1 disable. max=dataset_len
--min_weight=<r> min weight for random weight initialisation
--max_weight=<r> max weight for random weight initialisation
--learning_rate=<r> learning rate
--momentum=<r> momentum term
--epochs=<n> number of training epochs
--model_output=<dir> save learned weights + reports to dir
--hidden_nodes=<n1,n2..,N> number of _hidden_ nodes in each layer n
./train.sh --file=some-data.csv --output_nodes=3 --holdback=0.2 --k=0 \
--min_weight=-0.5 --max_weight=0.5 --learning_rate=0.1 \
--momentum=0.25 --epochs=1000 --model_output=/tmp \
--hidden_nodes=3,2Will train a neural network on some data. 20% of the data will be reserved for a test validation subset; no k-folding will be performed. the network structure will be:
(i1)
\ /> (l1,1)\ /> (ol,1)
(i2)\\ // \\ /> (l2,1) /
X---> (l1,2)--X X--> (ol,2)
(i3)// \\ // \> (l2,2) \
/ \> (l1,3)/ \> (ol,3)
(i4)
^--- output layer: 3 neurons
^-------------- layer 2: 2 neurons
^-------------------------- layer 2: 3 neurons
^-------------------------------------- input layer: 4 nodes
Where each layer is fully interconnected. Note that the number of nodes in the input layer, and neurons in the output layer are automatically determined by the number of columns in the training data: in this case, there are 4 input features (first 4 columns) and 3 output classes (last 3 columns). The number of output neurons is determined by the output_nodes flag.
When using k-folding (--k > 0) and (--holdback > 0), training errors are stored in the form errors_K.csv in the output directory specified with the --model_output parameter.
In addition, the network with the lowest RMSE over the validation subset in each k-fold is persisted to the model output directory in the form of weights_K.bin. It is then possible, for example, to later use each of the k_models in an ensemble, or to test against an independent test validation set (one that has not been used at all in training).
At the end of training, the trainer outputs some summary statistics which can be used when building different network models. For example, the trainer will output the epoch before overfitting started on the validation set along with the RMSE validation error for each k-fold.
This information could be used to determine a "good" number of hidden units in the first hidden layer by checking the average generalisation accuracy for different numbers of hidden units.
As an example, the following will perform k-fold cross validation (k=8) with 20% validation subsets on 10 different neural network structures increasing in complexity from 1 hidden node, up until 10 hidden nodes. The results are stored in /tmp/search.csv in the form of: #hidden_units, best_testing_epoch, best_testing_RMSE. The lowest average best_testing_RMSE could then be used as an indication of a good trainable network topology.
for((i=1;i<=10;i++)); do
./train.sh --file=/tmp/train_data.csv \
--output_nodes=1 \
--holdback=0.2 \
--k=8 \
--min_weight=-0.1 \
--max_weight=0.1 \
--learning_rate=0.25 \
--momentum=0.4 \
--epochs=5000 \
--model_output=/tmp \
--hidden_nodes=$i \
|grep K-Fold |awk -v ii=$i '{print ii "," $9 "," $17}' ;done >/tmp/search.csv
doneR
x <- read.csv("/tmp/search.csv", header=F)
print(paste("optimal hidden nodes =", which.min(tapply(x[, 3], x[, 1], mean))))