Hot day occurrence
This is a diagnostic for assessing the impact of soil moisture on the generation of daily near-surface air temperature extremes in Asia during the East Asian Summer Monsoon months of June to August (JJA). We define hot days to be JJA days with temperatures warmer than the 90th percentile of all JJA days in all years under analysis, from which we calculate the number of hot days (NHD) per calendar year. The NHD is then regressed onto antecedent precipitation over a set of accumulation periods: JJA (concurrent), May (one-month accumulation), Apr-May (two-month accumulation), and Mar-May (three-month accumulation). Regressions are calculated globally for each model grid box and for three regions of Asia: north-east China (110 to 120°E, 30 to 40°N), Tibet (80 to 95°E, 29 to 37°N), and south-east Asia (100 to 110°E, 10 to 20°N).
Running this recipe will output for each dataset in the recipe (i) netCDF files of annual NHD and seasonal antecedent mean precipitation, and (ii) precipitation vs NHD maps of correlation coefficient for each season and scatter plots for each of the three regions:
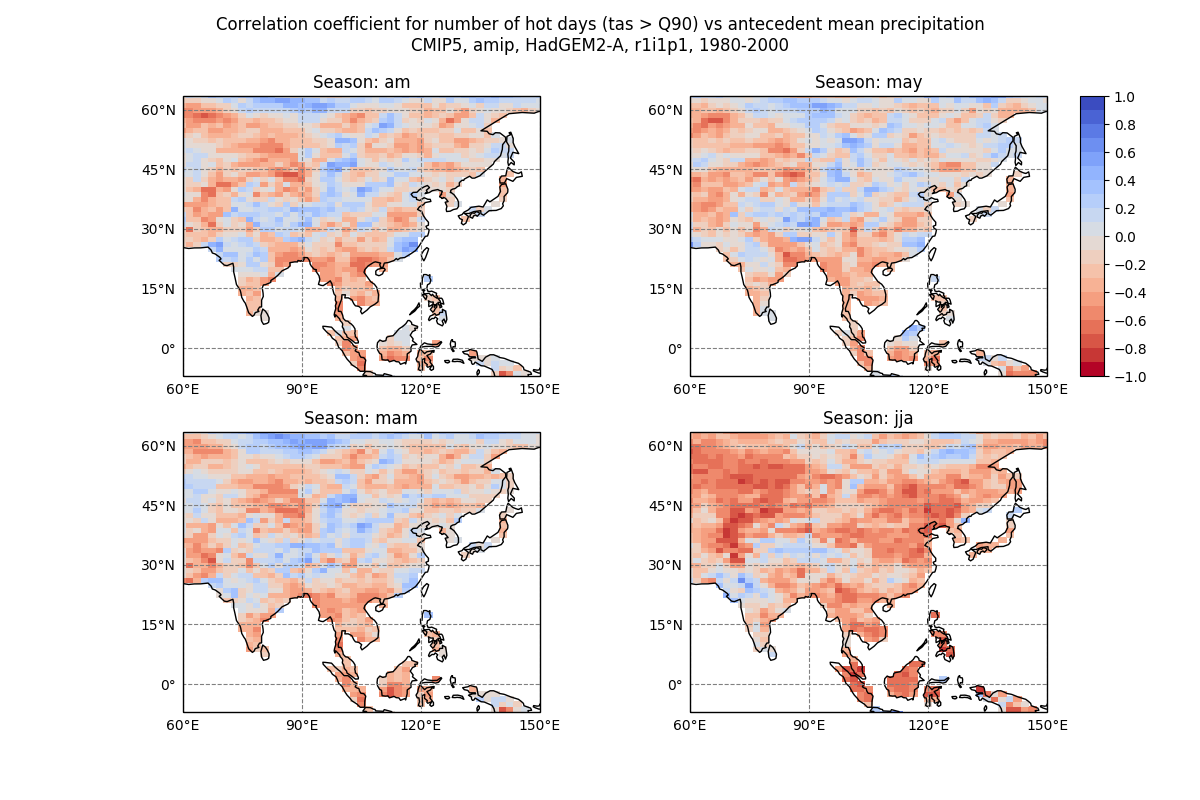

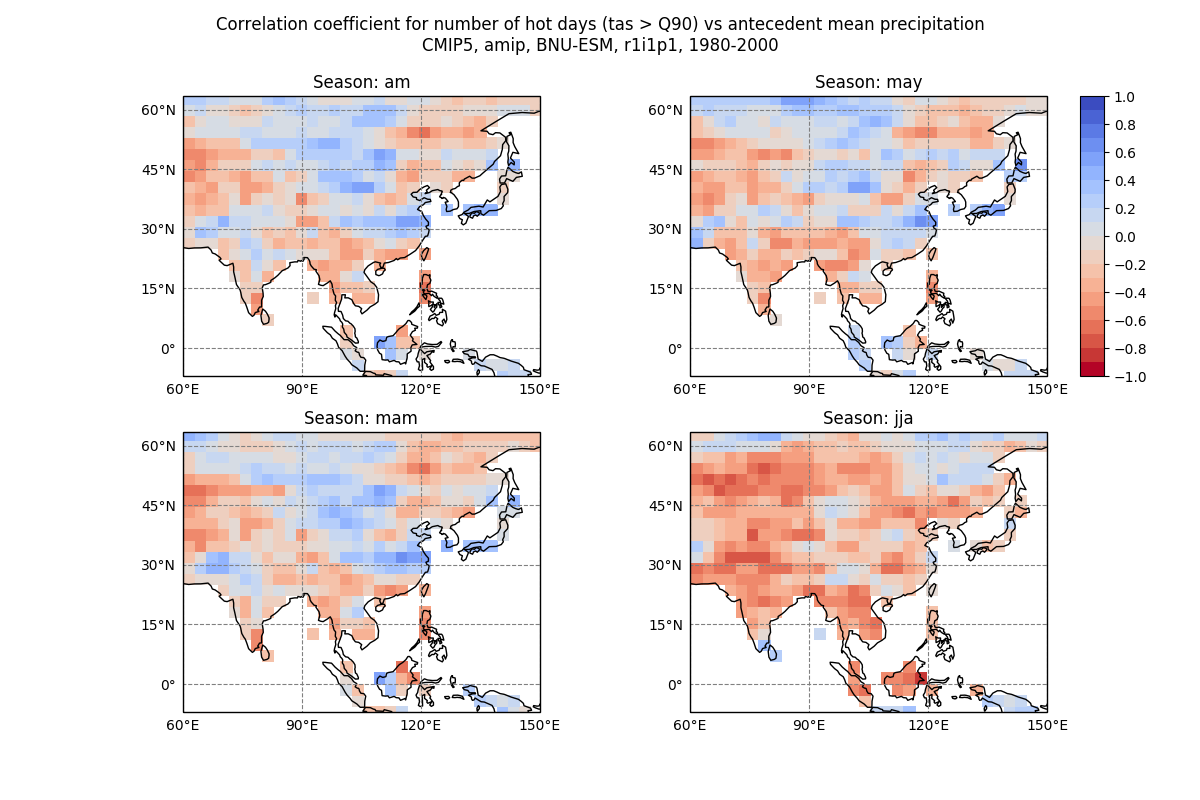
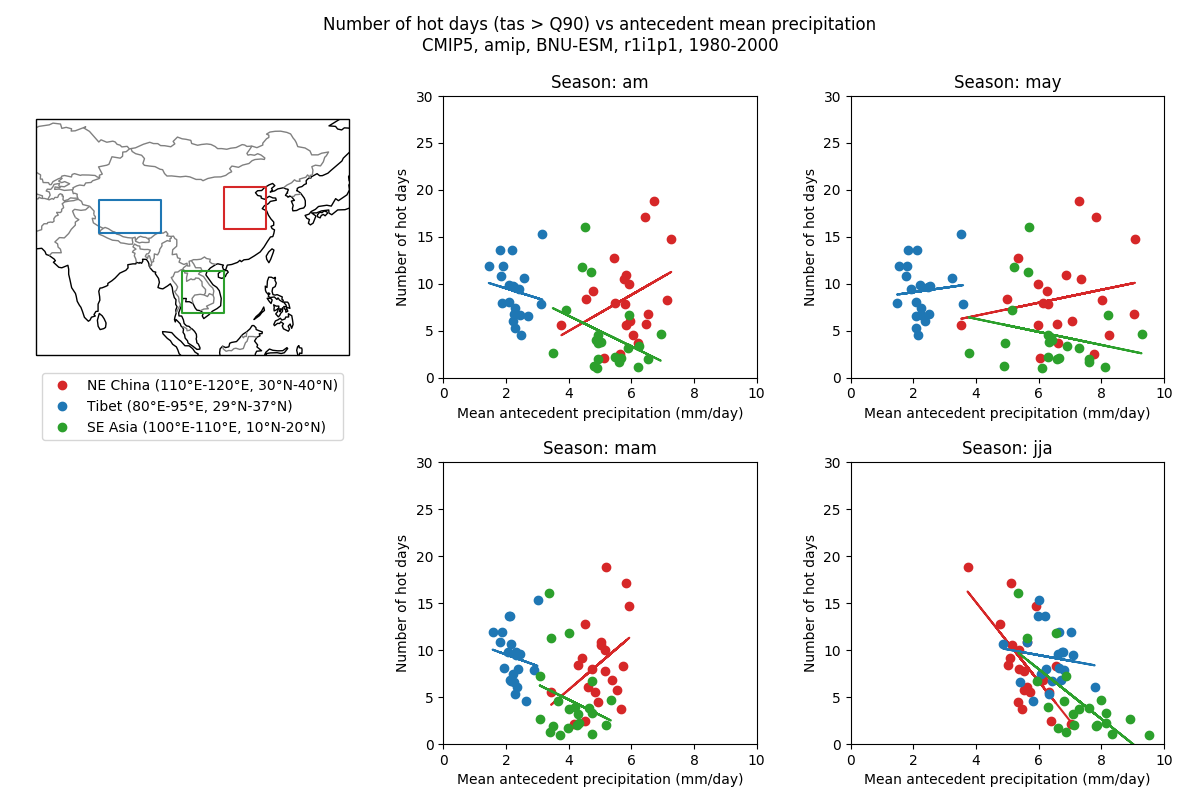
The recipe for this diagnostic is porcpy/recipes/recipe_hot_days.yml. It requires the following CMOR variables at a day frequency:
-
pr: Preipitation flux (kg m-2 s-1) -
tas: Near-Surface Air Temperature (K)
All calculations and output files are made on the native grid of the respective model; no spatial interpolation is performed on the data. By default the recipe defines a hot day using the 90th percentile of daily temperature, but this can be in the recipe via the quantile setting to the tas variable. Similarly, the analysis period is chosen by setting the start_year and end_year of the tas variable, and both years are included in the analysis
tas: &var_opt
start_year: 1980
end_year: 1983
quantile: 0.9Input models are specified by lines in the datasets section of the recipe:
- {dataset: CNRM-CM5, project: CMIP5, exp: amip, ensemble: r1i1p1}
- {dataset: HadGEM2-A, project: CMIP5, exp: amip, ensemble: r1i1p1}ESMValTool provides a convenient preprocessor front-end to this diagnostic, but users can invoke it directly from their own code by calling driver routines in porcpy/diag_scripts/hot_days.py. NetCDF output files of NHD are generated by calling hot_days.calc_hot_days():
def calc_hot_days(tas_filename, tas_varname, nhd_filename, quantile=0.9):
"""Driver routine for calculating the number of hot JJA days each year.
Hot days are defined relative to the percentile 100*quantile of all JJA
days in the input dataset.
Parameters
----------
tas_filename : str
Name of input netCDF file containing daily air temperature time series.
tas_varname : str
NetCDF variable name for input air temperature data.
nhd_filename : str
Name of output netCDF file containing annual time series of the number
of hot JJA days.
quantile : float, optional
Quantile of daily air temperature above which days are considered hot.
Values in the range (0-1).
"""NetCDF output files of seasonal precipitation are generated by calling hot_days.calc_acc_pr():
def calc_acc_pr(pr_filename, pr_varname, prm_filename, season):
"""Driver routine for calculating the mean precipitation rate in a season.
Parameters
----------
pr_filename : str
Name of input netCDF file containing daily precipitation rate time
series (kg m-2 s-1).
pr_varname : str
NetCDF variable name for input precipitation rate.
prm_filename : str
Name of output netCDF file containing annual time series of
precipitation rate for the requested season.
season : int or iterable of ints
Month numbers over which to calculate the seasonal mean. Values in the
range [1-12].
"""Standard scatter plots of antecedent precipitation versus NHD are generated by calling hot_days.plot_scatter():
def plot_scatter(file_in_nhd, files_in_prm, file_out_plot, title=None):
"""Driver routine for making standard precip vs hot day scatter plots.
Parameters
----------
file_in_nhd : str
Name of input netCDF file containing annual time series of number of
hot JJA days.
files_in_prm : dict
Dictionary of season_name:filename pairs for input netCDF files
containing seasonal mean precipitation rate.
file_out_plot : str
Name of output image file. Any existing file will be clobbered.
title : str, optional
Title to add to the overall multi-plot figure.
"""