Use DictionaryBlocks for Unnest Operator #901
Conversation
|
Thank you for your pull request and welcome to our community. We require contributors to sign our Contributor License Agreement, and we don't seem to have you on file. In order for us to review and merge your code, please submit the signed CLA to cla@prestosql.io. For more information, see https://github.com/prestosql/cla. |
|
Hi @phd3 Thanks for contribution! Do you have some benchmarking numbers? |
There was a problem hiding this comment.
Thanks Pratham! In addition to timing benchmarks, would you share some memory usage comparisons? That's what originally got us interested in this. I assume at least that the particularly bad query we had, which used to fail now passes. Can you get samples of the sizes of Pages returned from the UnnestOperator of that query before and after this change?
I haven't gone through everything yet, but my high level take away is that the interaction between Unnesters and the BlockProducerFromSource is complicated and can be simplified by separating concerns
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
| * See the License for the specific language governing permissions and | ||
| * limitations under the License. | ||
| */ | ||
| package io.prestosql.operator.unnest; |
There was a problem hiding this comment.
Do you have the package move commit separate? If it's easy, it'd be nice to have this as two commits: 1 for the move and 1 for the logic changes. That will help git recognize that you've moved the file and it's not a brand new file, which in turn makes diff and blame output a bit more sensible.
presto-main/src/main/java/io/prestosql/operator/unnest/BlockProducerFromSource.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/BlockProducerFromSource.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/BlockProducerFromSource.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/BlockProducerFromSource.java
Outdated
Show resolved
Hide resolved
|
@sopel39 I saw that there are no benchmarks for UnnestOperator yet, I am looking into how we can add that. |
|
@cla-bot check |
|
The cla-bot has been summoned, and re-checked this pull request! |
|
Some benchmark results using the code in #952 . @sopel39 @wagnermarkd This addresses a couple of your comments. For all plots below, Comparison 1. Performance comparison with a single unnest channel
This is the case with the maximum gain in terms of CPU. We get away without copying blocks at all. Comparison 2. Performance comparison with two unnest channels
We have to copy blocks in case of misalignments (possible due to two unnest channels). But if we have nulls in our element blocks, using Note that the second unnest channel doesn't have any nulls, and will always end up copying for that channel in this example. The memory consumption would reduce if it did have some nulls.
When there is misalignment and there are no null elements, we end up copying blocks. In these cases, we may have to do more work because we first create dictionary ids, and then may have to switch to copied blocks. Memory AllocationsUsing a The newly allocated memory (that is referenced in output blocks) while processing one iteration in The values shown here are just for getting a handle on the data scale.
|
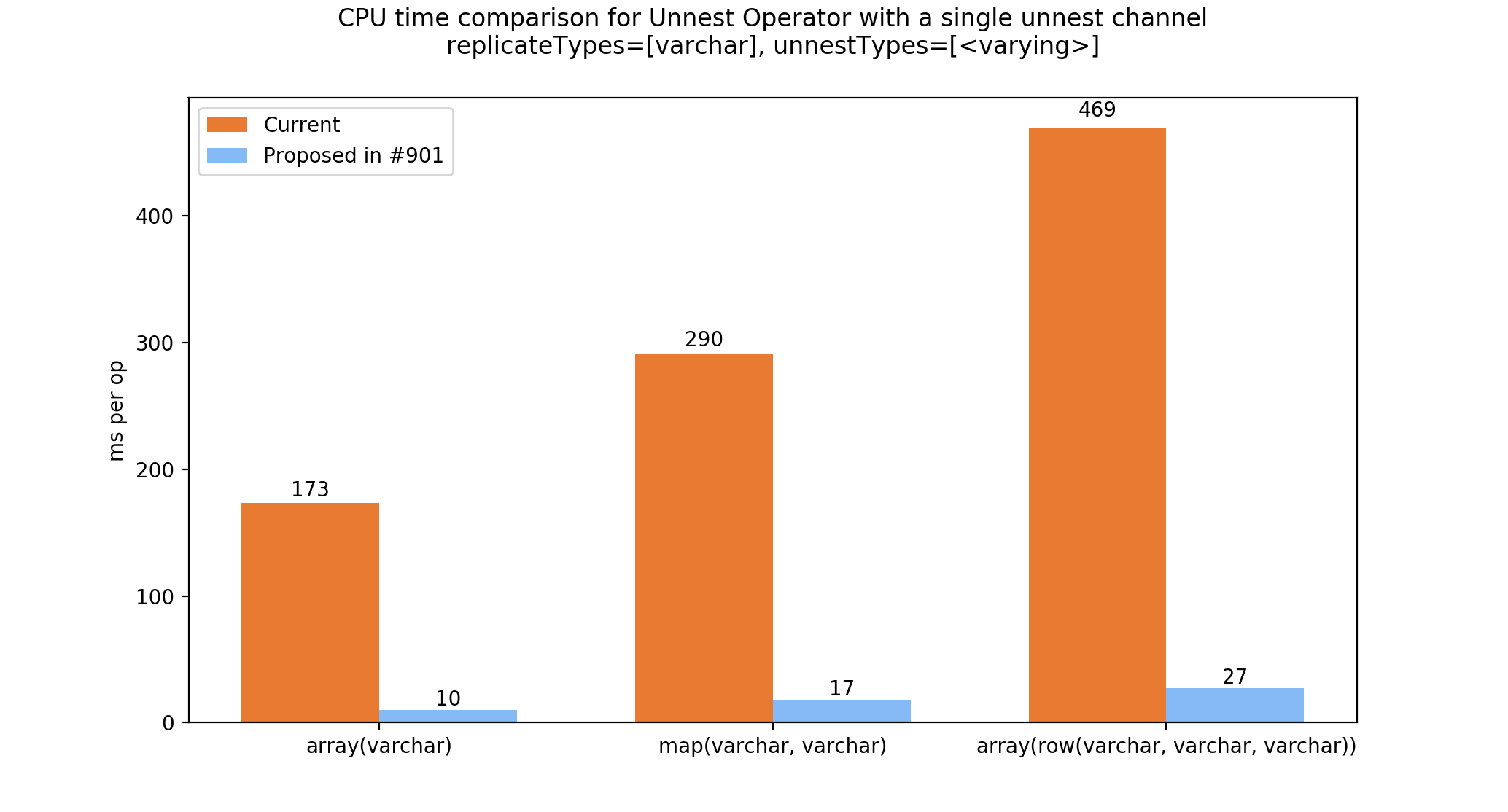

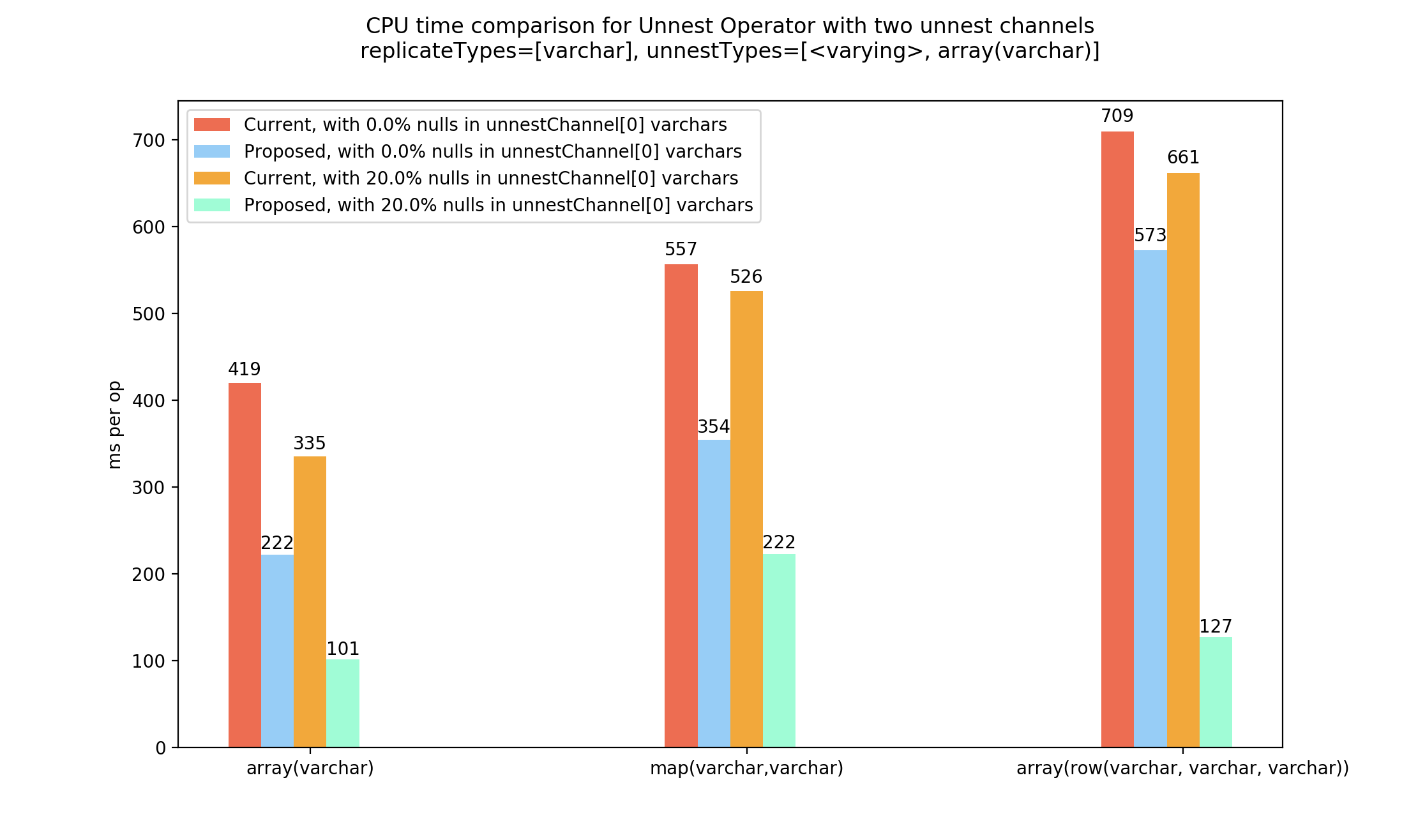
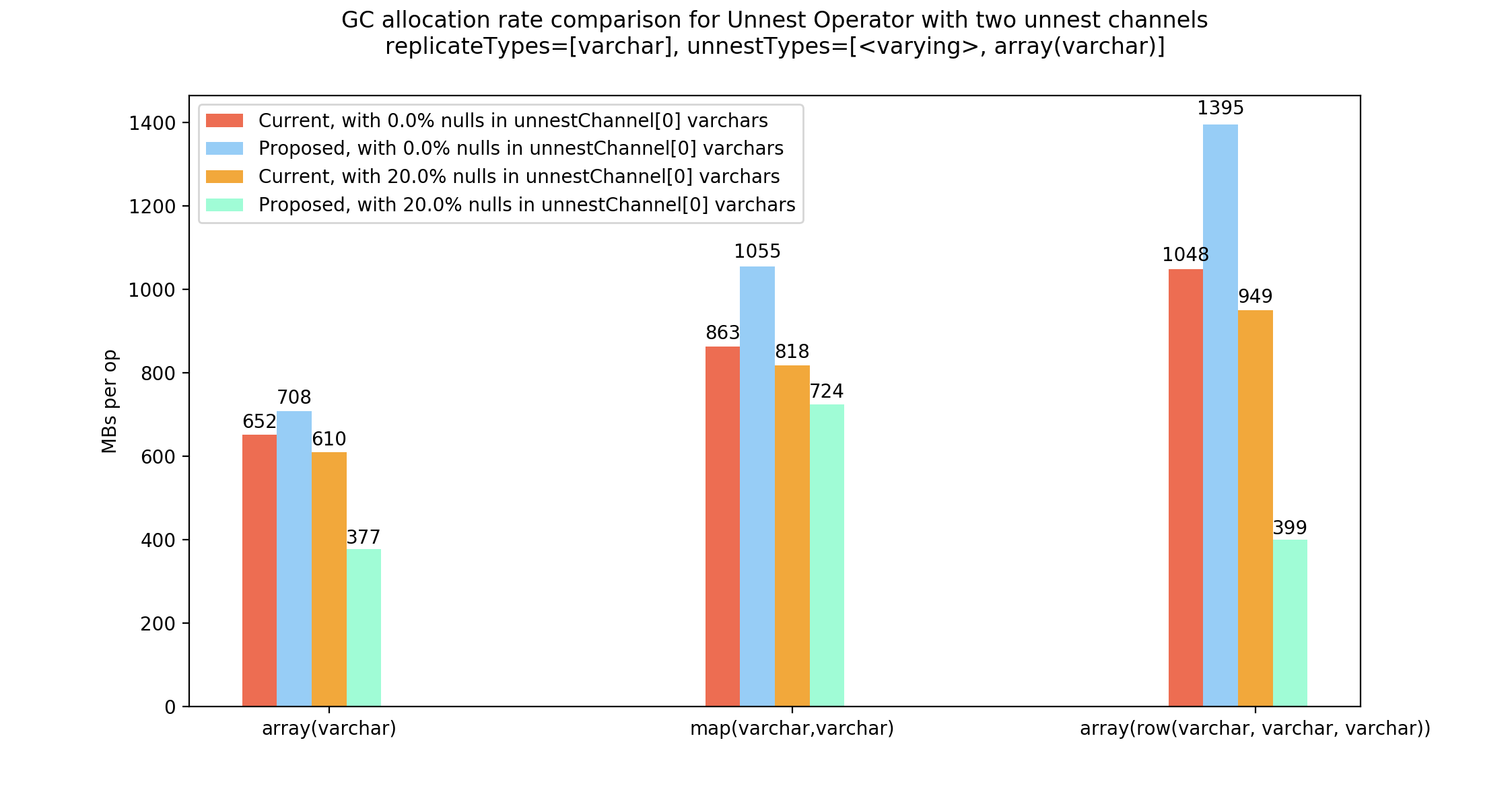
There was a problem hiding this comment.
Looking good! Most of my inline comments are code style nits, or readability suggestions.
I do have one higher level concern about the size of created pages. It looks like the UnnestOperator is exclusively using PageBuilderStatus to limit page sizes. This limits page based on bytes, but since most of the time you will have dictionary blocks, the status is not used. When we need to transition from dictionary to copy, we need to copy all of the data to the block builder, and this could be very large. Limiting the number of rows in the output page is a good first step to limit this issue. If it becomes a further problem we could try to estimate the size of the copy (doing a perfect count is to expensive), or we could just figure out how to get a null into a dictionary block without copy.
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/BlockProducerFromSource.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/io/prestosql/operator/unnest/TestBlockProducerFromSource.java
Outdated
Show resolved
Hide resolved
| producer.appendElementFromSource(0); | ||
| producer.appendNull(); | ||
| block = producer.buildOutputAndFlush(); | ||
| assertTrue((block instanceof DictionaryBlock) ^ (nullIndex == -1)); |
There was a problem hiding this comment.
Use logical operators || instead of bit operators ^ for boolean expressions.
There was a problem hiding this comment.
I tried looking into the documentation, and found that ^ is overloaded for boolean operands, and evaluates as a logical XOR: https://docs.oracle.com/javase/specs/jls/se12/html/jls-15.html#jls-15.22.2 Do you still recommend using || and && for readability?
There was a problem hiding this comment.
Yes. The bitwise operators have unexpected behavior like they don't short circuit.
presto-main/src/test/java/io/prestosql/operator/unnest/TestUnnesterUtil.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/io/prestosql/operator/unnest/TestUnnesterUtil.java
Outdated
Show resolved
Hide resolved
|
@wagnermarkd The updated PR contains 3 commits: package move, implementation, addressing all other feedback. Splitting the @dain Thanks for the meticulous review and tips on better code styling and readability. The updated PR has your suggestions incorporated as extensively as I could. We discussed your concern regarding block sizes on slack, adding the gist here for reference: The while loop in |
There was a problem hiding this comment.
Looking good. Just a few final comments.
- I think we should make make all of the classes in the new package "package protected" except for the operator, since they shouldn't be needed out side of this package.
- Let's remove use usage of '^' in boolean expressions.
- There is some minor comments on readability and formatting.
presto-main/src/main/java/io/prestosql/operator/unnest/ReplicatedBlockBuilder.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/ReplicatedBlockBuilder.java
Outdated
Show resolved
Hide resolved
| checkState(source != null, "source is null"); | ||
| checkElementIndex(index, source.getPositionCount()); | ||
|
|
||
| for (int i = 0; i < count; i++) { |
There was a problem hiding this comment.
If you want (this is not necessary), you could simplify this code by growing the array before the loop, and then using Arrays.fill(ids, positionCount, positionCount + count, index)
There was a problem hiding this comment.
I implemented this:
if (positionCount + count >= ids.length) {
// Grow capacity
int newSize = Math.max(calculateNewArraySize(ids.length), positionCount + count);
ids = Arrays.copyOf(ids, newSize);
}
There is an edge case if positionCount + count is greater than UnnestOperatorBlockUtil.MAX_ARRAY_SIZE (or overflows). I don't expect it to be common though, since it would require a trillion elements in the block, hence ~billions in a row (and will probably fail before it comes to this). Do you think we still need to sanity-check it?
There was a problem hiding this comment.
In this case it would overflow to negative, and you would get only the result of calculateNewArraySize(ids.length). If that was not big enough, you would get an error when calling array fill. Anyway, I don' think this is worth changing here. In the future, you can use addExact instead of + to cause an exception to be thrown on overflow.
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestBlockBuilder.java
Outdated
Show resolved
Hide resolved
presto-main/src/main/java/io/prestosql/operator/unnest/UnnestOperator.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/io/prestosql/operator/unnest/TestArrayOfRowsUnnester.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/io/prestosql/operator/unnest/TestArrayUnnester.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/io/prestosql/operator/unnest/TestArrayUnnester.java
Outdated
Show resolved
Hide resolved
presto-main/src/test/java/io/prestosql/operator/unnest/TestMapUnnester.java
Outdated
Show resolved
Hide resolved
| producer.appendElementFromSource(0); | ||
| producer.appendNull(); | ||
| block = producer.buildOutputAndFlush(); | ||
| assertTrue((block instanceof DictionaryBlock) ^ (nullIndex == -1)); |
There was a problem hiding this comment.
Yes. The bitwise operators have unexpected behavior like they don't short circuit.
|
Update 2: See below
|
|
I got the following errors using b6923ed49e. I don't know the exact data which caused this problem. Contact me if you can't reproduce the problem. Issue 1: Issue 2: |
|
@oneonestar Thanks for letting me know, I will look into it and get back to you. |
|
With the help of debug information from @oneonestar, I was able to reproduce both the errors. The issue seems to be arising because of the offset calculation in I've included a commit in updated PR that contains tests for reproducing the issue (that can be dropped before the check-in). These tests succeed with the offset adjustment and fail otherwise. @oneonestar Thanks for bringing this up. It would be great if you can verify the changes on your test data. @dain I don't know if there was a reason behind keeping the offsets referring to the original elements block. please let me know if you can think of any potential problems with this approach. |
Cherry-pick of trinodb/trino#901 (trinodb/trino#901) Co-authored-by: Ajay George <ajaygeorge@fb.com>
Cherry-pick of trinodb/trino#901 (trinodb/trino#901) Co-authored-by: Ajay George <ajaygeorge@fb.com>
Cherry-pick of trinodb/trino#901 (trinodb/trino#901) Co-authored-by: Ajay George <ajaygeorge@fb.com>
Cherry-pick of trinodb/trino#901 (trinodb/trino#901) Co-authored-by: Ajay George <ajaygeorge@fb.com>
Cherry-pick of trinodb/trino#901 (trinodb/trino#901) Co-authored-by: Ajay George <ajaygeorge@fb.com>
Cherry-pick of trinodb/trino#901 (trinodb/trino#901) Co-authored-by: Ajay George <ajaygeorge@fb.com>
Following the discussion in #563 , this PR proposes a new design for Unnest Operator.
The key parts of the new design are as follows:
1. Avoid copying by using a
DictionaryBlock, whenever possible.The main drawback of current implementation is copying of data, both in replicate channels and unnest channels. The solution to this is using a
DictionaryBlockfor both the cases. Some form of the input block is used as the dictionary in outputDictionaryblock.Output for replicate channels often contains the same elements repeated multiple times. Using a dictionary block for them can help avoid copying unnecessary data, especially for datatypes with large sizes. We can create dictionary blocks that point to elements (repetitively when required) in the input block to produce output for replicate channels. In this case, input block itself acts as a dictionary for output block.
Nested blocks (
ArrayBlockORMapBlockfor unnest channels) are created by adding a layer of indexing on top of their underlying element blocks (a LongArrayBlock for example). We can say that for the most part, these underlying element blocks are what we need as an output of our unnest channels, modulo a few special cases. Therefore, we try to refer elements from the underlying element blocks while creating output block. In this case, underlying element block inside the input block acts as a dictionary for output block.2. There exist cases where
DictionaryBlockcannot be used, and have to copy.The need for copying arises when a null element needs to be appended to the output. This happens when the cardinality of a nested element is smaller than any of the elements in other unnest channels. We call this mismatch of cardinalities misalignment.
This is because we cannot create a pointer to any element in the input block for representing null, if there is no null element in the input block. Currently, the DictionaryBlock implementation does not use negative indices to represent NULL elements. (When it does, we can get rid of copying altogether. @dain mentioned that it would be a big project in itself.)
If the input block indeed contains a NULL element, we can use the index of that element in output dictionary block.
So when we encounter a null-append operation on the output block (and absence of a null element in the input), we have to move away from
DictionaryBlock. Elements are copied over to create a new output block (just like the current implementation). But this won’t happen as frequently.For replicate output blocks, no copying is required whatsoever. This is because a null element is never going to be appended, unless there is a null in the input replicate block. So, the replicate output block will always be a dictionary block.
For unnest output blocks, copying is required only if there is misalignment. That will not happen if we are only unnesting one column (apart from a special case with row unnesting), which is usually the common case. Even when the misalignment occurs, copying won’t be required if there is a null entry in the underlying element block of the nested block.
BlockProducerFromSourceobject is given one of the input blocks as the source. It has methods to process elements in this block and create an output block. The output can be either (1) a dictionary block using the source as a dictionary or (2) a block created by copying elements from the source.3. Unnesters maintain columnar structures to help avoid copying.
There are 3 different implementations of Unnester abstract class.
MapUnnester,ArrayUnnesterandArrayOfRowsUnnester. An Unnester object processes input rows for a nested column and produces output blocks when asked for.ColumnarMap,ColumnarArrayandColumnarRowstructures help access underlying element blocks from the nested blocks (likeMapBlock,ArrayBlock,RowBlock). Unnesters maintain some form of the Columnar Structures for processing unnest channel blocks. When new input blocks are assigned to an Unnester, corresponding Columnar structures are refreshed as well.Every Unnester is supposed to output one or more output blocks, the number of output blocks is called channelCount. For example, channelCount for a MapUnnester is 2, because it produces blocks corresponding to keys and values. An Unnester contains an array of BlockProducerFromSource objects of length channelCount, to produce outputs.
The Unnester processes input nested blocks one row at a time. For every row, it translates the position in the nested block to positions in underlying element blocks and invokes
BlockProducerFromSourcemethods for all output channels.