Gender Recognition by Voice and Speech Analysis
Run the online demo.
Read the full article Identifying the Gender of a Voice using Machine Learning.
This project trains a computer program to identify a voice as male or female, based upon acoustic properties of the voice and speech. The model is trained on a dataset consisting of 3,168 recorded voice samples, collected from male and female speakers. The voice samples are pre-processed by acoustic analysis in R and then processed with artificial intelligence/machine learning algorithms to learn gender-specific traits for classifying the voice as male or female.
The best model achieves an accuracy of 100% on the training set and 89% on the test set.
Update: By narrowing the frequency range analyzed to 0hz-280hz (human vocal range), the best accuracy is boosted to 100%/99%.
Download the pre-processed dataset as a CSV file.
The CSV file contains the following fields:
"meanfreq","sd","median","Q25","Q75","IQR","skew","kurt","sp.ent","sfm","mode","centroid","meanfun","minfun","maxfun","meandom","mindom","maxdom","dfrange","modindx","label"
"label" corresponds to the gender classification of the sample. The remaining fields are acoustic properties, detailed below.
In R, you can load the dataset file data.bin directly as a data.frame with the command load('data.bin').
In addition to the pre-processed dataset, the raw voice samples used for training are included as .WAV files in a separate repository. The .WAV files are pre-processed in R to produce the above dataset.
The trained models have achieved the following accuracies (train/test):
50%/50%
61%/59%
72%/71%
81%/78%
100%/87%
91%/84%
100%/87%
100%/99%
The following acoustic properties of each voice are measured:
- duration: length of signal
- meanfreq: mean frequency (in kHz)
- sd: standard deviation of frequency
- median: median frequency (in kHz)
- Q25: first quantile (in kHz)
- Q75: third quantile (in kHz)
- IQR: interquantile range (in kHz)
- skew: skewness (see note in specprop description)
- kurt: kurtosis (see note in specprop description)
- sp.ent: spectral entropy
- sfm: spectral flatness
- mode: mode frequency
- centroid: frequency centroid (see specprop)
- peakf: peak frequency (frequency with highest energy)
- meanfun: average of fundamental frequency measured across acoustic signal
- minfun: minimum fundamental frequency measured across acoustic signal
- maxfun: maximum fundamental frequency measured across acoustic signal
- meandom: average of dominant frequency measured across acoustic signal
- mindom: minimum of dominant frequency measured across acoustic signal
- maxdom: maximum of dominant frequency measured across acoustic signal
- dfrange: range of dominant frequency measured across acoustic signal
- modindx: modulation index. Calculated as the accumulated absolute difference between adjacent measurements of fundamental frequencies divided by the frequency range
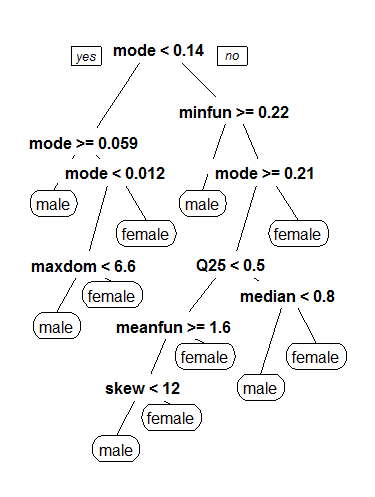
The following decision tree, produced by the CART model, provides a high-level overview of important properties of the voice samples that may determine a specific gender classification of male versus female.
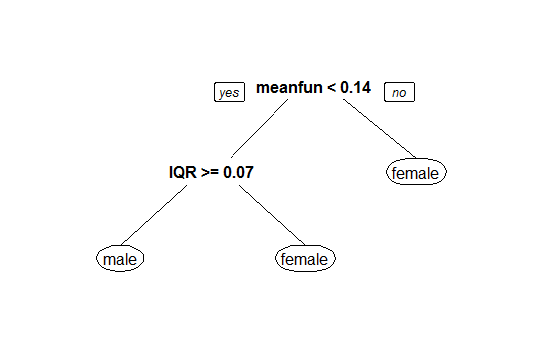
After narrowing the frequency range to 0hz-280hz with a sound threshold of 15%, the accuracy is boosted to near perfect, and the following CART model is described. Mean fundamental frequency serves as a powerful indicator of voice gender, with a threshold of 140hz separating male from female classifications.
The Harvard-Haskins Database of Regularly-Timed Speech
Telecommunications & Signal Processing Laboratory (TSP) Speech Database at McGill University, Home
Festvox CMU_ARCTIC Speech Database at Carnegie Mellon University
Copyright (c) 2022 Kory Becker http://primaryobjects.com/kory-becker
Kory Becker http://www.primaryobjects.com