labels.Labels: reduce memory by storing as a single string #10991
Conversation
17ebc71
to
5b5091b
Compare
|
|

|
/prombench main |
|
I tried to test this patch to see what kind of memory savings it could give me but soon after startup I got this panic: |
|
@prymitive thanks for that; somehow the buffer it's trying to use is too small. |
Sadly no, all I got was panics in the logs with multiple different indexes in the |
|
The query executed is printed on the next startup when Prometheus reads the
active query logging
Le mer. 6 juil. 2022, 18:46, Łukasz Mierzwa ***@***.***> a
écrit :
… @prymitive <https://github.com/prymitive> thanks for that; somehow the
buffer it's trying to use is too small. Anything you can tell me about the
query being executed when it crashed?
Sadly no, all I got was panics in the logs with multiple different indexes
in the slice bounds out of range error, no idea which queries caused it.
—
Reply to this email directly, view it on GitHub
<#10991 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AACHHJUJDFKEDEDPTNEGL7LVSWZ65ANCNFSM52ZXDLTQ>
.
You are receiving this because you are subscribed to this thread.Message
ID: ***@***.***>
|
Prometheus never crashed, panic was recovered. |
That seems like a good opportunity for improvement. If a panic reaches the http handler then log the query. Separately, can you say if this was the first panic? If not can you post the stack trace for that one? |
|
Prombench results: There seems to be roughly 10% savings in RSS. Querying is similar, but a little more expensive in the prepare_time (which is where we get the samples from TSDB). The inner_eval, where most of the operations happen, is pretty much same. The different doesn't look concerning at the moment. /prombench cancel |
|
/prombench cancel |
|
Benchmark cancel is in progress. |
|
I've added patch from #10995 and I see a few panics in logs. |
|
Running a range query for |
|
Adding some debug logs with: @@ -717,6 +719,9 @@ func marshalLabelsToSizedBuffer(lbls []Label, data []byte) int {
func marshalLabelToSizedBuffer(m *Label, data []byte) int {
i := len(data)
i -= len(m.Value)
+ if i < 0 {
+ fmt.Printf("BUG! marshalLabelToSizedBuffer(m.name=%q m.value=%q, data=%q) i=%d\n", m.Name, m.Value, string(data), i)
+ }
copy(data[i:], m.Value)
i = encodeSize(data, i, len(m.Value))
i -= len(m.Name)I get this: |
@@ -708,6 +709,15 @@ func (b *Builder) Labels() Labels {
func marshalLabelsToSizedBuffer(lbls []Label, data []byte) int {
i := len(data)
for index := len(lbls) - 1; index >= 0; index-- {
+ if len(lbls[index].Value) > len(data[:i]) {
+ fmt.Printf(`*** BUG! ***
+ marshalLabelsToSizedBuffer(lbls=%v data=%q)
+ index=%d
+ lbls[%d].Name=%q lbls[%d].Value=%q
+ data[:%d]=%q
+*** END ***
+`, lbls, data, index, index, lbls[index].Name, index, lbls[index].Value, index, data[:i])
+ }
size := marshalLabelToSizedBuffer(&lbls[index], data[:i])
i -= size
}and captured some more debug data |
New theory: the problem is concurrent use of this [side-note: I don't think there is a unit test of concurrent queries] The First thought is to move the stateful Taking a more lateral approach, I can change Maybe I'll try both. |
7edd1c9
to
5ca9ed5
Compare
|
I managed to recreate the race I theorised in previous message in a unit test, and moved the state into Unfortunately the new test seems to run out of memory at CircleCI. I tried reducing the concurrency from 10 to 4 but it still gets "signal: killed". Maybe I can experiment with smaller data sets. @prymitive if you can re-test that'd be great. |
|
I did deploy it to the same test server and, so far, I don't see any panics, so it does look like the issue is resolved. I've also captured heap pprof on 2.36.0 (+ #10782 & #10709 patches) vs main+this patch. v2.36.0 this patch: Please do note that this was just a quick test, both instances didn't have much uptime, so memory usage might be different over longer time. But overall total memory usage did seem to drop. |
|
Somehow |
|
This is go alloc size (
Had to revert because problem with external_labels mentioned above breaks thanos - it tries to read external_labels from config via the API but gets nothing so it exits. |

I fixed a flaw with marshalling to YAML, which I think you meant. |
|
Thanks! I can confirm that it fixed external_labels issue |
|
I've deployed this patch to two instances today, that's on top of v2.37.0-rc1 (+ #10782 & #10709 patches since we have those on top of current v2.36.0). It's working fine after a few hours so I'll keep those two instance running this patch.
That's about 18-20% less, which is amazing.
|


|
FYI both instances are working perfectly fine and memory usage reduction is looking great. |
Can't assume nil is a valid value. Signed-off-by: Bryan Boreham <bjboreham@gmail.com>
ab35ec3
to
ae3e93c
Compare
This commit adds an alternate implementation for `labels.Labels`, behind
a build tag `stringlabels`.
Instead of storing label names and values as individual strings, they
are all concatenated into one string in this format:
[len][name0][len][value0][len][name1][len][value1]...
The lengths are varint encoded so usually a single byte.
The previous `[]string` had 24 bytes of overhead for the slice and 16
for each label name and value; this one has 16 bytes overhead plus 1
for each name and value.
In `ScratchBuilder.Overwrite` and `Labels.Hash` we use an unsafe
conversion from string to byte slice. `Overwrite` is explicitly unsafe,
but for `Hash` this is a pure performance hack.
Signed-off-by: Bryan Boreham <bjboreham@gmail.com>
This checks that no code is assuming things about `labels.Labels` which don't work with the alternate implementation. Co-authored-by: Julien Pivotto <roidelapluie@o11y.eu> Signed-off-by: Bryan Boreham <bjboreham@gmail.com>
ae3e93c
to
4a49ec3
Compare
|
With @roidelapluie assistance I have made the suggested change, so the new code is available with a build tag I broke out #12014 but the same commit is included in this PR. |
|
Thanks! |
|
Amazing! How do we plan to handle releases for this? Will the release binary have these new labels implementation used? |
|
So, now we know that tests pass with this. I propose we keep CI running with this for this release cycle. In the meantime, it would be great to see if we can find users to use a prometheus release (or mimir or thanos) built with this version and this tag (it would be easier if we first release this). In the release after the next release, if it is positive for the testers, we replace the original implementation with the new one. |
|
I looked through the release instructions and Makefile, but I didn't see a way to set Go tags.
|
|
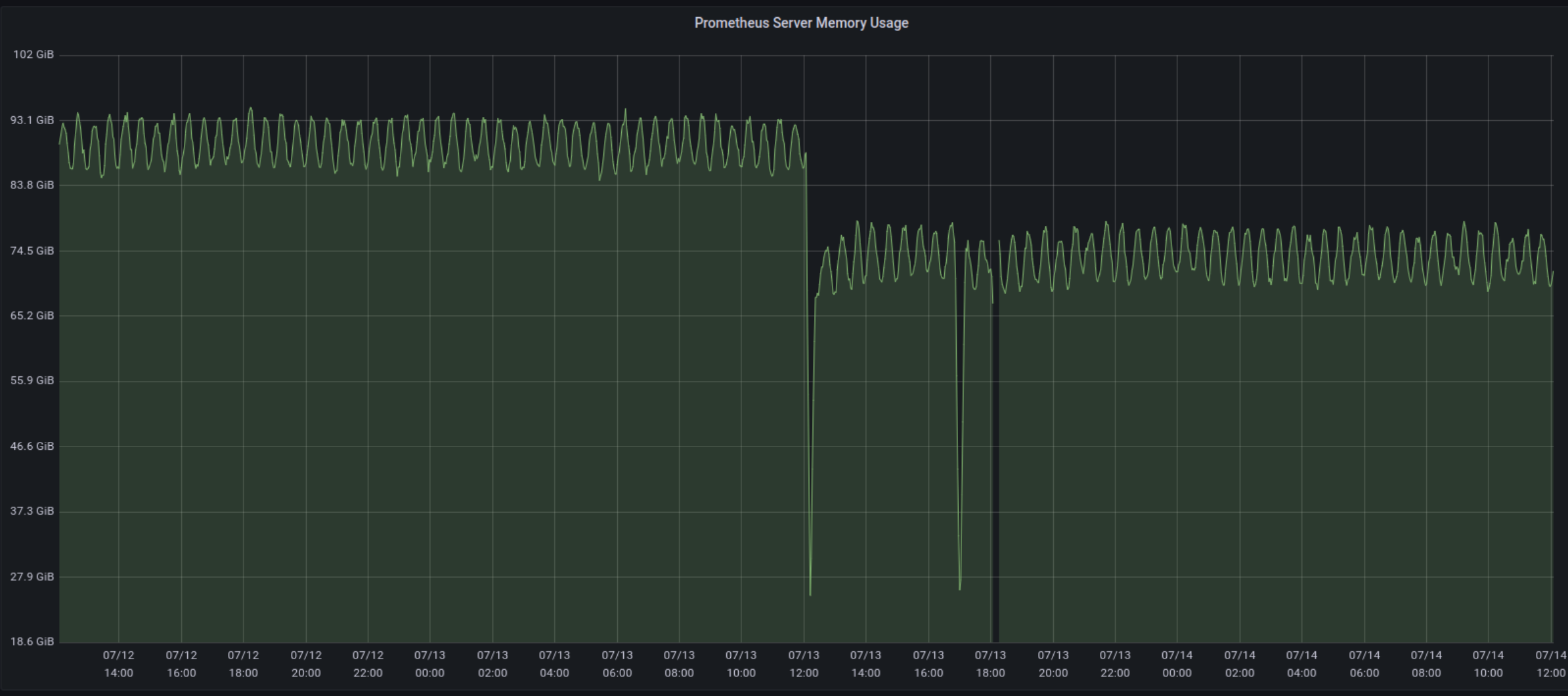
Our observation with our own cluster (normal memory consumption ~55GB): This graph shows the absolute amount of memory consumed by two nodes in our cluster, one running the patch version and one running v2.29.1 (lol we are behind on our upgrades). We can see that memory consumption can be as much as 10GB less (although some peaks are almost the same). The period at the start of the graph shows where the two nodes were running the same version (identical mem. consumption).
|


|
Thanks for posting your findings. |
|
By upgrade from v2.12.0 to v2.43.0-stringlabels tag, 30% drop in my prod env, |

|
Unfortunately for us there don't seem to be any memory savings compared to the instance running v2.42.0 before, however CPU consumption seems to have calmed down a bit.
|

|
Thanks for the data, @der-eismann. A saying of mine: "there is no single metric for memory which shows what is going on".
|
|
Happy to help @bboreham! You're completely correct with your saying and thanks for suggesting some useful metrics - I'm pretty sure the memory allocation is not perfect, it's more of a "it's not dying, so let's keep it 🤷♂️". The
Let me know if you need any other metrics! |






|
In my environment I'm seeing modest (possibly within margin of error tbh) memory improvements, but also a CPU usage reduction!
Compared to |


|
@der-eismann I feel I need to explain your first chart: I suggested @hamishforbes indeed the specific pattern of usage can make a big difference - I recently realised that dropped targets hold on to huge |
|
We've got an internal system I've got to successfully build with AFAICT the cpu reduction is largely coming from the reduced cost to construct labels on both the read and write side. The write side is translating from protobuf into a shared I did run into a few hiccups in trying to get our code working with both Thanks for all of the hard work! So far this is looking very promising :) |
|
Hello
👏 Goodbye |

|
An update after rolling this out to our infra that stores 70 million time series. We saw the following resource use reduction after rolling this out:
I just want to thank everyone involved in this change, it's made a remarkable improvement. |
This commit adds an alternate implementation for
labels.Labels, behind a build tagstringlabels.Doc with background info: link.
This builds on #11717, which created abstractions to let code access
labels.Labelswithout knowing the internals.The new data structure is held as a single
string, containing all label/values like this:The lengths are varint encoded so usually a single byte.
The previous structure using
[]Labelhad 24 bytes of overhead for the slice and 16 for each label name and value; this one has 16 bytes overhead plus 1 for each name and value.(I previously published this idea on prometheus-developers. ).
In
Labels.Overwrite()andLabels.Hash()we use an unsafe conversion from string to byte slice.Overwriteis explicitly unsafe, while inHashthis is purely to change the type so we can use the faster implementation.As expected, benchmarks show some speedups and some slowdowns. We are trading more CPU in a few cases for less in most cases and smaller overall heap size. I think I can squeeze a bit more out of this design though.
Some notable improvements:
Full set (only run once before/after since they take 40 minutes): https://gist.github.com/bboreham/53626dde3a5f7cf732a23c1a745435fd