Replace text #1674
-
|
Hi I'm back again. I'm trying to replace text from a pdf and in almost of all the pdfs I tried it worked well, but this one has the characters too close and seems to generate a white box for the text too big and deletes the text below: And another problem is that if the name starts in one line and ends in the next one it replaces it three times: PD: First pdf file attached if you need to test something. Thanks in advance |



Beta Was this translation helpful? Give feedback.
Replies: 9 comments 19 replies
-
|
Unexpectedly large replacement rectangles are due to overlapping lines in the PDF. Unfortunately, some PDF creators insert lines at a closer vertical distance, than the lineheight (a font property, computed as A first way out is setting a global PyMuPDF parameter: If lines still overlap vertically, the PDF creator made a really ugly looking document! You can still fiddle around this situation by creating very small-height rectangles for redactions only (e.g. 20% of original height around the middle horizontal line of the original rectangle), and still use the original rectangle for inserting the new text. |
Beta Was this translation helpful? Give feedback.
-
|
Adding that "fitz.TOOLS.set_small_glyph_heights(True)" and resizing the rect with "rect = rect * 0.999" gives me this: So thank you so much! |

Beta Was this translation helpful? Give feedback.
-
This is something you must react to. Search will return several rectangles if |
Beta Was this translation helpful? Give feedback.
-
|
The pdfs I'm working on won't have that meth-od feature, they are just name strings like "Emilio Jose Martí Gómez", so half of the time the name will be like: |
Beta Was this translation helpful? Give feedback.
-
|
Ok, so maybe your names will never be hyphenated. Just mentioned it in case. |
Beta Was this translation helpful? Give feedback.
-
|
Okay, thanks for the guidance, so if i have a 4 element name with 2 in one line and 2 in the next one, I can compare the y position of the bbox to know that they are in different lines and then as I have 1/2 name above replace it with 1/2 of the substitute, and the same for the next one, right? PD: i put the 1/2 example as I could use fractions to separate the name between lines |
Beta Was this translation helpful? Give feedback.
-
|
Algo así. If you are sure that your name only occurs once on a page, things are simple.
|
Beta Was this translation helpful? Give feedback.
-
|
A hit rect is the "rect" from my previous example? Because the names can occur more than once haha |
Beta Was this translation helpful? Give feedback.
-
|
this is simply one of the items in |
Beta Was this translation helpful? Give feedback.
-
|
Okay okay, I'm going to try to do it, and if I achieve it or if I fail I'll keep you informed |
Beta Was this translation helpful? Give feedback.
-
|
Just to confuse you a bit more: |
Beta Was this translation helpful? Give feedback.
-
|
And here I'm kind of lost. Is this more or less the way to go? |
Beta Was this translation helpful? Give feedback.
-
|
Hi I'm back, sorry for answering late, I was on a little vacation. I'm still working on that replace in two lines, but I found a problem with a pdf. In that one I can replace everything but one string, if I try to replace a name in this case "Antonio González", it says NameError: name 'origin' is not defined. But is defined, and the string is in the pdf. Do you know why this might happen? |
Beta Was this translation helpful? Give feedback.
-
|
This name "origin" only exists in "span" and "char" dictionaries which are returned as part of |
Beta Was this translation helpful? Give feedback.
-
|
Ookay, that happened because trying to solve a problem I had (the replacing name was printed in every bbox) this solved it but generates also this one. Thank you! |
Beta Was this translation helpful? Give feedback.
-
|
If you use nombre = "Emilio Jose Martí Gómez"
nombre_t = nombre.split(" ")
lnombre = len(nombre_t) # number of name components
words = page.get_text("words", sort=True)
i = 0
while i < len(words):
word = words[i]
if word[4] == nombre_t[0]: # found 1st part of name
rects = [fitz.Rect(w[:4]) for w in words[i : i+lnombre]]
# rects = list of rectangles containing the full name
# process them adequately, then ...
i += lnombre
else:
i += 1 |
Beta Was this translation helpful? Give feedback.
-
|
Okaay, now I get how to do the search correctly, but I do not get the Redact/insert/origin, in this case do i have to redact insert twice? or two redact an then insert? |
Beta Was this translation helpful? Give feedback.
-
|
The origin depends on the font you use for insertion. There are two values: helv = fitz.Font("helv")
origin = rect.tl + (0, helv.ascender * rect.height) |

Beta Was this translation helpful? Give feedback.
-
|
Okay, thanks for the image, then when applying that to my code will be something like this? And to get the fsize do i have to iterate like in the previous example through spans and word["lines"]? |
Beta Was this translation helpful? Give feedback.
-
|
Beta Was this translation helpful? Give feedback.
-
|
Okaay, that's working right now, the thing is it finally replaces both texts in both lines but erasing everthing haha, and i don't know why this happens |

Beta Was this translation helpful? Give feedback.
-
|
As I said some post before:
|
Beta Was this translation helpful? Give feedback.
-
|
And when I do the replacing in one line
|

Beta Was this translation helpful? Give feedback.
-
|
Oha. Why don't you do this ("rects" is the bbox list of name components): newrects = [] # will contain rectangles joined per line
bottoms = set([bbox[3] for bbox in rects]) # contains the y1 values for the rects
for y in bottoms:
rect = fitz.EMPTY_RECT()
for r in rects:
if r[3] == y:
rect |= r
newrects.append(rect)
# there are as many rectangles in newrects now as there are lines with names components
for r in newrects:
page.add_redact_annot(r)
page.apply_redactions()
page.insert_text(newrects[0], ...) |
Beta Was this translation helpful? Give feedback.
-
|
Trying my text above ir repeats itself all the lane, but yours shows: Two things else, can't solve the erasing problem and i don't know why comparisons are not working: |

Beta Was this translation helpful? Give feedback.
-
|
You for sure owe me something! |
Beta Was this translation helpful? Give feedback.
-
|
After filling it with |
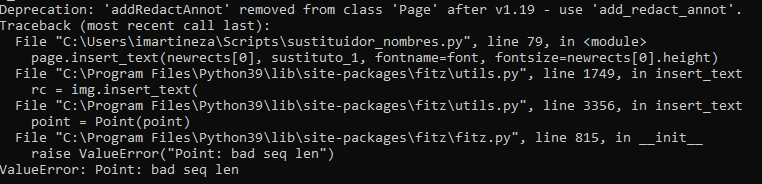
Beta Was this translation helpful? Give feedback.
If you use
get_text("words",sort=True)you don't need search!