Export fake quantization function to ONNX #39502
Comments
|
Good point! FakeQuantize is a good choice as for exporting quantization params like scale&zeropoint. |
|
Thanks @Zehaos. What was discussed with @jamesr66a and @raghuramank100 is I'll also contribute the PR. If the owner of the code is OK with it. So would be happy to contribute. |
|
Hi @skyw, this proposal looks good! Please feel free to contribute the PR |
|
Thanks, James. Filed PR #39738 |
Summary: As discussed in #39502. This PR adds support for exporting `fake_quantize_per_tensor_affine` to a pair of `QuantizeLinear` and `DequantizeLinear`. Exporting `fake_quantize_per_channel_affine` to ONNX depends on onnx/onnx#2772. will file another PR once ONNX merged the change. It will generate ONNX graph like this: 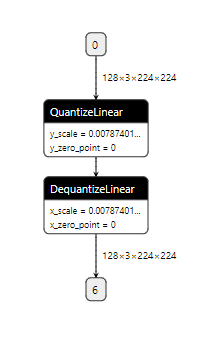 jamesr66a Pull Request resolved: #39738 Reviewed By: hl475 Differential Revision: D22517911 Pulled By: houseroad fbshipit-source-id: e998b4012e11b0f181b193860ff6960069a91d70
{kind=link}
Summary: Fixes #39502 This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR #39738. `axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by onnx/onnx#2772. [update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master. The function is also tested offline with the following code ```python import torch from torch import quantization from torchvision import models qat_resnet18 = models.resnet18(pretrained=True).eval().cuda() qat_resnet18.qconfig = quantization.QConfig( activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant) quantization.prepare_qat(qat_resnet18, inplace=True) qat_resnet18.apply(quantization.enable_observer) qat_resnet18.apply(quantization.enable_fake_quant) dummy_input = torch.randn(16, 3, 224, 224).cuda() _ = qat_resnet18(dummy_input) for module in qat_resnet18.modules(): if isinstance(module, quantization.FakeQuantize): module.calculate_qparams() qat_resnet18.apply(quantization.disable_observer) qat_resnet18.cuda() input_names = [ "actual_input_1" ] output_names = [ "output1" ] torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13) ``` It can generate the desired graph. Pull Request resolved: #42835 Reviewed By: houseroad Differential Revision: D26293823 Pulled By: SplitInfinity fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea
Summary: Fixes #39502 This PR adds support for exporting **fake_quantize_per_channel_affine** to a pair of QuantizeLinear and DequantizeLinear. Per tensor support was added by PR #39738. `axis` attribute of QuantizeLinear and DequantizeLinear, which is required for per channel support, is added in opset13 added by onnx/onnx#2772. [update 1/20/2021]: opset13 is being supported on master, the added function is now properly tested. Code also rebased to new master. The function is also tested offline with the following code ```python import torch from torch import quantization from torchvision import models qat_resnet18 = models.resnet18(pretrained=True).eval().cuda() qat_resnet18.qconfig = quantization.QConfig( activation=quantization.default_fake_quant, weight=quantization.default_per_channel_weight_fake_quant) quantization.prepare_qat(qat_resnet18, inplace=True) qat_resnet18.apply(quantization.enable_observer) qat_resnet18.apply(quantization.enable_fake_quant) dummy_input = torch.randn(16, 3, 224, 224).cuda() _ = qat_resnet18(dummy_input) for module in qat_resnet18.modules(): if isinstance(module, quantization.FakeQuantize): module.calculate_qparams() qat_resnet18.apply(quantization.disable_observer) qat_resnet18.cuda() input_names = [ "actual_input_1" ] output_names = [ "output1" ] torch.onnx.export(qat_resnet18, dummy_input, "quant_model.onnx", verbose=True, opset_version=13) ``` It can generate the desired graph. Pull Request resolved: #42835 Reviewed By: houseroad Differential Revision: D26293823 Pulled By: SplitInfinity fbshipit-source-id: 300498a2e24b7731b12fa2fbdea4e73dde80e7ea Co-authored-by: Hao Wu <skyw@users.noreply.github.com>
|
On current master. In So it skipped 10 tests by default, including I believe If we set I was getting the same errors when I updated to |
🚀 Feature
Export fake_quantize_per_tensor_affine and fake_quantize_per_channel_affine functions to ONNX.
Motivation
To support deploying QAT network by backend like TensorRT outside pytorch through ONNX, fake quantization needs to be exported to ONNX operator.
Pitch
fake quantization will be broken into a pair of QuantizeLinear and DequantizeLinear ONNX operator.
Alternatives
Additional context
Fake quantization is effectively quantize followed dequantize. Have discussed with @raghuramank100 and reached an agreement this is the right way to export.
Similar functionality has been added to tensorflow-onnx, onnx/tensorflow-onnx#919.
cc @houseroad @spandantiwari @lara-hdr @BowenBao @neginraoof @jerryzh168 @jianyuh @dzhulgakov @raghuramank100 @jamesr66a
The text was updated successfully, but these errors were encountered: