Significant perf reduction on Python GIL contention with dataloader pinning thread. #77139
Comments
|
cc @ptrblck |
|
@VitalyFedyunin @ptrblck Any thoughts or plans? I suspect this thread contention affects other workloads as well. I recall a performance drop in the past for HuggingFace BERT on a single V100 also being due to a data loader thread contention. Another potential fix, apart from the data worker destructing tensors on the data queue, might be dropping the Python GIL during tensor destruction. Though I'm not sure how safe the latter is. |
|
@ngimel Is anyone interested in fixing this? |
|
We will accept a PR fixing this |
|
cc @ejguan |
|
Thanks @ngimel. I will see if I can submit a simple but viable fix in which the data worker does the tensor destruction. It might be a week before I get time to work on it. |
|
Curious if anyone has an idea on how to get around destructing tensor blocks GIL? We found the GIL was blocked for 200ms during each iteration due to having to munmap a couple big tensors. Since I am not familiar with pytorch internal, these ideas might be really bad.
|
|
IIUC, this question is more related to how to delete Tensor without blocking the main process. Wondering do you have any recommendation on this topic? @ezyang |
|
If the thread doing the munmap is fine unblocking, then the fix is very simple: just release the GIL before doing the munmap. Does anyone know which munmap is the relevant one from the traces? If we need to arrange for a different thread to actually do the munmap, that's a little more complicated, but still doable. In any case the lesson is clear: don't hold a lock when doing expensive operations. |
|
Happened to be debugging this, seems like it might be this one? |
|
hmm, I wonder if we can safely release gil in |
|
At the same time, wondering if it would be safer to minimize the scope of the GIL release to the |
|
Give it a try. I'm not sure it's entirely kosher but maybe you can play around with it. A slightly safer thing to do is to move the Variable out of the location (setting it to empty while the GIL is held), and THEN destruct it without the GIL. |
Sam says that it is ok to locally release the gil there. |
Fixes #77139, where deallocating large tensors with munmap takes a significant amount of time while holding the GIL. This causes the pin_memory thread to interfere with the main thread = performance sadness. Thanks @igozali @zhengwy888 @colesbury as well. Pull Request resolved: #83623 Approved by: https://github.com/albanD
|
Thanks folks. It's nice to see this likely fixed. Sorry this fell off my radar after I wasn't able to focus on it. |
Summary: Fixes #77139, where deallocating large tensors with munmap takes a significant amount of time while holding the GIL. This causes the pin_memory thread to interfere with the main thread = performance sadness. Thanks igozali zhengwy888 colesbury as well. Pull Request resolved: #83623 Approved by: https://github.com/albanD Test Plan: contbuild & OSS CI, see https://hud.pytorch.org/commit/pytorch/pytorch/abcf01196cd27805349aa892db847f9a61f52c0e Reviewed By: atalman Differential Revision: D38831020 Pulled By: atalman fbshipit-source-id: ed3d7f20e2872e2aa677d4d36abed7d73e9bbae1
…pytorch#83623)" This reverts commit abcf011.
…pytorch#83623)" This reverts commit abcf011.
…pytorch#83623)" This reverts commit abcf011.
…ch#77139 (pytorch#83623)"" This reverts commit 8f73708.
…ch#77139 (pytorch#83623)"" This reverts commit 8f73708.
…ch#77139 (pytorch#83623)"" - This reverts commit 8f73708. - SWDEV-386723 - superbench perf regression.
…ch#77139 (pytorch#83623)"" (#1199) - This reverts commit 8f73708. - SWDEV-386723 - superbench perf regression.
…ch#77139 (pytorch#83623)"" This reverts commit 8f73708.
…ch#77139 (pytorch#83623)"" (#1199) - This reverts commit 8f73708. - SWDEV-386723 - superbench perf regression.
🐛 Describe the bug
I am observing 50+ ms bubbles in the GPU streams due to the pinning thread freezing out the main threads. The entire training pass would be 335 ms if the freezing were not present, so it makes for a significant performance reduction. It's worse still in a many-GPU environment where the GPUs need to synchronize each pass.
Environment: 8 x Nvidia A100.
Kernel: Linux 5.13.0-1024-gcp and Ubuntu 20.04.
Docker container: nvcr.io/nvidia/pytorch:22.03-py3 (contains torch 1.12.0a0+2c916ef)
Script: Running ViT-small training from DINO with ImageNet data.
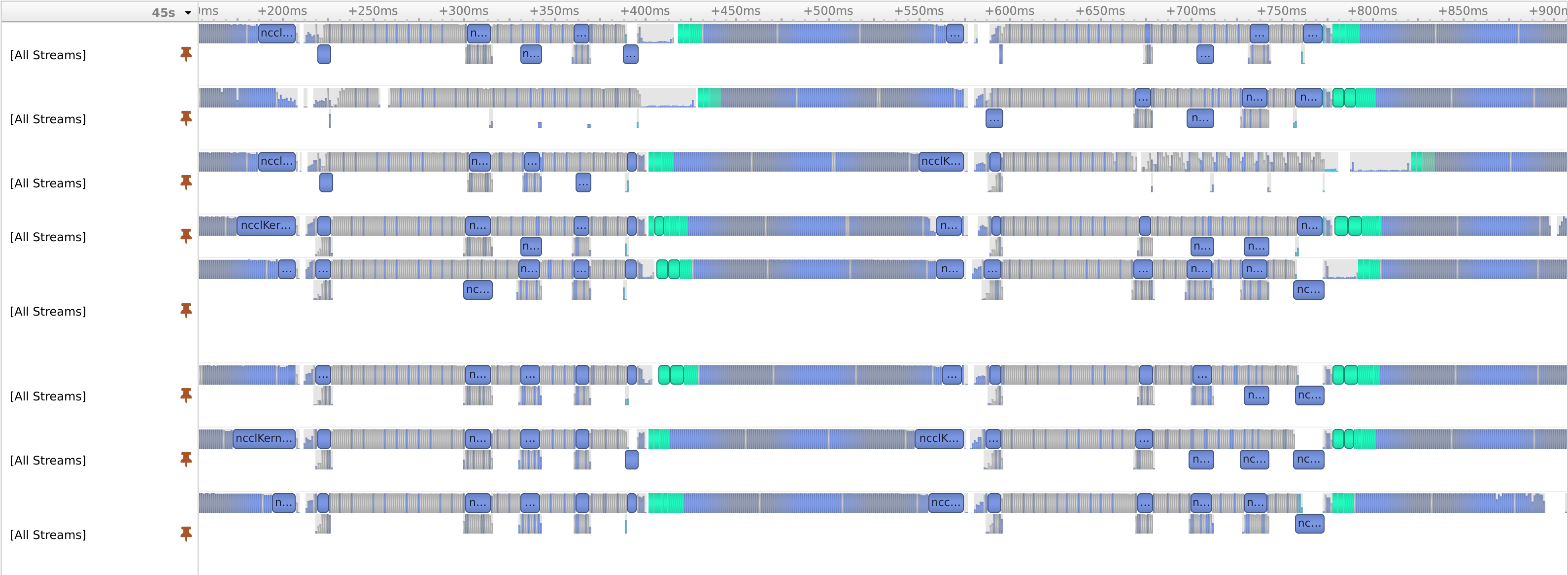
This screen grab from Nvidia Nsight traces the bubbles in the GPU stream back to the pinning thread (labeled "receive data" on left) freezing out the main threads (labeled "PyT main" and "PyT b/w" on left):

From observing the backtrace the pinning thread likely holds the Python GIL while invoking a tensor destructor on this line:
pytorch/torch/utils/data/_utils/pin_memory.py
Line 38 in 2e2200d
It looks to me like the tensors on the data queue goes out of scope here. These tensors are passed to the pinning thread from one of the worker processes and exist in a shared memory region. The tensor destructor spends a long time in syscall munmap.
To test the theory I made a hack to the torch dataloader to coerce the tensor deletion to happen in the worker process rather than than pinning thread. The bubbles went away.
Here's the GPU activity on all eight A100 streams before (bubbles circled):

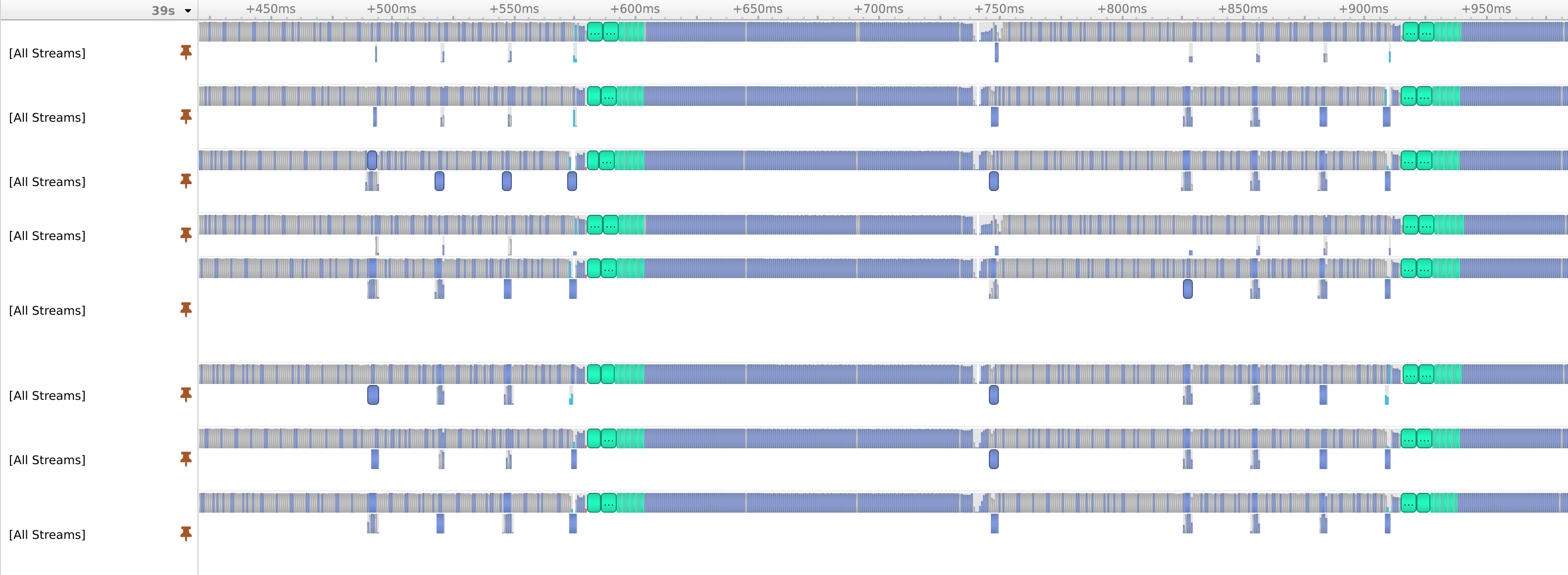
Here's after the hack (no observable bubbles):
As an aside, if you further replace torch AdamW optimizer with Nvidia's apex version it's clean:
Can we ensure there is no thread contention between pinning thread and the main threads? Is there any reason the worker process can't destruct tensors on the data queue rather than the pinning thread?
Versions
Collecting environment information...
PyTorch version: 1.12.0a0+2c916ef
Is debug build: False
CUDA used to build PyTorch: 11.6
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.4 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04) 9.4.0
Clang version: Could not collect
CMake version: version 3.22.3
Libc version: glibc-2.31
Python version: 3.8.12 | packaged by conda-forge | (default, Jan 30 2022, 23:42:07) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-5.13.0-1024-gcp-x86_64-with-glibc2.10
Is CUDA available: True
CUDA runtime version: 11.6.112
GPU models and configuration:
GPU 0: A100-SXM4-40GB
GPU 1: A100-SXM4-40GB
GPU 2: A100-SXM4-40GB
GPU 3: A100-SXM4-40GB
GPU 4: A100-SXM4-40GB
GPU 5: A100-SXM4-40GB
GPU 6: A100-SXM4-40GB
GPU 7: A100-SXM4-40GB
Nvidia driver version: 450.172.01
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.3.3
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.3.3
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] numpy==1.22.3
[pip3] pytorch-quantization==2.1.2
[pip3] torch==1.12.0a0+2c916ef
[pip3] torch-tensorrt==1.1.0a0
[pip3] torchtext==0.12.0a0
[pip3] torchvision==0.13.0a0
[conda] magma-cuda110 2.5.2 5 local
[conda] mkl 2019.5 281 conda-forge
[conda] mkl-include 2019.5 281 conda-forge
[conda] numpy 1.22.3 py38h05e7239_0 conda-forge
[conda] pytorch-quantization 2.1.2 pypi_0 pypi
[conda] torch 1.12.0a0+2c916ef pypi_0 pypi
[conda] torch-tensorrt 1.1.0a0 pypi_0 pypi
[conda] torchtext 0.12.0a0 pypi_0 pypi
[conda] torchvision 0.13.0a0 pypi_0 pypi
cc @VitalyFedyunin @ngimel @ssnl @ejguan @NivekT
The text was updated successfully, but these errors were encountered: