




Kedro is a toolbox for production-ready data science. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular. You can find out more at kedro.org.
Kedro is an open-source Python framework hosted by the LF AI & Data Foundation.
To install Kedro from the Python Package Index (PyPI) run:
pip install kedro
It is also possible to install Kedro using conda:
conda install -c conda-forge kedro
Our Get Started guide contains full installation instructions, and includes how to set up Python virtual environments.
To access the latest Kedro version before its official release, install it from the main branch.
pip install git+https://github.com/kedro-org/kedro@main
| Feature | What is this? |
|---|---|
| Project Template | A standard, modifiable and easy-to-use project template based on Cookiecutter Data Science. |
| Data Catalog | A series of lightweight data connectors used to save and load data across many different file formats and file systems, including local and network file systems, cloud object stores, and HDFS. The Data Catalog also includes data and model versioning for file-based systems. |
| Pipeline Abstraction | Automatic resolution of dependencies between pure Python functions and data pipeline visualisation using Kedro-Viz. |
| Coding Standards | Test-driven development using pytest, produce well-documented code using Sphinx, create linted code with support for ruff and make use of the standard Python logging library. |
| Flexible Deployment | Deployment strategies that include single or distributed-machine deployment as well as additional support for deploying on Argo, Prefect, Kubeflow, AWS Batch and Databricks. |
The Kedro documentation first explains how to install Kedro and then introduces key Kedro concepts.
You can then review the spaceflights tutorial to build a Kedro project for hands-on experience
For new and intermediate Kedro users, there's a comprehensive section on how to visualise Kedro projects using Kedro-Viz.
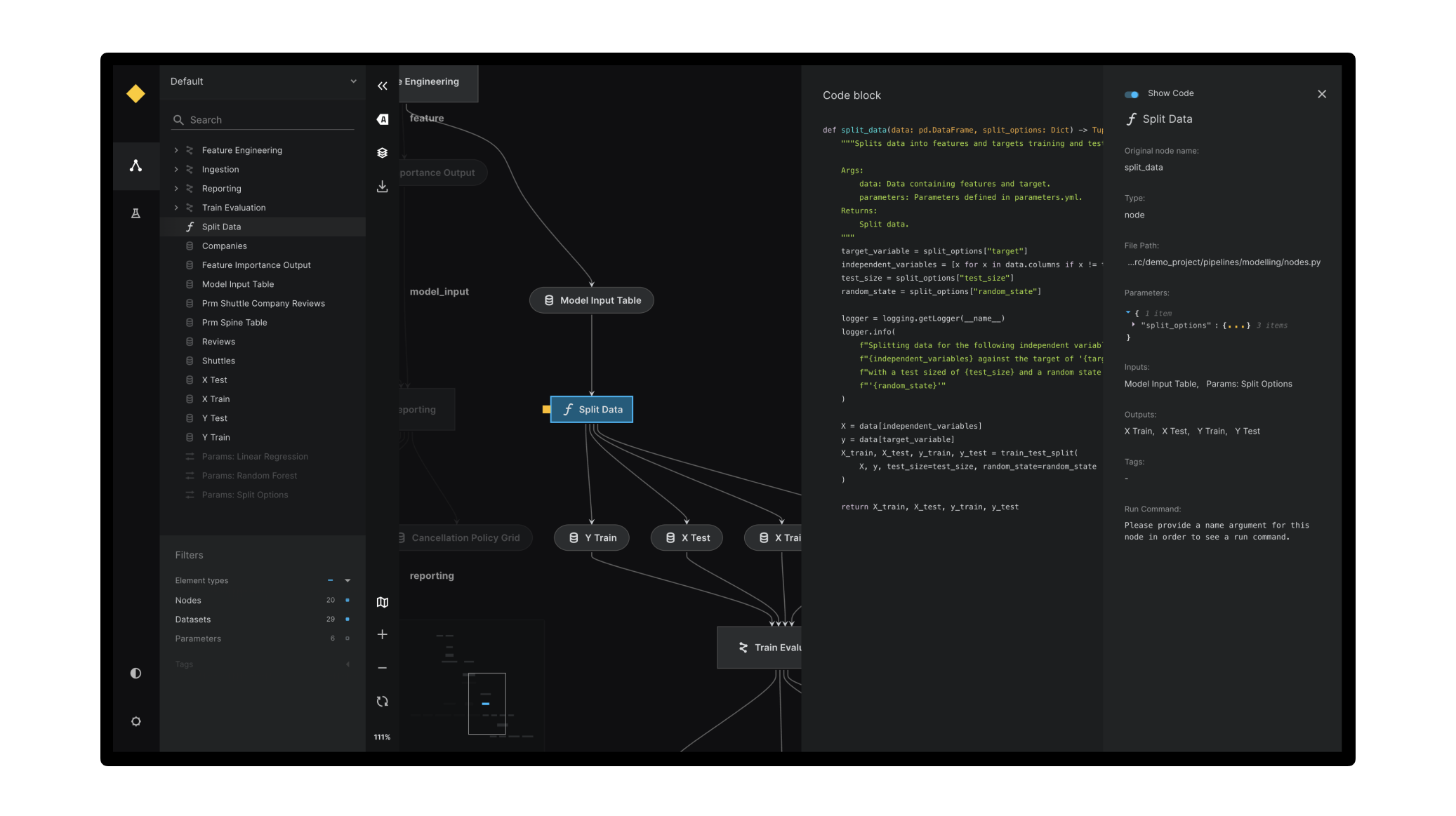 A pipeline visualisation generated using Kedro-Viz
A pipeline visualisation generated using Kedro-Viz
Additional documentation explains how to work with Kedro and Jupyter notebooks, and there are a set of advanced user guides for advanced for key Kedro features. We also recommend the API reference documentation for further information.
Kedro is built upon our collective best-practice (and mistakes) trying to deliver real-world ML applications that have vast amounts of raw unvetted data. We developed Kedro to achieve the following:
- To address the main shortcomings of Jupyter notebooks, one-off scripts, and glue-code because there is a focus on creating maintainable data science code
- To enhance team collaboration when different team members have varied exposure to software engineering concepts
- To increase efficiency, because applied concepts like modularity and separation of concerns inspire the creation of reusable analytics code
Find out more about how Kedro can answer your use cases from the product FAQs on the Kedro website.
The Kedro product team and a number of open source contributors from across the world maintain Kedro.
Yes! We welcome all kinds of contributions. Check out our guide to contributing to Kedro.
There is a growing community around Kedro. We encourage you to ask and answer technical questions on Slack and bookmark the Linen archive of past discussions.
We keep a list of technical FAQs in the Kedro documentation and you can find a growing list of blog posts, videos and projects that use Kedro over on the awesome-kedro GitHub repository. If you have created anything with Kedro we'd love to include it on the list. Just make a PR to add it!
If you're an academic, Kedro can also help you, for example, as a tool to solve the problem of reproducible research. Use the "Cite this repository" button on our repository to generate a citation from the CITATION.cff file.
- The core Kedro Framework supports all Python versions that are actively maintained by the CPython core team. When a Python version reaches end of life, support for that version is dropped from Kedro. This is not considered a breaking change.
- The Kedro Datasets package follows the NEP 29 Python version support policy. This means that
kedro-datasetsgenerally drops Python version support beforekedro. This is becausekedro-datasetshas a lot of dependencies that follow NEP 29 and the more conservative version support approach of the Kedro Framework makes it hard to manage those dependencies properly.