The online demo of LiB is here: https://hub-binder.mybinder.ovh/user/ray306-lib_demo-qsr3qu0q/doc/tree/Quick_Demo.ipynb You can run the Jupyter notebook to see the segmentation result.
Full article here: https://www.frontiersin.org/articles/10.3389/frai.2022.731615/full
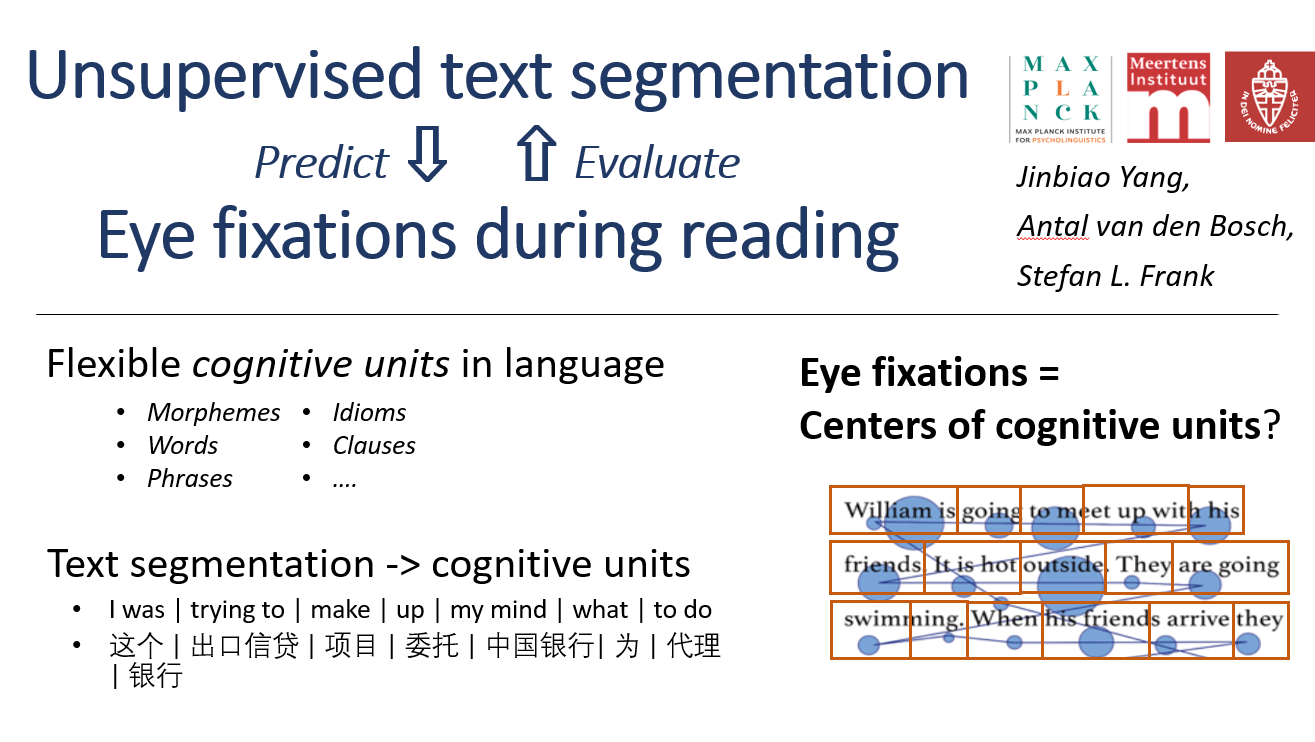
Words typically form the basis of psycholinguistic and computational linguistic studies about sentence processing. However, recent evidence shows the basic units during reading, i.e., the items in the mental lexicon, are not always words, but could also be sub-word and supra-word units. To recognize these units, human readers require a cognitive mechanism to learn and detect them. In this paper, we assume eye fixations during reading reveal the locations of the cognitive units, and that the cognitive units are analogous with the text units discovered by unsupervised segmentation models. We predict eye fixations by model-segmented units on both English and Dutch text. The results show the model-segmented units predict eye fixations better than word units. This finding suggests that the predictive performance of model-segmented units indicates their plausibility as cognitive units. The Less-is-Better (LiB) model, which finds the units that minimize both long-term and working memory load, offers advantages both in terms of prediction score and efficiency among alternative models. Our results also suggest that modeling the least-effort principle on the management of long-term and working memory can lead to inferring cognitive units. Overall, the study supports the theory that the mental lexicon stores not only words but also smaller and larger units, suggests that fixation locations during reading depend on these units, and shows that unsupervised segmentation models can discover these units.
See [Open It] LiB_evaluation_on_GECO.ipynb.
LiB.py is the main script of the LiB model. It depends on structures.py, which defines the basic data structure of LiB.
See Other models.
The files without name extension are the pre-processed corpora and eye-fixation data of GECO. Since the file size limitation of Github, the pre-processed large corpora (COCA and SoNaR) are uploaded to https://osf.io/ydr7w/.