important_text = normalize_corpus('C:/<<ZYZ>>/NER_news-main/corpora/todomexico.txt')
#Build the model, by selecting the parameters.
our_model = Word2Vec(important_text, vector_size=100, window=5, min_count=2, workers=20)
#Save the model
our_model.save("Mex_Corona_.w2v")
#Inspect the model by looking for the most similar words for a test word.
#print(our_model.wv.most_similar('mujeres', topn=5))
scatter_vector(our_model, 'Pfizer', 100, 21) Gensim based vector visualization. The modules here are intended to format corpora into a GENSIM-friendly format. Additionally, the corpora expected is in Spanish.
This contains corpora that is somewhat cleaned by running against a stopwords list.
Furthermore, the content not normalized has variations that are needless. The content here shows unnormalized vectors. This contains text that are capitalized and uncapitalized. This leads to a vector space in which China references could be made more accurate:
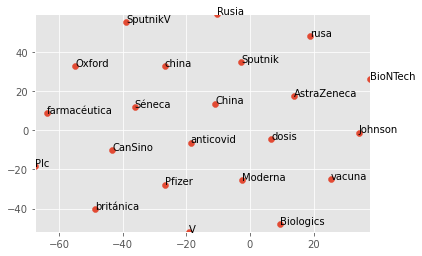
The graph below is normalizing terms, like "China" & "china" ---> "china" or "Russia" & "russia" ---> "russia".
I added an "string".lower() attribute line in the normalization function. This allows for a neater graph. Proper names, like "AMLO" & "amlo" (an acronym for the Mexican president) would rewrite to "amlo".
