Benchmarks
The Fastor benchmark suite includes a set of benchmarks for some heavily tested linear and tensor algebra routines for small to medium sized stack-based tensors. The benchmarks can be easily configured and reproduced on any machine. Here some benchmark results comparing the performance of Fastor with other notable libraries are provided. The libraries used in these benchmarks are either vendor BLAS or libraries that provide their own implementation of BLAS or (part of it). The ones included here are
- Eigen (3.3.7)
- Blaze (3.7)
- LIBXSMM (latest devel branch)
- MKL JIT (2021.01)
- Fastor (latest devel branch)
Eigen and Blaze are other expression template libraries with built-in BLAS routines (specifically Eigen has a full implementation of BLAS and LAPACK) while LIBXSMM and MKL JIT are specialised libraries for creating BLAS like kernels capable of generating statically compiled or JIT compiled kernels for matrix multiplication and other similar routines. For the benchmarks the latest development branches are used for Fastor and LIBXSMM (as of 19-Apr-2020) and the aforementioned releases for Eigen, Blaze and MKL. The LIBXSMM and MKL JIT kernels are run through Fastor's BLAS fallback layer that introduces no copies or overhead. MKL JIT is called using either the MKL_DIRECT_CALL_SEQ_JIT compiler switch or through MKL's new dedicated JIT API.
It is worth mentioning that Fastor by design does not use padding and it's internal kernels do not assume any specific alignment for the data as part of Fastor's attempt to wrap any external piece of memory. For this reason, padding has been turned off across all libraries. All the libraries are tested out-of-the-box with their default settings using a single thread and with Turbo/HT on like the LIBXSMM benchmarks reported in this issue of Intel Parallel Universe. To configure and run the benchmarks look at the instructions here.
In line with the philosophy of Fastor the following benchmarks are all for small to medium sized tensors. For operations such as ?gemm Fastor defines it's small/stack limit as cbrt(M*N*K) <=128.
The following benchmarks are run on fixed-size row-major matrices on Intel i5-8259U CPU [4 x 2.3GHz] running macOS 10.15. Using GCC9.2 with -O3 -DNDEBUG -mavx2 -mfma




The following benchmarks are run on Intel(R) Xeon(R) CPU E3-1240 v6 @ 3.70GHz desktop running Ubuntu 18.04. Using GCC9.2 with -O3 -DNDEBUG -mavx2 -mfma


The following benchmarks are run on static row-major matrices on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz running linux kernel 4.15.18. Using GCC7.4.0 with -O3 -DNDEBUG -mavx512f -mavx512vl -mavx512cd -mavx512bw -mavx512dq -mfma


Just like Intel MKL's BLAS performance for large matrices, Intel's MKL JIT introduced in 2019 sets the benchmark for small matrix-matrix multiplication in industry (if used correctly through their dedicated JIT API). Note that this is different from MKL_DIRECT_CALL_SEQ_JIT where the switch is made at runtime, although as seen in the previous plots MKL_DIRECT_CALL_SEQ_JIT is well performant. The JIT API is capable of generating bespoke matrix-matrix multiplication kernels for a given set of M,N,K. Our personal experience show that if JIT times for generating the kernels are excluded the performance of MKL JIT is second to none on Intel's modern processors. In the following benchmarks, a direct comparison between Fastor and MKL JIT is made using MKL's dedicated JIT API. While MKL JIT generates bespoke hand optimised kernels tuned for the given architecture, Fastor is written in pure C++. For comparison the Blaze library is also included in the benchmark this time with padding turned on as padding facilitates a pure SIMD code (with no remainder scalar loops) which is easier to generate. On the other hand, as mentioned above, Fastor does not require padding or alignment of the data. The benchmarks are run with M=1,2,..32, N=7,13,21,31 and K=31. The choice of N to not be equal to a multiple of the SIMD register width is on purpose here. The following benchmarks are run on fixed-size row-major matrices on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz running linux kernel 4.15.18 using GCC7.4.0 with -O3 -DNDEBUG -mavx512f -mavx512vl -mavx512cd -mavx512bw -mavx512dq -mfma. All benchmarks are in double precision. Timings are normalised with respect to Fastor's runtime (lower is better).


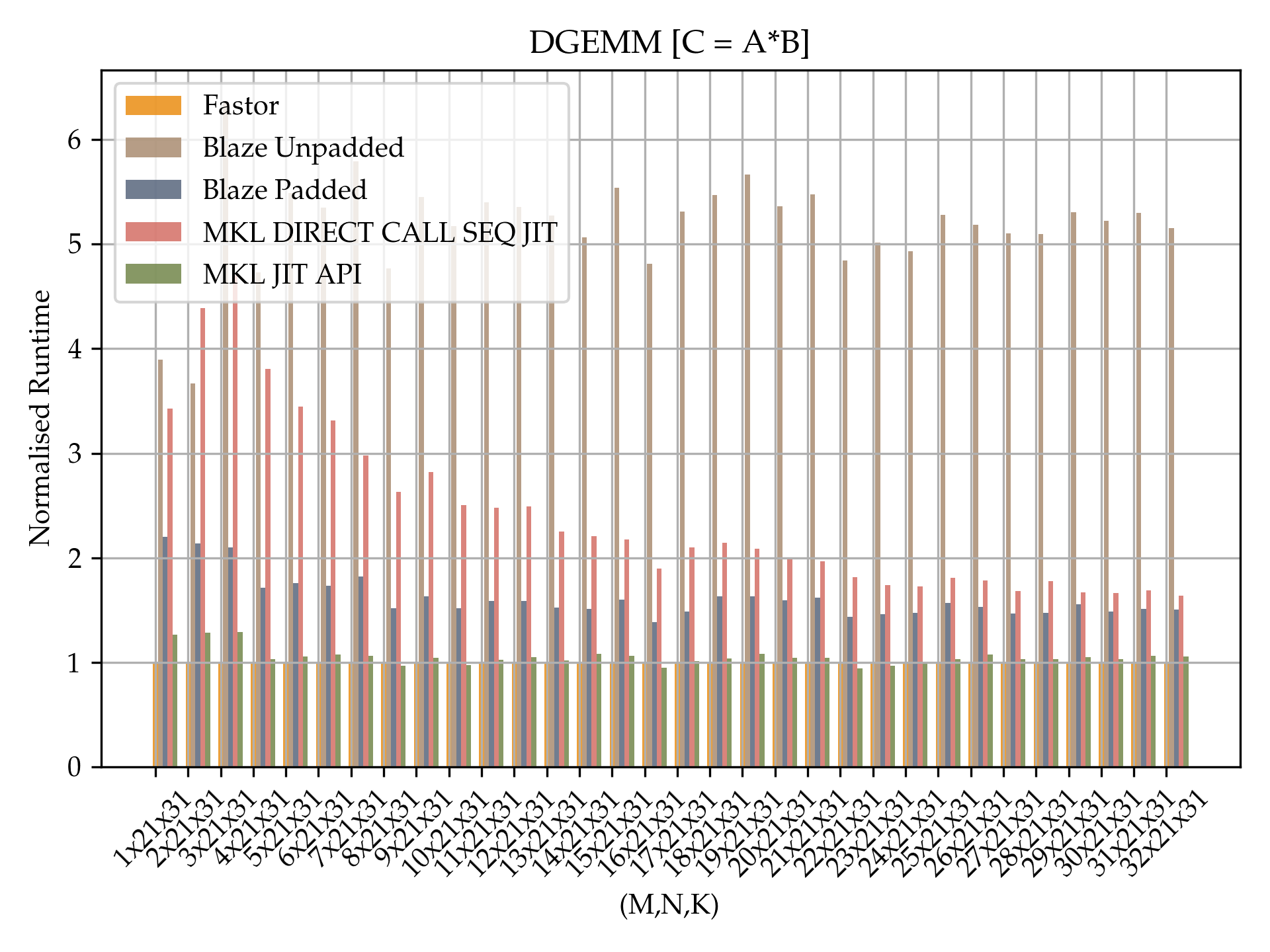

As can be observed Fastor's performance is on par with Intel's MKL JIT API. The figures also pinpoint the importance of padding in case of Blaze whose performance with padding ranges anywhere between the same speed to being over 2X slower in some cases while in general being about 50% slower, perhaps due to the overhead of zeroing out the padded elements and in general doing a bit more work. Blaze without padding falls back to scalar code for computing the remainders and hence it is not equally performant. Also observe that the MKL JIT direct call using MKL_DIRECT_CALL_SEQ_JIT is not as equally performant as it has a bit of the JIT overhead associated. The decline in the JIT overhead can be seen clearly as matrix sizes get bigger.
The following benchmarks are run on fixed-size row-major matrices on Intel i5-8259U CPU [4 x 2.3GHz] running macOS 10.15 compiled using GCC9.2 with -O3 -DNDEBUG -mavx2 -mfma
![]()
![]()