Created by: Richard Shin
This project exists to preserve the thousands of reviews that was hosted on CULPA, the unofficial professor and course review site for Columbia University. During the summer of 2021, the site started timing out during peak loads.
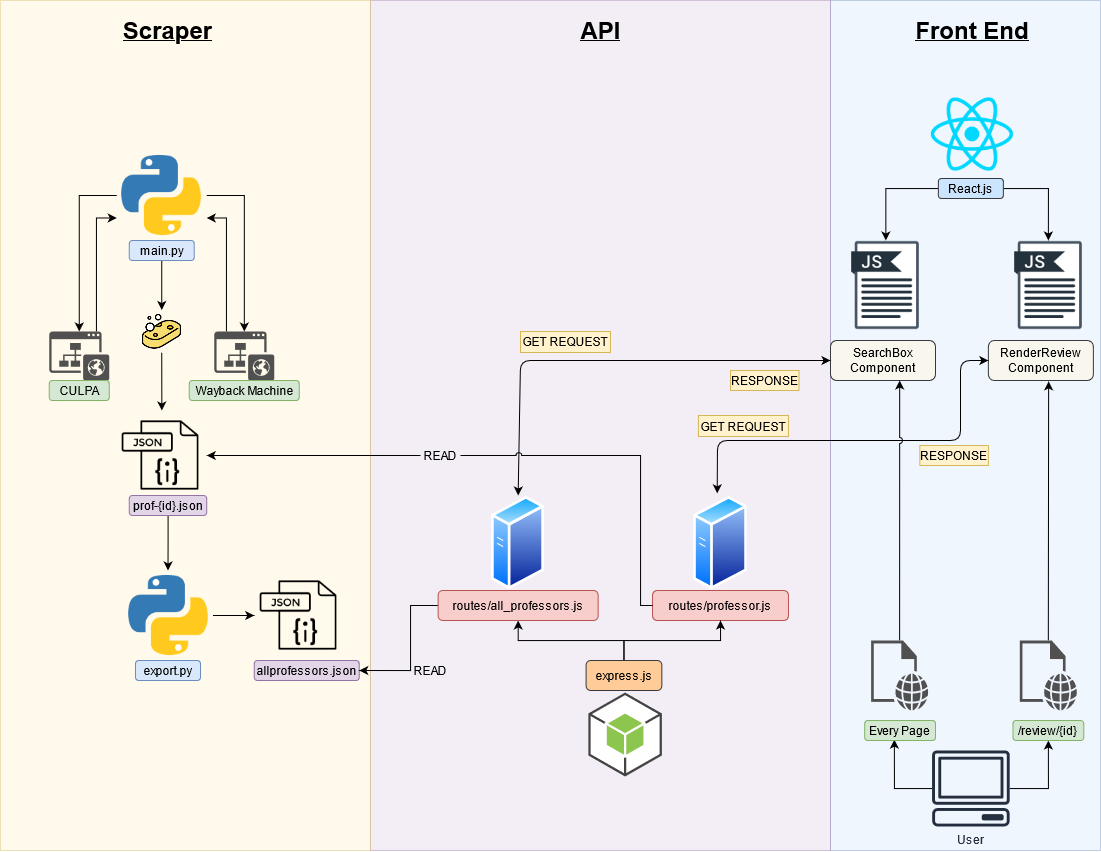
This project is broken up into three parts: the Scraper, the API, and the React App.
This portion of the project contains the scraper which was used to scrape CULPA. A tar.gz of the scraped data can be found with the culpa-cache-api repository so you do not have to scrape again.
main.py scrapes CULPA (or Wayback Machine archives) for all pertinent information: professor name, professor ID (as assigned by CULPA), course name of the review, date of the review, review content.
Since professor ID's are not 100% incremental (well, maybe they were, but some are missing/deleted/not cached), the script begins scraping from professor ID 1.
When a successful scrape occurs, a .json file is saved in the data folder with the following naming convention: prof-{id}.json. So, reviews from http://www.culpa.info/professors/1 is saved as prof-1.json.
If the script is unsuccessful in scraping from that ID it'll increment by one and try again.
There are two measures in place to prevent rate limitation:
- Quit scraping if there are too many consecutive failed scrapes,
- Five second delay in execution of the next scrape (comes out to around ~560 actions per hour).
export.py extracts just the Professor Name and ID from all the .json files in data and compiles it into one file: all_professors.json. This file is later used in the API server.
{
"prof_info": [
{
"prof_name": "Ted Mosby",
"prof_id": 9992,
"total_reviews": 3
}
],
"reviews": [
{
"course_name": "Architecture 101",
"review_date": "September 26, 2012",
"review_content": "Review omitted for readMe.."
},
{
"course_name": "Architecture 101",
"review_date": "March 10, 2012",
"review_content": "Review omitted for readMe.."
},
{
"course_name": "Architecture 101",
"review_date": "February 06, 2012",
"review_content": "Review omitted for readMe.."
}
]
}[
{
"prof_id": 1,
"prof_name": "Professor A"
},
{
"prof_id": 2,
"prof_name": "Professor B"
},
{
"prof_id": 3,
"prof_name": "Professor C"
}
]You will need to install these packages to get started:
pip install requestspip install beautifulsoup4