Improve autocompletion by looking on the type and name #3954
Conversation
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
6087c27
to
f62fe8d
Compare
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
|
I wonder if we could make a |
|
Yes definitely we can find a better way to handle this sort. I also thought about a type which could implement PartialEq. An enum for each different cases (in a function call, in a struct literal expression, ...) with all useful data inside. For exemple the call_info and fields in this first case. |
|
I made a little change, I moved all the sort directly in the |
…entation, include sort in Completions struct Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
|
Just for the record, I was thinking of something like: #[derive(PartialEq)]
enum CompletionMatchType {
Prefix,
Infix, // nMat for CompletionMatchType
Substring, // CMT for CompletionMatchType
}
enum CompletionItemType {
Fn(FnDef),
Field(FieldDef),
Macro(MacroDef),
// ...
}
struct CompletionItem {
ref: CompletionItemType,
type: CompletionMatchType,
is_type_match: bool,
// ...
}
impl Ord for CompletionItem {
// heuristics here
} |
|
Oh yes, I can implement |
Well, I'm not sure if it's the best approach, but we might want to show completions for all of those cases: prefix, literal substring (sequence) and non-contiguous substrings. Most IDEs can suggest Anyway, it's fine to not add it now. It might not even fit well with the rest of the code. PS: |
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
|
Ok I experimented a little bit. I was not very satisfied with the implementation of BTW as @matklad told me on Zulip, in fact even if we sort our completions in LSP server the client doesn't care about it. So I added an additional data called |
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
|
I just added the support also for |
|
Has anyone found any docs about how exactly Implementation wise, I feel relying on the order here would be a wrong abstraction. A sorted completion list tells you that there's an unambiguous linear order from worst to best, but that's not actually true in practice. We, for example, can't generally compare unrelated completions, like a reference completion vs keyword completion. I think the right abstraction is to add a struct CompltionScore {
...
}to each completion field, where score is something with struct CompltionScore {
is_precise_type_match: bool
}but it than could be extended with all kinds of heuristics. Then, it becomes the job of How to do that given the current constraints of LSP is, of course, an option question (especially, how to marry fuzz-matching scores with semantic scores). The simplest first step seems to just mark items with fully matched types as |
|
About your first question to be honest I just checked the GoPLS codebase https://github.com/golang/tools/blob/master/internal/lsp/completion.go#L111 Ok then for the first iteration I will make a struct CompletionScore {
is_precise_type_match: bool, // Only when it's the same type
is_precise_type_name_match: bool, // Only when it's a perfect match and in that case I put a preselect: true
}And then I will try to find some documentations about what the consequence of using |
|
Sounds good
…On Thu, 16 Apr 2020 at 15:32, Coenen Benjamin ***@***.***> wrote:
About your first question to be honest I just checked the GoPLS codebase
https://github.com/golang/tools/blob/master/internal/lsp/completion.go#L111
Ok then for the first iteration I will make a CompletionScore struct like
this:
struct CompletionScore {
is_precise_type_match: bool, // Only when it's the same type
is_precise_type_name_match: bool, // Only when it's a perfect match and in that case I put a preselect: true
}
And then I will try to find some documentations about what the consequence
of using sortText with filterText. Seems good for you ?
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#3954 (comment)>,
or unsubscribe
<https://github.com/notifications/unsubscribe-auth/AANB3M6C7QJJS5EGDMAZ4Y3RM4CHXANCNFSM4MGEQ6VQ>
.
|
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
|
Ok I made some changes with your advices. And here is screenshot in vscode to compare between current situation in RA and new situation with this PR. Current: New: In fact I only reorder completions with a score. If not it keeps the same behavior as before (seems to be an alphabetical sort by default). |


| self.score_option = Some(score_option); | ||
| } | ||
|
|
||
| pub(crate) fn compute_score(&mut self, ctx: &CompletionContext) { |
There was a problem hiding this comment.
Why do we need to delay the computation of scores until the end of completion process? A simpler approach seems to be to add a fully-computed score to CompletionItem.
There was a problem hiding this comment.
Yes I will move this part in completion_dot
crates/rust-analyzer/src/conv.rs
Outdated
| CompletionScore::TypeAndNameMatch => res.preselect = Some(true), | ||
| CompletionScore::TypeMatch => {} | ||
| } | ||
| res.sort_text = Some(format!("{:02}", ctx.2)); |
There was a problem hiding this comment.
I'd rather start with just setting preselect and void the sort_text hack. I belive setitng sort_text only for some fields would be wrong, and we also need to take fuzzy mathcing into account, if we set sort text. I think just preselect would give a meaningful improvement.
There was a problem hiding this comment.
If you have an example in mind in which case sort text could cause an issue let me know I will try. The fact is as a rust analyzer user I feel better with my example in sorted items. But of course I don’t want to introduce a bug or non deterministic behavior. So if you have examples on which I can make some tests I will be happy to try and show you the result. I agree with you, preselect is good but if we can’t go a step further using sortText as gopls does. Developer experience will be improved.
There was a problem hiding this comment.
By the way when I go to the LSP specs from Microsoft, when I look about documentation about sortText here it is A string that should be used when comparing this item with other items. When falsy the label is used. it seems it's not a hack. I mean, today we have all completion items sorted in alphabetical, which in my opinion, is very bad. IMHO I think we can't do something more bad because you always have to scroll the entire autocompletions list to see all interesting parameters of a struct for example. I think it really worth to at least show to the user fields with right types first + preselect perfect match. If we look at my screenshots there are keywords like box, dbg, ... displayed and at this place we don't care about it. In my example it's not so annoying because I have a lot of fields beginning with a letter so it's in first position and I don't have to scroll so much. If you are worried I can write a lot of tests, make a lot of experiments even manually and show you the results because I really think it worth.
xtask/tests/tidy-tests/main.rs
Outdated
| if line.chars().last().map(char::is_whitespace) == Some(true) { | ||
| panic!("Trailing whitespace in {}", path.display()) | ||
| panic!("Trailing whitespace in {} at line {}", path.display(), line_number) |
|
I believe that
If would show up as
It would be presented as
If either of those are missing I think there are vscode settings though that can alter the behavior and I don't know how they interact with the LSP. |
|
Yes sortText is used to sort completionItem and with my experiments it seems that it’s sorted by ascending so 0000 first and then 0001. |
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
| CompletionItem, | ||
| }; | ||
| use rustc_hash::FxHashSet; | ||
| // use std::cmp::Ordering; |
| @@ -285,6 +304,51 @@ impl Builder { | |||
| self.deprecated = Some(deprecated); | |||
| self | |||
| } | |||
| #[allow(unused)] | |||
There was a problem hiding this comment.
Because at this time I don't really use it. I just wanted to keep the same way than it was done with other fields. To stay consistent
| @@ -285,6 +304,51 @@ impl Builder { | |||
| self.deprecated = Some(deprecated); | |||
| self | |||
| } | |||
| #[allow(unused)] | |||
| pub(crate) fn compute_score(mut self, ctx: &CompletionContext) -> Builder { | |||
There was a problem hiding this comment.
I think this function should live in presentation.rs, and here we only need set_score
| items.into_iter().map(|item| item.conv_with((&line_index, line_endings))).collect(); | ||
| let items: Vec<CompletionItem> = items | ||
| .into_iter() | ||
| .enumerate() |
There was a problem hiding this comment.
Do we actually sort variants anywhere? ctrl+f sort gives no results
There was a problem hiding this comment.
I only use the index to order when there is a type match. I don't know if it answers your question
There was a problem hiding this comment.
Hm, I am not sure....
Like, we never sort completion items, so the indexes they get are arbitrary. So, when we set an index as a sort_text, we get arbitrary ordering?
There was a problem hiding this comment.
yes you're right. We don't care about the index here. In fact, what's is important is to have a kind of global counter. I also don't care about the order at this time. I just use this data as a counter. If it's weird to you I also can pass an &mut counter coming from this handle_completion function but I need to have a kind of global counter to not put the same number in sortText. And as for non scored item there isn't any sortText it's the default behavior as before then it doesn't change. Then in fact I could have a sortText set to 2 and the next one set to 4 but it's not so important. The only important thing is to have a incremental counter. I will change this to pass a &mut counter it should be easier to read I think :)
There was a problem hiding this comment.
I updated the variable to use counter instead of arbitrary index
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Signed-off-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
|
Is it good for you @matklad ? |
|
bors r+ I want to merge this as it has been seeting in the queue for far too long. That said, I want to tweak this a quite a bit after it lands -- I have a strong suspicion that current usages of |
|
Build succeeded: |
7904: Improved completion sorting r=JoshMcguigan a=JoshMcguigan I was working on extending #3954 to apply completion scores in more places (I'll have another PR open for that soon) when I discovered that actually completion sorting was not working for me at all in `coc.nvim`. This led me down a bit of a rabbit hole of how coc and vs code each sort completion items. Before this PR, rust-analyzer was setting the `sortText` field on completion items to `None` if we hadn't applied any completion score for that item, or to the label of the item with a leading whitespace character if we had applied any completion score. Completion score is defined in rust-analyzer as an enum with two variants, `TypeMatch` and `TypeAndNameMatch`. In vs code the above strategy works, because if `sortText` isn't set [they default it to the label](microsoft/vscode@b4ead4e). However, coc [does not do this](https://github.com/neoclide/coc.nvim/blob/e211e361475a38b146a903b9b02343551c6cd372/src/completion/complete.ts#L245). I was going to file a bug report against coc, but I read the [LSP spec for the `sortText` field](https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion) and I feel like it is ambiguous and coc could claim what they do is a valid interpretation of the spec. Further, the existing rust-analyzer behavior of prepending a leading whitespace character for completion items with any completion score does not handle sorting `TypeAndNameMatch` completions above `TypeMatch` completions. They were both being treated the same. The first change this PR makes is to set the `sortText` field to either "1" for `TypeAndNameMatch` completions, "2" for `TypeMatch` completions, or "3" for completions which are neither of those. This change works around the potential ambiguity in the LSP spec and fixes completion sorting for users of coc. It also allows `TypeAndNameMatch` items to be sorted above just `TypeMatch` items (of course both of these will be sorted above completion items without a score). The second change this PR makes is to use the actual completion scores for ref matches. The existing code ignored the actual score and always assumed these would be a high priority completion item. #### Before Here coc just sorts based on how close the items are in the file.  #### After Here we correctly get `zzz` first, since that is both a type and name match. Then we get `ccc` which is just a type match. 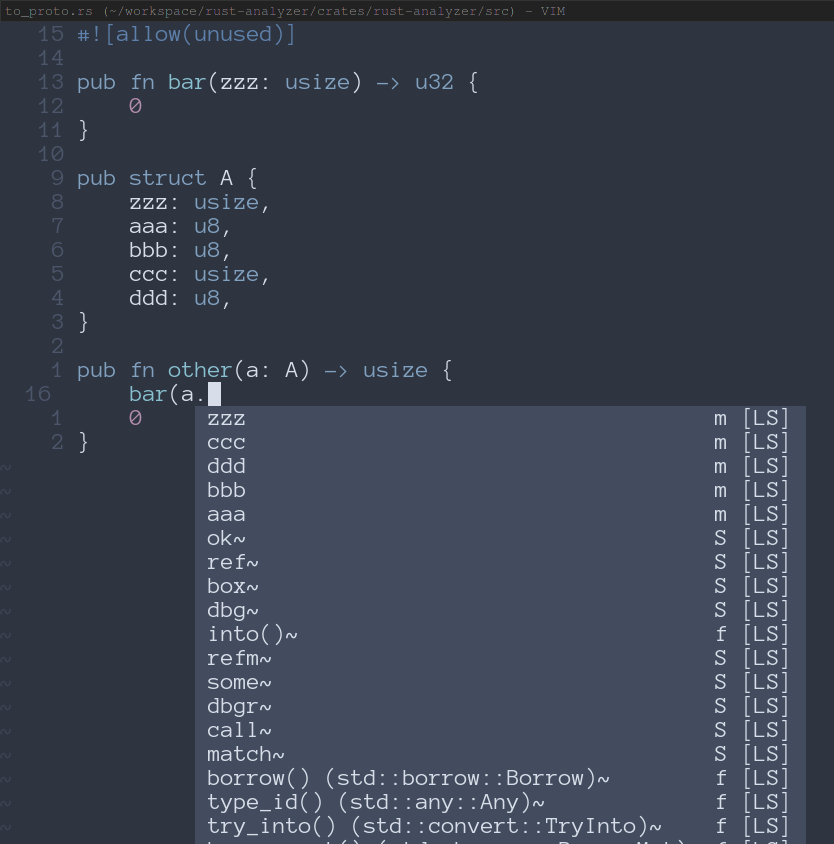 Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
{kind=link}
{kind=link}
This tweet (https://twitter.com/tjholowaychuk/status/1248918374731714560) gaves me the idea to implement that in rust-analyzer.
Basically for this first example I made some examples when we are in a function call definition. I look on the parameter list to prioritize autocompletions for the same types and if it's the same type + the same name then it's displayed first in the completion list.
So here is a draft, first step to open a discussion and know what you think about the implementation. It works (cf tests) but maybe I can make a better implementation at some places. Be careful the code needs some refactoring to be better and concise.
PS: It was lot of fun writing this haha