| nearest neighbors of frog |
Litoria | Leptodactylidae | Rana | Eleutherodactylus |
|---|---|---|---|---|
| Pictures |  |
 |
 |
 |
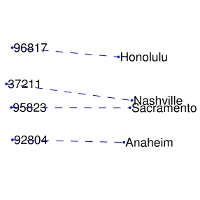
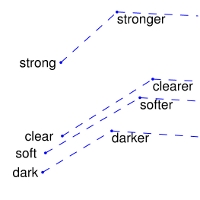
| Comparisons | man -> woman | city -> zip | comparative -> superlative |
|---|---|---|---|
| GloVe Geometry | 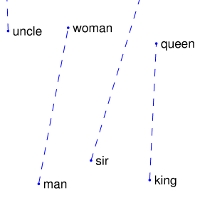 |
 |
 |
We provide an implementation of the GloVe model for learning word representations, and describe how to download web-dataset vectors or train your own. See the project page or the paper for more information on glove vectors.
NB: We evaluated this trained vectors with common-countries-bn.txt & family-bn.txt(inside eval/question-data-bn) question data. and Accuracy is 34%
In next version we will create a better question data for evaluation and will publish final evaluation result.
-
wikipedia+crawl_news_articles (39M(39055685) tokens, 0.18M(178152) vocab size, 195.4MB download):
bn_glove.39M.300d.zip -
wikipeida+crawl_news_articles (39M(39055685) tokens, 0.18M(178152) vocab size, 100d vectors, 65MB download):
bn_glove.39M.100d.zip -
Wikipedia (20M(19965328) tokens, 0.13M(134255) vocab, 300d vectors, 145.9MB download):
bn_glove.300d.zip -
Wikipedia (20M(19965328) tokens, 0.13M(134255), 100d vectors, 51.2MB download):
bn_glove.100d.zip
python test.py

If the web datasets above don't match the semantics of your end use case, you can train word vectors on your own corpus.
$ git clone http://github.com/stanfordnlp/glove
$ cd glove && make
$ ./demo.sh
The demo.sh script downloads a small corpus, consisting of the first 100M characters of Wikipedia. It collects unigram counts, constructs and shuffles cooccurrence data, and trains a simple version of the GloVe model. It also runs a word analogy evaluation script in python to verify word vector quality. More details about training on your own corpus can be found by reading demo.sh or the src/README.md
python eval/python/evaluate.py \
--vocab_file /path/vocab.txt
--vectors_file /path/vectors.txt
All work contained in this package is licensed under the Apache License, Version 2.0. See the include LICENSE file.







