-
Challenge paper: Skin Lesion Analysis Toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (ISIC) (https://arxiv.org/pdf/1902.03368.pdf)
-
Dataset: Skin Cancer MNIST: HAM10000 (https://www.kaggle.com/kmader/skin-cancer-mnist-ham10000?select=hmnist_28_28_L.csv)
Submit automated predictions of disease classification within dermoscopic images.
Possible disease categories are:
- Melanoma
- Melanocytic nevus
- Basal cell carcinoma
- Actinic keratosis / Bowen’s disease (intraepithelial carcinoma)
- Benign keratosis (solar lentigo / seborrheic keratosis / lichen planus-like keratosis)
- Dermatofibroma
- Vascular lesion

The lesion images come from the HAM10000 Dataset, and were acquired with a variety of dermatoscope types, from all anatomic sites (excluding mucosa and nails), from a historical sample of patients presented for skin cancer screening, from several different institutions. Images were collected with approval of the Ethics Review Committee of University of Queensland (Protocol-No. 2017001223) and Medical University of Vienna (Protocol-No. 1804/2017).
The distribution of disease states represent a modified “real world” setting whereby there are more benign lesions than malignant lesions, but an over-representation of malignancies.
Principal Component Analysis (PCA), is a dimensionality-reduction method that is often used to reduce the dimensionality of large data sets, by transforming a large set of variables into a smaller one that still contains most of the information in the large set.
Because smaller data sets are easier to explore and visualize and make analyzing data much easier and faster for machine learning algorithms without extraneous variables to process.
So to sum up, the idea of PCA is simple — reduce the number of variables of a data set, while preserving as much information as possible.
where
Imbalanced Dataset: If there is the very high different between the positive values and negative values. Then we can say our dataset in Imbalance Dataset. In general is an unequal distribution of classes within a dataset.
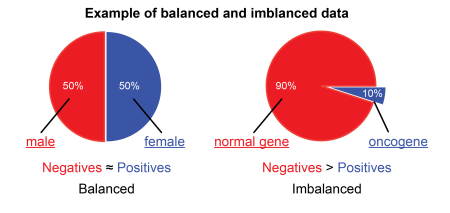
There is a big problem with imbalanced datasets, the model trained on that dataset are biased.
- Good performances on a specific class (most examples in the dataset)
- Bad performances in other classes
- No generalization
-
Undersampling is the process where you randomly delete some of the observations from the majority class in order to match the numbers with the minority class.
-
Oversampling process is a little more complicated than undersampling. It is the process of generating synthetic data that tries to randomly generate a sample of the attributes from observations in the minority class. There are a number of methods used to oversample a dataset for a typical classification problem.

{kind=link}
In our project we use both Oversampling and Undersampling with a specific pipeline:
-
RandomUnderSampler (Undersampling): decreasing to K the number of examples of the class with more examples (CLASS 1).
-
RandomOverSampling (Oversampling): increase to K the number of small classes.
The most easy undersampling method, we remove at random examples from the class with more examples.
In this method we generate new examples. We sample randomly examples from the same class to augment the number of class examples. We adopt a data augmentation strategy to avoid data redundancy derived from this method (we see it later).
We investigate our case study using different Machine Learning models. We start from a dummy baseline model that use a random function to predict the outcomes. Then we experiments the following models:
-
TRADITIONAL ML MODELS
- Softmax regression
- Support Vector Machine
-
DEEP LEARNING
- Convolutional Neural Network
-
ENSEMBLE LEARNING (BOOSTING)
- XGBoosting algorithm
We perform model selection step basing on model performances over our validation set using the grid search algorithm to find the best hyperpameters configuration.
We use different training dataset in order to investigate the balance data importance and the data augmentation effort to our task.
Balanced Multi-class Accuracy
BACC =
| Model | Balanced multi-class accuracy |
|---|---|
| Competition Winner | 84.50% |
| 40° model | 65.50% |
| CNN | 60.81% |
| Logistic Regression | 50.23% |
| XGBoosting | 48.85% |
| SVM | 14.28% |
- Samir Salman
- Simone Giorgioni