compressed_streamlit_video_text_classification.mp4
This is a project developed to create a code template and to understand different text classification techniques. This project includes different training notebooks to create different kind of text classification models. This project also includes a code to make productionaized text classification api using standard practices in MLOps.
The models are developed on very small data.
- collect,clean,annotate text data
- implement different methods of text classification models
- build inference api
- create streamlit application
- write unit test cases and performance test cases
- code documentation
- code formatting
- code deployment using docker and circleci
- pre-commit hooks
This code can be used for end to end text classification project development as well as deployment.
If you are only looking to learn/use model building techniques,directly jump to notebooks:
1.Text Classification using TF-IDF and Pycaret
2.Text Classification using TF-IDF and custom Machine Learning
3.Text Classification using TF-IDF and custom Neural network using Keras
4.Text Classification using distilbert embeddings and custom Machine Learning
5.Text Classification using distilbert embeddings and Neural network using Pytorch
6.Text Classification using distilbert embeddings and Neural Network using huggging face trainer api
7.Text Classification using sentence transformer embeddings and custom neural network using Pytorch
The basic code template for this project is derived from my another repo code template
The project considers following phases in ML project development lifecycle:
Requirement
Data Collection
Model Building
Inference
Testing
Deployment
We have not considered model evaluation and monitoring.
Create a text classification api which accepts a news article or a sentence from news article and classifies it into POSITIVE, NEGATIVE or NEUTRAL sentiment.
News article data is collected by refering my another repo news api.
Then sample 100 sentences annotated using doccano,a data annotation tool. Please note that since this is just a demo project,we have not used huge data. We have used only 100 sentences. In reality,data might be huge and any other data annotation technique can be used.
Input vectors used : TF-IDF, word embeddings from distilbert,word embeddings from sentence transformer
Model techniques used : Custom ML using sklearn,Custom Neural Network using keras,Custom Neural Network using pytorch, Custom Neural Network using hugging face transformers trainer api
Using combinations of above we have created 7 different models:
| Input vectors | Model | Library | Model_Name |
|---|---|---|---|
| TF-IDF | Best model from pycaret | Pycaret | tfidf_pycaret |
| TF-IDF | ML model by experiments | sklearn | tfidf_custom_ml |
| TF-IDF | Custom neural network | Keras | tfidf_custom_dl_keras |
| Distilbert embeddings | ML model by experiments | sklearn,transformers | embedding_custom_ml |
| Distilbert embeddings | Custom neural network | Pytorch,transformers | embedding_custom_dl |
| Distilbert embeddings | transformers neural network | Pytorch,transformers | embedding_hugging_face |
| sentence transformer embeddings | Custom neural network | Pytorch,sentence_transformer | embedding_sentence_transformer_custom_dl |
You can try different combinations by creating/updating training notebooks of these models.
There are 2 ways to deploy this application.
- API using FastAPI.
- Streamlit application
Unit test cases are written
Deployment is done locally using docker.
Like any production code,this code is organized in following way:
- Keep all Requirement gathering documents in docs folder.
- Keep Data Collection and exploration notebooks in src/training folder. data_cleaning.ipynb, data_collection_eda.ipynb
- Keep datasets in data folder.
Raw data kept in raw_data csv. Cleaned paragraphs stored in paragraph_clean_data.csv
Cleaned sentencesstored in sentences_clean_data.csv
Actual training done on 100_sentiment_analysis_sentences.csv - Keep model building notebooks at src/training folder.
- Keep generated model files at src/models.
- Write and keep inference code in src/inference.
- Write Logging and configuration code in src/utility.
- Write unit test cases in tests folder.pytest,pytest-cov
- Write performance test cases in tests folder.locust
- Build docker image.Docker
- Use and configure code formatter.black
- Use and configure code linter.pylint
- Add Git Pre-commit hooks.
- Use Circle Ci for CI/CD.Circlci
Clone this repo locally and add/update/delete as per your requirement.
Since we have used different design patterns like singleton,factory.It is easy to add/remove model to this code. You can remove code files for all models except the model which you want to keep as a final.
Please note that this template is in no way complete or the best way for your project structure.
This template is just to get you started quickly with almost all basic phases covered in creating production ready code.
├── README.md <- top-level README for developers using this project.
├── pyproject.toml <- black code formatting configurations.
├── .dockerignore <- Files to be ognored in docker image creation.
├── .gitignore <- Files to be ignored in git check in.
├── .pre-commit-config.yaml <- Things to check before git commit.
├── .circleci/config.yml <- Circleci configurations
├── .pylintrc <- Pylint code linting configurations.
├── Dockerfile <- A file to create docker image.
├── environment.yml <- stores all the dependencies of this project
├── main.py <- A main file to run API server.
├── main_streamlit.py <- A main file to run API server.
├── src <- Source code files to be used by project.
│ ├── inference <- model output generator code
│ ├── model <- model files
│ ├── training <- model training code
│ ├── utility <- contains utility and constant modules.
├── logs <- log file path
├── config <- config file path
├── data <- datasets files
├── docs <- documents from requirement,team collabaroation etc.
├── tests <- unit and performancetest cases files.
│ ├── cov_html <- Unit test cases coverage report
Development Environment used to create this project:
Operating System: Windows 10 Home
Anaconda:4.8.5 Anaconda installation
Go to location of environment.yml file and run:
conda env create -f environment.yml
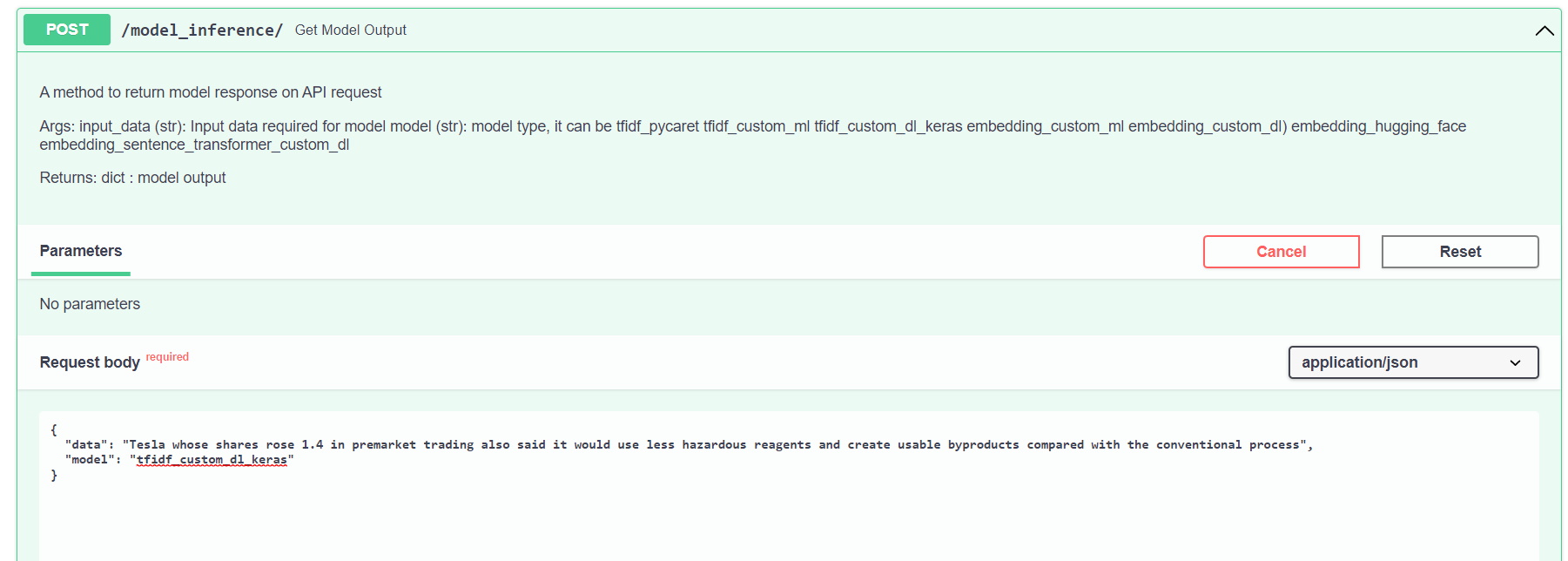
Here we have created ML inference on FastAPI server with dummy model output.
- Go inside 'text_classification_api' folder on command line.
Run:
conda activate text_classification_api
python main.py
Open 'http://localhost:5000/docs' in a browser.

- Or to start Streamlit application
- Run:
conda activate text_classification_api
streamlit run main_streamlit.py
- Go inside 'tests' folder on command line.
- Run:
pytest -vv
pytest --cov-report html:tests/cov_html --cov=src tests/
- Open 2 terminals and start main application in one terminal
python main.py
- In second terminal,Go inside 'tests' folder on command line.
- Run:
locust -f locust_test.py
- Go inside 'text_classification_api' folder on command line.
- Run:
black src
- Go inside 'text_classification_api' folder on command line.
- Run:
pylint src
- Go inside 'text_classification_api' folder on command line.
- Run:
docker build -t myimage .
docker run -d --name mycontainer -p 5000:5000 myimage
- Go inside 'text_classification_api' folder on command line.
- Run:
pre-commit install
- Whenever the command git commit is run, the pre-commit hooks will automatically be applied.
- To test before commit,run:
pre-commit run
- Add project on circleci website then monitor build on every commit.
1.embedding_custom_dl,embedding_hugging_face models are not checked in because of size,you can generate them by running corresponding training notebook.
2.You'll need to create news api key to get news data,so create and update api key in data_collection notebook.
Please create a Pull request for any change.
NOTE: This software depends on other packages that are licensed under different open source licenses.