ソース:
"CircuitBreaker"
http://martinfowler.com/bliki/CircuitBreaker.html by Martin Fowler
ソフトウェア・システムでは、まったくの別プロセスやネットワーク越しの別マシンで実行されているソフトウェアに対してリモート・コールすることがよく起こります。
インメモリへのコールとリモート・コールとの大きな違いは、リモート・コールはフェイルしたり、レスポンスのないまま一定時間ハングしてしまうケースがあることです。
レスポンスを返さないサプライヤへ大量にコールしたせいで、重篤なリソース不足を招き、システム間でフェイルの連鎖を誘発させてしまうと最悪です。
Michael Nygard 氏は "Release It" という卓越した著書のなかで、こうした致命的なフェイルの連鎖を防ぐために「サーキット・ブレーカー」というパターンを推奨しています。
サーキット・ブレーカーという発想のベースにあるアイデアはとてもシンプルです。
プロテクテッドなコール関数をサーキット・ブレーカー・オブジェクトにラップし、そのオブジェクトがコールの結果をモニタリングするのです。
フェイルした回数が閾値に達したら、サーキット・ブレーカーはトリップしてそれ以降のコールをエラーとして返します。
リモートへのプロテクテッドなコールは一切発生しません。通常であれば、サーキット・ブレーカーのトリップが発生したらアラートが欲しいところでしょう。
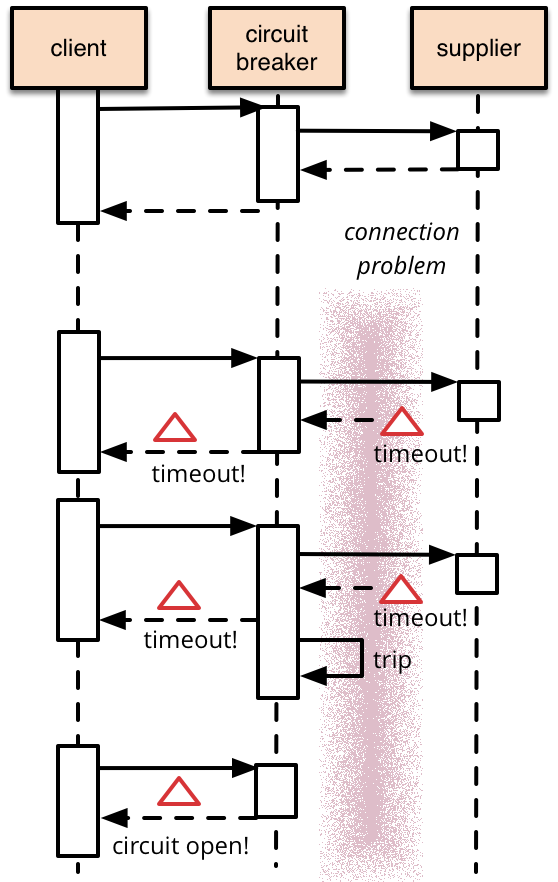
以下は、サーキット・ブレーカーのビヘイビアを Ruby で実装したサンプルです。タイムアウトしたらプロテクトします。
ブロック(Lambda)を引数にして、ブレーカーをセットアップします。このブロックがプロテクテッドなコールに相当します。
cb = CircuitBreaker.new {|arg| @supplier.func arg}
ブレーカーはブロックを保存して、いろいろなパラメータ(閾値、タイムアウト、モニタリング)を初期化します。そして「クローズド」な状態に設定します。
class CircuitBreaker...
attr_accessor :invocation_timeout, :failure_threshold, :monitor
def initialize &block
@circuit = block
@invocation_timeout = 0.01
@failure_threshold = 5
@monitor = acquire_monitor
reset
end
サーキット・ブレーカーにコールがあると、状態がクローズドならブロックが呼ばれ、オープンならエラーになります。
# client code
aCircuitBreaker.call(5)
class CircuitBreaker...
def call args
case state
when :closed
begin
do_call args
rescue Timeout::Error
record_failure
raise $!
end
when :open then
raise CircuitBreaker::Open
else
raise "Unreachable Code"
end
end
def do_call args
result = Timeout::timeout(@invocation_timeout) do
@circuit.call args
end
reset
return result
end
タイムアウトが発生した、フェイルカウントをインクリメントしてきます。コールに成功したらフェイルカウントをゼロにリセットします。
class CircuitBreaker...
def record_failure
@failure_count += 1
@monitor.alert(:open_circuit) if :open == state
end
def reset
@failure_count = 0
@monitor.alert :reset_circuit
end
ブレーカの状態はフェイルカウントと閾値を比較して決定します。
class CircuitBreaker...
def state
(@failure_count >= @failure_threshold) ? :open : :closed
end
このようなシンプルなサーキット・ブレーカーの実装では、サーキットがオープンならプロテクテッドなコールを遮断しますが、復旧時の状態リセットには外部からの別操作が必要になるかもしれません。
物理的なビルの電気的なサーキット・ブレーカー(遮断機)であればそうした操作ももっともでしょうが、ソフトウェアに関して言えばブレーカー自身に復旧を検知させることができます。
妥当な間隔をおいて、プロテクテッドなコールを再実行し、成功であればブレーカーをリセットするような自己回復的なビヘイビアを実装することができます。
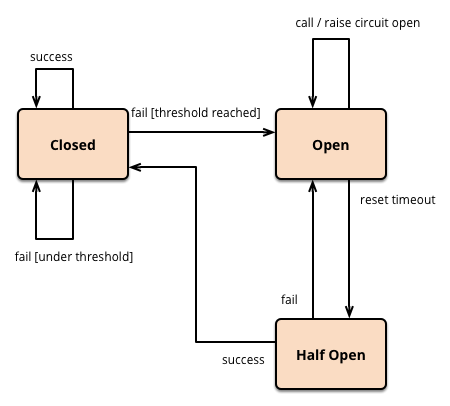
自己回復的なブレーカーに必要なのは、リセットを試行するための閾値の追加と、直近のエラーが発生した時刻を保持する変数への代入です。
class ResetCircuitBreaker...
def initialize &block
@circuit = block
@invocation_timeout = 0.01
@failure_threshold = 5
@monitor = BreakerMonitor.new
@reset_timeout = 0.1
reset
end
def reset
@failure_count = 0
@last_failure_time = nil
@monitor.alert :reset_circuit
end
ここで3つめの状態ーハーフ・オープンーが現れます。 ハーフ・オープンな状態のとき、サーキットは実際のコールを、問題が落ち着いたかチェックする試行として受け付けます。
class ResetCircuitBreaker...
def state
case
when (@failure_count >= @failure_threshold)
&& (Time.now - @last_failure_time) > @reset_timeout
:half_open
when (@failure_count >= @failure_threshold)
:open
else
:closed
end
end
ハーフ・オープン状態のときのコールは、そのコールが成功したらブレーカーをリセットする、失敗ならタイムアウトを巻き戻す、そのいずれかを試行します。
class ResetCircuitBreaker...
def call args
case state
when :closed, :half_open
begin
do_call args
rescue Timeout::Error
record_failure
raise $!
end
when :open
raise CircuitBreaker::Open
else
raise "Unreachable"
end
end
def record_failure
@failure_count += 1
@monitor.alert(:open_circuit) if :open == state
@last_failure_time = Time.now
end
上に紹介した例は、あくまで説明向けの素朴な実装です。
実際のサーキット・ブレーカーにはもっとたくさんのフィーチャが実装され、パラメータ化が施されるはずです。
プロテクテッドなコールがライズするエラーの種別、例えばネットワーク接続エラーなど、どこまでのエラーをプロテクトすべきか考慮することでしょう。
すべてのエラーに対してサーキットをトリップすべきではありません。
中には想定内のエラーも含まれるますので、そういったエラーは通常のロジックで処理したほうが無難です。
トラフィックが増えてくると、初期の閾値でタイムアウトしてしまうコールの増加に悩まされるかもしれません。
リモート・コールはよく遅くなるので、コールごとにスレッドを分けて実行するというアイデアは使えるでしょう。
その際、"future or promise" を利用して各スレッドの戻りの結果をハンドルしてやります。
スレッドプールからスレッドを取り出していくと、いつかスレッドプールが枯渇します。
そのときにサーキットを遮断するというアレンジができます。
例では、ブレーカーをトリップさせるシンプルな方法を紹介しました。
コールが成功ならカウントをリセットします。
もうすこし洗練されたアプローチでは、トリップが一度発生すると失敗率 50% といったように、エラー発生頻度をベースにできるかもしれません。
また、エラーごとに異なる閾値をもたせるといったアプローチもあるでしょう。
例えば、タイムアウトであれば閾値 10、接続障害なら閾値 3 といった具合です。
例では、サーキット・ブレーカーを同期的に呼び出していますが、非同期なやりとりでもサーキット・ブレーカーは使えます。
非同期の一般的なテクニックでは、すべてのリクエストをキューに入れます。
サプライヤーは自分のペースでリクエストをコンシュームするので、サーバのオーバーロードを防ぐ有効なテクニックのひとつです。
サーキット・ブレーカーは、フェイルしそうなオペレーションに割かれるリソースを削減してくれます。
タイムアウトするまでクライアントを待たせずに済みますし、サーキットを遮断することで処理に四苦八苦しているサーバへの負荷をカットできます。
ここまではサーキット・ブレーカーの使いどころとして、一般的に知られるリモート・コールに絞ってお話ししてきましたが、システムのある部分を他の部分で発生した問題からプロテクトするシチュエーションであれば、大概はサーキット・ブレーカーが使えます。
サーキット・ブレーカーは、モニタリングのための貴重な場所になります。 ブレーカーの状態遷移をすべてログに残し、詳細な出力結果からより深いモニタリングにつなげます。 ブレーカーのビヘイビアは、より深刻な環境上のトラブルの兆候を知るための有益な情報源です。 オペレーション・スタッフはサーキットのトリップかブレーカーのリセットはできたほうがよいでしょう。
ブレーカーはそれ自体でも価値があるのですが、リクエスト・エラーに対してクライアントはどう対応すべきか、その判断にもおいても貴重です。
実行中のオペレーションが失敗したら、何らかのワークアラウンドが可能なのか考えてみてください。
クレジットカード認証のリクエストは、いったんキューに入れて時間をおいて処理できるかもしれませんし、あるデータが取得できなかったときは、前回取得したデータを表示することで失敗を緩和できるかもしれません。
Netflix の技術ブログには、多くの外部サービスと連携するシステムの信頼性を高めるための方策について、有益な情報が数多く掲載されています。 なかでも、"Fault Tolerance in a High Volume, Distributed System" というポストで、サーキット・ブレーカーとスレッド・プール・リミットに触れられています。
Netflix は Hystrix という分散環境のためのレイテンシとフォールトトレラントを制御する洗練されたツールをオープンソースで公開しています。 そこには、スレッド・プール・リミットによるサーキット・ブレーカー・パターンの実装が含まれています。
他にも、Ruby, Java, Grails Plugin, C#, AspectJ, Scala によるオープンソースなサーキット・ブレーカー・パターンの実装があります。