EFF Speed-up MiniBatchDictionaryLearning by avoiding multiple validation #25493
Conversation
|
Side note: adding this config option would make me much more confident in keeping adding param validation for public functions because we'd have a solution to bypass it where we do call such function within our code base |
|
Irrespective of the minibatch dictionary learning case and the potentially expensive future parameter checks, |
|
Can you please add a changelog entry to document this new option? |
sklearn/_config.py
Outdated
| @@ -134,6 +136,12 @@ def set_config( | |||
|
|
|||
| .. versionadded:: 1.2 | |||
|
|
|||
| skip_parameter_validation : bool, default=None | |||
| If True, parameter validation of public estimators and functions will be | |||
There was a problem hiding this comment.
For me it wasn't immediately clear what "parameter validation of public estimators and functions" covers and what it doesn't covers. After a look at the code I think it only covers the constructor arguments of estimators and the arguments passed to functions. Where as before I looked at the code I thought it might also disable validation of the input data (I think it doesn't really do that).
So I was thinking about alternative sentences. Here a few ideas. Maybe you like some of them or we can combine them.
- If True, disable the validation of estimator's hyper-parameters and arguments to helper functions. This can be useful for very small inputs, but it can lead to crashes.
- If True, disable the validation of the hyper-parameter values of estimators and arguments passed to other functions. This can be useful in situations like small input data, but it can also lead to misconfigurations going undetected.
There was a problem hiding this comment.
I adapted the description to be more explicit about what kind of validation is disabled. I did not keep the like small input data part because it can be problematic even with large data if you have validation in a loop that processes samples one at a time for instance.
There was a problem hiding this comment.
Sounds good. In my head I had implicitly set "dataset size == number of samples passed to predict", so the case you described is part of that. However, we have at least N=1 data that this "obvious" assumption isn't obvious to everyone :D So I'm ok with this. (I can't mark this as resolved, but if I could I would)
There was a problem hiding this comment.
"dataset size == number of samples passed to predict",
What I meant is that here predict might call a public function for each sample which would be catastrophic
There was a problem hiding this comment.
Overall, there has been three ways to get around parameter validation:
- Creating a private function without validation and use it when we do not need validation.
- Add a
check_parameterskeyword argument everywhere. - Add a global configuration. (This PR)
After years of doing option 1, I am preferring option 3 (this PR).
I kind of arrived to the same conclusion. Option 1 becomes a nightmare when you have functions calling other functions in cascade and you want to keep a public version of each of these functions... I still think that it's a good thing to have a separation, not public/private this time but more boilerplate/algorithm. I often find that the validation/preparation and the core computational part of an algorithm are too intricate in our functions, making them hard too read and understand. So overall I think option 3 is more appropriate to easily avoid unnecessary overhead, but option 1 is still on the table, when used reasonably, to have a more modular and maintainable code base. |
There was a problem hiding this comment.
See comments below. Other than that, can you please add a few smoke tests that check that it's possible to call a @validate_params decorated function and an estimator fit with disabled parameter validation and still get the same outcome as the original function / call or estimator fit?
I don't think we need a common test for this. Just a test for an arbitrary choice of validated function and estimator would be enough.
| with config_context(assume_finite=True, skip_parameter_validation=True): | ||
| batch_cost = self._minibatch_step( | ||
| X_batch, dictionary, self._random_state, i | ||
| ) |
There was a problem hiding this comment.
#25490 only gets rid of 1 layer of validation (there are 4 validations in total) so even if it gets merged, we'll still need the context manager around the _minibatch_step.
sklearn/_config.py
Outdated
| If True, disable the validation of the hyper-parameters of estimators and | ||
| arguments passed to public functions. It can save time in some situations but | ||
| can lead to potential crashes. |
There was a problem hiding this comment.
| If True, disable the validation of the hyper-parameters of estimators and | |
| arguments passed to public functions. It can save time in some situations but | |
| can lead to potential crashes. | |
| If True, disable the validation of the hyper-parameters values in the fit | |
| method of estimators and for arguments passed to public functions. It can | |
| save time in some situations but can lead to low level crashes and | |
| exceptions with confusing error messages. |
|
I like the technique of using One thing that I am not sure what to think of is that a library that changes the user provided configuration at runtime feels a little like a Python script that modifies its I was thinking the same when reading #25617 (comment), my first reaction is that the library shouldn't be enabling array dispatching because it is a configuration flag that is "controlled by the user". What do others think on this topic? Related to my earlier comment: I think the flag introduced in this PR only effects the validation of the constructor parameters (things that can be set via |
The phrasing changed a little bit. Let me know if it's clearer. |
| @@ -134,6 +136,14 @@ def set_config( | |||
|
|
|||
| .. versionadded:: 1.2 | |||
|
|
|||
| skip_parameter_validation : bool, default=None | |||
| If True, disable the validation of the hyper-parameters types and values in the | |||
| fit method of estimators and for arguments passed to public helper functions. | |||
There was a problem hiding this comment.
I think it's important to state that check_array still runs:
For data parameters, such as
Xandy, only type validation is skipped and validation withcheck_arraywill continue to run.
|
I opened an alternative PR #25815 to go beyond this one and disable inner validation in a general manner. |
Alternative to #25490
MinibatchDictionaryLearning calls public functions that call public classes themselves. We end up validating the parameters and the input/dict twice per minibatch. When the batch size is large it has barely no impact but for small batch sizes it can be very detrimental.
For instance, here's a profiling result in the extreme case batch_size=1
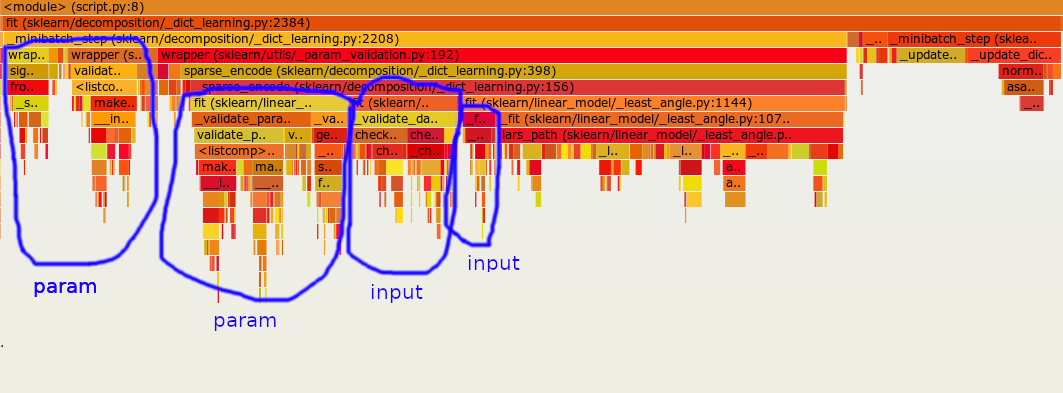
This PR proposes to add a new config that allows to disable parameter validation. It has the advantage over #25490 that it does not involve any refactoring and can be useful in other places where we call public functions/classes within estimators.
For the input validation I just set the assume finite config. It's the most costly part of check_array. It's good enough for now but it leaves some overhead still and in the end I think we could add a config to disable check_array entirely (we have some check_input args in some places but I think a config option would be more convenient).
Here's the profiling result with this PR

There's still some overhead from check_array but it's a lot more reasonable