FEAT Large Margin Nearest Neighbor implementation #8602
Conversation
…l for really old scipy.optimize.fmin_l_bfgs_b
|
Hi all! I've been trying to nail down why some travis tests fail and I think it is a bug coming from an old scipy version of fmin_l_bfgs_b. I've opened an issue there ( scipy/scipy#7196 ). Apart from that, the rest of my pull request was passing all other tests. On my last commit, it seems like one appveyor test is now failing on something completely unrelated to my code, namely on sklearn.decomposition.tests.test_pca.test_singular_values. (https://ci.appveyor.com/project/raghavrv/scikit-learn/build/1.0.217/job/iittcikl6hic3bdg). Am I missing something? |
|
From the last commit+builds, I can confirm that the failing travis tests are isolated and caused by this old scipy version of |
|
Sorry I don't have much time to handle this. Usually we would backport functionality from a later version for users that have an older supported version by adding something in |
|
I used this package when playing with metrics learning. |
|
I suppose the main problem is that including one invites many, hence
maintainability problems. Yes, I had previously been aware of metric-learn.
I'm inclined to agree that: (a) this may make more sense as a transformer
than a classifier; and (b) we should ascertain that this is (one of) the
most appropriate metric learner for inclusion. metric-learn's
implementation looks markedly different, but I've not looked into it.
…On 19 March 2017 at 21:34, Guillaume Lemaitre ***@***.***> wrote:
I used this package <https://github.com/all-umass/metric-learn> when
playing with metrics learning.
I don't know if it would be interesting to actually have a module in
sklearn?
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
<#8602 (comment)>,
or mute the thread
<https://github.com/notifications/unsubscribe-auth/AAEz634Z9QfNbtGIFRZPKj9VteqHPlCDks5rnQTPgaJpZM4MgC9Y>
.
|
|
One of the big difference between this model and actual metric learning
models is that shoe-horning standard metric learning in the scikit-learn
API is hard (typically, they work by learning on pair of instances that
are specified as similar or not). This model fits naturally in the
scikit-learn API. For this reason, I am quite enthousiastic about having
it in scikti-learn: it would enables basic metric learning with
scikit-learn, and there is a lot of value to this.
|
There was a problem hiding this comment.
Hi @johny-c and happy new year to you too! Thanks a lot for your effort!
Your PR is labeled for review now. Let's wait one or two days before pinging.
In the meanwhile I have checked the examples (nice figures indeed!): they throw some warnings. Also, we are moving examples (one step at the time) to a notebook-style to make them more readable (see for example this one), if you have some time to reorganize them, I think this could improve understanding.
Thanks again for your patience!
| An example comparing nearest neighbors classification with and without | ||
| Large Margin Nearest Neighbor. |
There was a problem hiding this comment.
What about
"This example compares nearest neighbors...."
| # Put the result into a color plot | ||
| Z = Z.reshape(xx.shape) | ||
| plt.figure() | ||
| plt.pcolormesh(xx, yy, Z, cmap=cmap_light, alpha=.8) |
There was a problem hiding this comment.
Checking the rendered example this line produce a DeprecationWarning
/home/circleci/project/examples/neighbors/plot_lmnn_classification.py:75: MatplotlibDeprecationWarning: shading='flat' when X and Y have the same dimensions as C is deprecated since 3.3. Either specify the corners of the quadrilaterals with X and Y, or pass shading='auto', 'nearest' or 'gouraud', or set rcParams['pcolor.shading']. This will become an error two minor releases later.
plt.pcolormesh(xx, yy, Z, cmap=cmap_light, alpha=.8)
/home/circleci/project/examples/neighbors/plot_lmnn_classification.py:75: MatplotlibDeprecationWarning: shading='flat' when X and Y have the same dimensions as C is deprecated since 3.3. Either specify the corners of the quadrilaterals with X and Y, or pass shading='auto', 'nearest' or 'gouraud', or set rcParams['pcolor.shading']. This will become an error two minor releases later.
plt.pcolormesh(xx, yy, Z, cmap=cmap_light, alpha=.8)
Do you mind fixing it? Thanks!
| Dimensionality Reduction with Large Margin Nearest Neighbor | ||
| =========================================================== | ||
|
|
||
| Sample usage of Large Margin Nearest Neighbor for dimensionality reduction. |
There was a problem hiding this comment.
Perhaps this sentence has become redundant now?
| lmnn = LargeMarginNearestNeighbor(n_neighbors=n_neighbors, n_components=2, | ||
| max_iter=20, verbose=1, | ||
| random_state=random_state) |
There was a problem hiding this comment.
The rendered example shows a ConvergenceWarning, do you think it could be possible to fix it without increasing too much the execution time?
There was a problem hiding this comment.
When running the file locally, I get the following error that seems to be coming from joblib:
File "plot_lmnn_dim_reduction.py", line 53, in <module>
faces = datasets.fetch_olivetti_faces()
File "/work/chiotell/projects/scikit-learn/sklearn/utils/validation.py", line 63, in inner_f
return f(*args, **kwargs)
File "/work/chiotell/projects/scikit-learn/sklearn/datasets/_olivetti_faces.py", line 120, in fetch_olivetti_faces
faces = joblib.load(filepath)
File "/home/johny/soft/miniconda3/envs/scikit/lib/python3.6/site-packages/joblib/numpy_pickle.py", line 585, in load
obj = _unpickle(fobj, filename, mmap_mode)
File "/home/johny/soft/miniconda3/envs/scikit/lib/python3.6/site-packages/joblib/numpy_pickle.py", line 504, in _unpickle
obj = unpickler.load()
File "/home/johny/soft/miniconda3/envs/scikit/lib/python3.6/pickle.py", line 1050, in load
dispatch[key[0]](self)
File "/home/johny/soft/miniconda3/envs/scikit/lib/python3.6/pickle.py", line 1338, in load_global
klass = self.find_class(module, name)
File "/home/johny/soft/miniconda3/envs/scikit/lib/python3.6/pickle.py", line 1388, in find_class
__import__(module, level=0)
ModuleNotFoundError: No module named 'sklearn.externals.joblib.numpy_pickle'
I tried with multiple versions of joblib from 0.12.2 to 1.0 and the same error appears. Any ideas?
There was a problem hiding this comment.
I can't reproduce the error neither with python 3.9 or 3.6 ... have you tried to clean and reinstall? joblib is no longer in externals ...
There was a problem hiding this comment.
I found it. The problem was with my scikit_learn_data directory. For some reason (probably because it was created by an old scikit-learn version) it was causing pickle to look for the sklearn.externals.joblib instead of joblib. I deleted the contents and now it works. I also removed the ConvergenceWarning by passing a larger tolerance parameter.
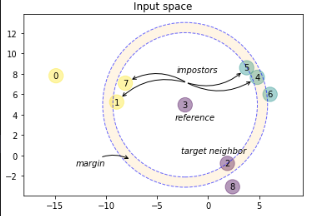
| Large Margin Nearest Neighbor Illustration | ||
| ========================================== | ||
|
|
||
| An example illustrating the goal of learning a distance metric that maximizes |
There was a problem hiding this comment.
What about
"This example illustrates...."
|
|
||
| # Annotate the impostors (1, 4, 5, 7) | ||
| imp_centroid = (X[1] + X[4] + X[5] + X[7]) / 4 | ||
| imp_arrow_dict = dict(facecolor='black', color='gray', arrowstyle='->', |
There was a problem hiding this comment.
A UserWarning is thrown by matplotlib (see the rendered example). Do you mind fixing it? Thanks!
|
@bellet and @wdevazelhes any opinion on this one? as authors of metric_learn I am wondering about the pros and cons (if any) of the proposed implementation. API wise does it lead to comparabale usage? |
@agramfort yes, API wise the general parameters ( There are just some parameters specific to As a matter of fact, I think this implementation has a lot of cool features that are not yet in Also just one remark: in |
|
Hi @wdevazelhes , thanks for the comments ;) Sure, integrating to |
|
+1 for also integrating this implementation in |
|
Hi @bellet , sure but the next 2-3 weeks are a bit busy for me. I can open a PR in |
That would be great, thanks! |
|
Hi @johny-c I saw that you submitted your PR to |
|
I wanted to give a hand by bringing this PR to
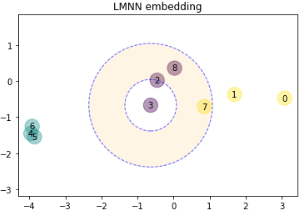
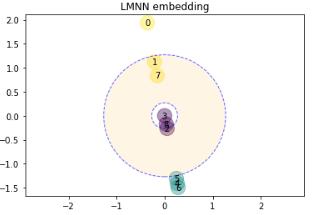
I was pretty unfamiliar with the original paper and I saw that as mentioned earlier, we do not use the hinge loss but instead the squared hinge loss and use LBFGS on differentiable loss. I could not find the original code or paper deriving this solver so it is a bit difficult to review. I wanted to write a couple of tests to ensure that the minimization goes as expected. The first thing that I wanted to do was to compare the squared hinge loss minimization vs. the hinge loss minimization as shown in the JMLR paper. I quickly tried the With metric-learn, I get the following results:
Basically, I set a very small tolerance and let the algorithm converge (
I was wondering if @bellet @johny-c have any inside regarding the difference in the solution found. Do you think that it is only due to the loss used? |
|
Thinking a bit more about the problem, using the squared hinge should have more impact on the "push" loss. The quadratic part will penalized more impostors and I assume that the solution will therefore try to increase the distance between in-class NN and the impostors. |
|
While I am not really against using the hinge loss, I still think that we should actually both loss and then the most appropriate solver. |
Reference Issue
What does this implement/fix? Explain your changes.
Hi! This is an implementation of the Large Margin Nearest Neighbor algorithm that follows the original implementation of the author's (K.Weinberger) Matlab code (see also my docstrings). As far as I know there is no prior implementation of this version of the algorithm in python and no version at all in scikit-learn. The implementation lies in a single file (sklearn/neighbors/lmnn.py). Maybe it should go directly in the sklearn/neighbors/classification.py but I thought it would make things too cluttered. It is basically a subclass of the
KNeighborsClassifierwith a lot of added functionality. I put also an example in examples/neighbors/plot_lmnn_classification.py that is basically a copy of the simple nearest neighbor example in examples/neighbors/plot_classification.py.Any other comments?
I run all scikit-learn tests I could find and it now passes all of them. There is still a TODO in the code which I think is a minor issue (the algorithm works anyway). Somehow during fitting, I need to pass a possibly changed attribute (n_neighbors) to the superclass and call the fit method of the superclass. I would appreciate any comments and/or help to finalize this. Thanks!