Issues using HDBSCAN #91
Comments
|
I just added some code to the master branch that will only try to cluster data that is larger than Could you try installing from the library from master and see if that fixes the problem for you? |
|
This seems to work now - thanks. I think there might be issues with the visualizer on master - particularly with IE (which is not surprising). Unfortunately, I am very restricted to using IE - is it safe to use an old version of Edit: Edit 2: Edit 3: |
|
Thanks for your comments! I'm glad the fix worked. I'm sorry it isn't working on IE! As a temporary solution, you could use the older Any idea what's going wrong with IE? I'll try to take a look later tonight. Definitely need to get that resolved before we update pypi. Your modified
|
|
I've made a pull request modifying
|
|
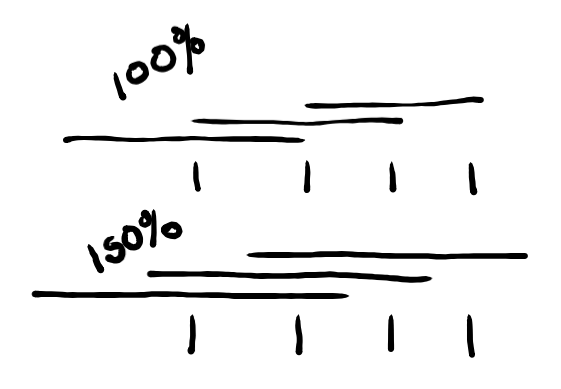
Hi @leesteinberg, the PR looks good. I'll merge it as soon as I have time to actually run the code. The way the bin width is calculated is a little confusing at first. The amount of percentage of overlap is calculated as a percentage of the distance between bins, not the percent the bins overlap. If it was actual overlap, then we could never have finite bin length and Suppose you wanted the bins to interact with bins that are not directly adjacent. Maybe the little drawing below helps.
|
Hi there,
When using HDBSCAN (from hdbscan library, as suggested in Issue #68), the code terminates with :
ValueError: k must be less than or equal to the number of training pointsThis is with the default behaviour (i.e. using
mapper.map(projected_X=projected_data, inverse_X=data, clusterer=hdbscan.HDBSCAN())The same data and projection work fine with
DBSCAN(), so I assume its an issue with the interaction withhdbscan. Maybe you know something about this?The text was updated successfully, but these errors were encountered: