A lot of lsa-timing log messages during node replace cause c-s stucked and aborted #13753
Comments
|
Green lines on graf is bootstrapped with replace new node |
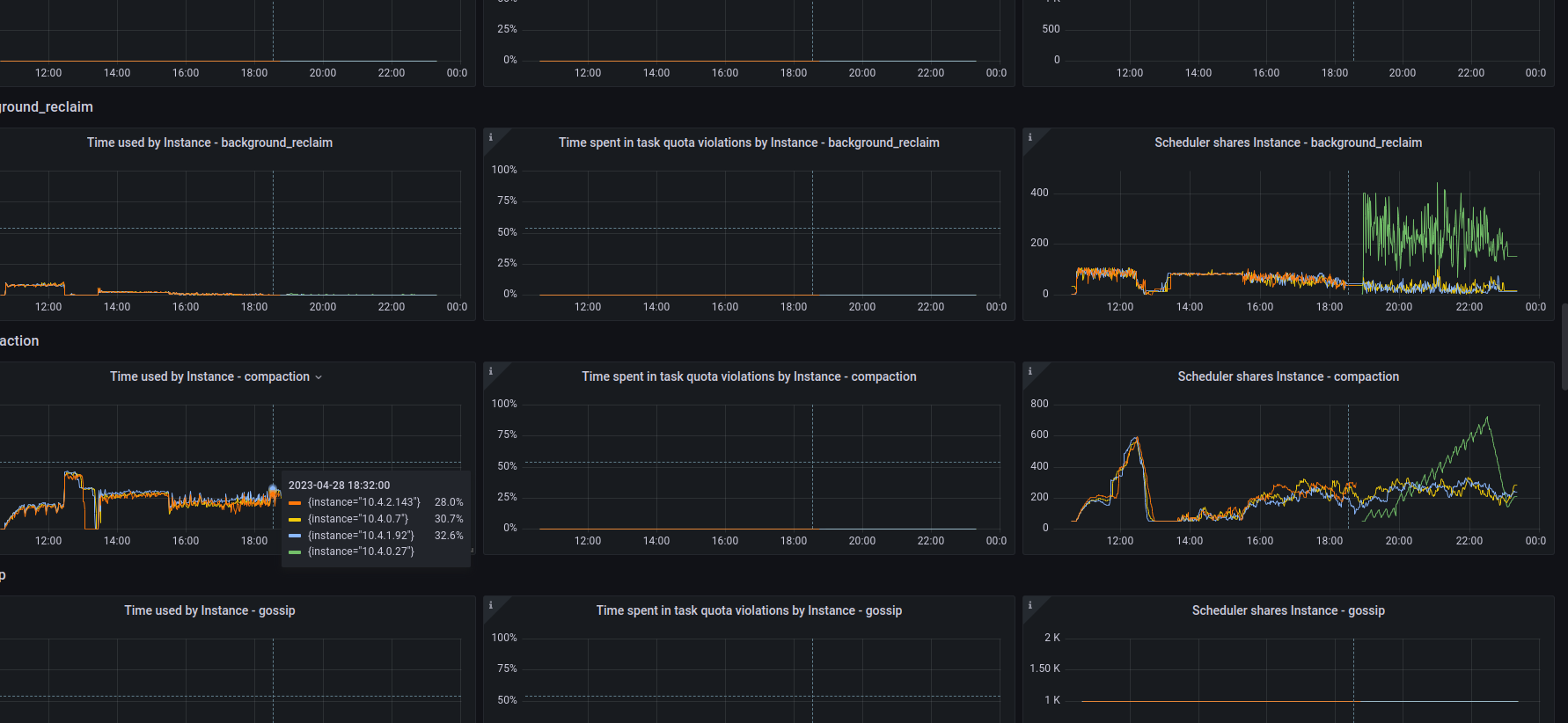
|
@aleksbykov - can you describe the topology and the workload? Specifically, how many nodes and what was the workload? If I'm seeing correctly, you only had 3 nodes and you've replaced one of them? If the load is too high, I reckon the other 2 'live' nodes could not sustain it (just a theory, looking at the above - haven't looked at the logs or monitor yet!) |
|
topology is 3 nodes. 1 node was terminated and was replaced with new one. |
|
@avikivity / @tgrabiec can you please give some directions |
|
Suspecting #8828. |
|
I see many tcp related kernel stalls, but also #8828 stalls. It's hard to be sure because the release predates seastar/seastar@d41af8b59237a949620a9e0b79541b934e0a5375. Still, it's a good indication. |
|
High shares in background_reclaim indicate very high memory pressure, but low cpu activity.
|

That's not a true #8828, the stall is during decode, which means it's just struggling to reclaim memory. |
|
Memory stress around 21:09, will cross reference with the logs:
|

|
Also seen with cache memory usage. Certainly something strange is going on.
|

|
Free memory. 21:09 anomaly is visible, but actually more memory is free for the bad shard.
|

|
A #8828 stall (but I don't believe that's the main issue): |
|
Looking for the memory consumer. Execution stages are clean. |
|
coordinator background reads/writes are clean. |
|
No anomaly in memtables:
|
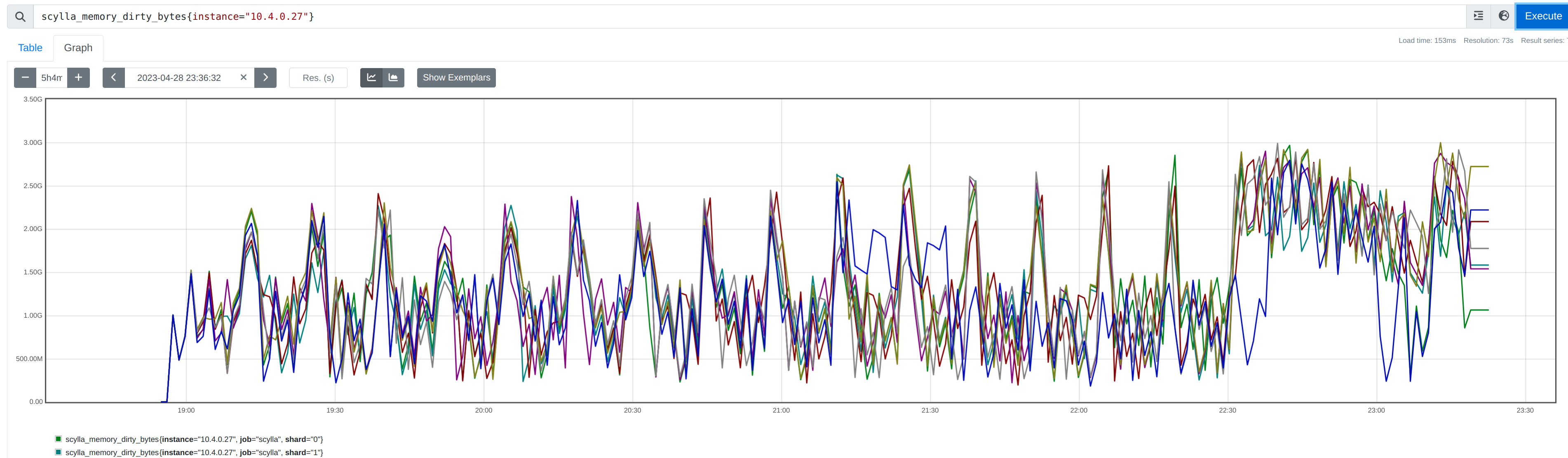
|
Active reads on the bad shard go to zero 21:09.
|

|
Something strange. On all nodes, the system reader concurrency semaphore, shard 6, reports 176MB of memory in use by active reads.
|

|
/cc @denesb is this some leak? |
|
The shard that suffers the memory anomaly at 21:09 is also shard 6. Coincidence? I think not. |
|
QUORUM queries on all nodes all shard. Shard 6 of the bad node shows 0 for most of the time (even before the anomaly). I think it is cursed.
|

|
At 23:10 it somehow recovers. |
|
Nothing special in reactor tasks pending. |
|
Repair rx byte rate dropped to zero when the anomaly started:
|

|
(only on shard 6 of course) |
|
The logs don't show anything special at 21:09, and the trouble (in the logs) started long before that. |
|
21:09 is partially explained as that's when the data transfer part of repair completed.
|

|
CPU steal time looks broken.
|

|
But what happened at 21:09 shard 6? Repair completed, so it started offstrategy reshape. Is reshape so bad it consumed gigabytes of memory? Sounds unrealistic. /cc @raphaelsc |
|
Mr. 6 sees a large spike in aio writes. So:
|
Yes, and this is a good idea regardless of the problems it fixes. 1 is not a sane default number of shares for anything. |
|
Why didn't we see this before? |
|
Maybe we did, and the reports were buried under other problems. |
This test is new. Maybe the problem was there in older tests but the delays induced by it didn't happen to be quite large enough to last through all of cassandra-stress's retries. And we only noticed it when it finally caused a test to have a hard failure. |
We did, pretty much every customer-side "large IO delays" metrics I looked at had default class terrible latencies |
Is there a specific bug about this request (raise the default priority class shares to 200) ? |
No. |
|
Fixed by 66e4391 (indirectly) |
The number of shares is supposed to be set in the 1-1000 range, and user-defined IO classes have shares on the order of hundreds in practice. Therefore, 1 share is not a sane default, because the default class can very easily be starved by accident. We have seen in practice for example in scylladb/scylladb#13753.
The number of shares is supposed to be set in the 1-1000 range, and user-defined IO classes have shares on the order of hundreds in practice. Therefore, 1 share is not a sane default, because the default class can very easily be starved by accident. We have seen in practice for example in scylladb/scylladb#13753.
The number of shares is supposed to be set in the 1-1000 range, and user-defined IO classes have shares on the order of hundreds in practice. Therefore, 1 share is not a sane default, because the default class can very easily be starved by accident. We have seen in practice for example in scylladb/scylladb#13753.
The number of shares is supposed to be set in the 1-1000 range, and user-defined IO classes have shares on the order of hundreds in practice. Therefore, 1 share is not a sane default, because the default class can very easily be starved by accident. We have seen in practice for example in scylladb/scylladb#13753.
This allows us to start backporting Seastar patches. Ref #13753.
* seastar f94b1bb9cb...e45cef9ce8 (1): > reactor: change shares for default IO class from 1 to 200 Fixes #13753.
The number of shares is supposed to be set in the 1-1000 range, and user-defined IO classes have shares on the order of hundreds in practice. Therefore, 1 share is not a sane default, because the default class can very easily be starved by accident. We have seen in practice for example in scylladb/scylladb#13753. (cherry picked from commit e45cef9)
The number of shares is supposed to be set in the 1-1000 range, and user-defined IO classes have shares on the order of hundreds in practice. Therefore, 1 share is not a sane default, because the default class can very easily be starved by accident. We have seen in practice for example in scylladb/scylladb#13753. (cherry picked from commit e45cef9)
|
Alternative fix queued for 5.1, 5.2, 5.3. |
Installation details
Scylla version (or git commit hash): 5.2.0~rc5-0.20230425.a89867d8c230 with build-id 15657fcbd406469aa63748f0b8aab3330c137b4e
Cluster size: 3
OS (RHEL/CentOS/Ubuntu/AWS AMI): ami-0859cdda6c3ecfd84(eu-west-1)
instance type: i3en.2xlarge
test-id: db29e3d2-3903-44e5-bc8b-e4c3c74bc4b0
job: https://jenkins.scylladb.com/job/Perf-Regression/job/scylla-release-perf-regression-latency-650gb-with-nemesis/2/
One of operation during latency_with_nemesis write_test was Terminate and replace. Node 3 was terminated and in 5 minutes node was added and start bootstrapping. the boot strapping took about 3 hours. Also during boot strap process in node4 log there are a lot of next messages:
Right after Scylla was started, next error appeared in node4 log :
once
handle_state_normal: Nodes 10.4.2.143 and 10.4.0.27 have the same token -6630159402286116649. Ignoring 10.4.2.143start appearing in log, c-s start reporting next errors:and test was terminated by crirical issue
db_logs: https://cloudius-jenkins-test.s3.amazonaws.com/db29e3d2-3903-44e5-bc8b-e4c3c74bc4b0/20230428_231723/db-cluster-db29e3d2.tar.gz
monitoring:
http://3.235.167.195:3000/d/Pnn1R-s4k/scylla-release-perf-regression-latency-650gb-with-nemesis-scylla-per-server-metrics-nemesis-master?from=1682676687923&to=1682726481734&var-by=dc&var-cluster=&var-dc=All&var-node=All&var-shard=All&var-mount_point=&var-func=sum&var-dash_version=5-2&var-all_scyllas_versions=All&var-count_dc=All&var-scylla_version=5.2&var-monitoring_version=4.2.1&orgId=1
http://3.235.167.195:3000/d/advanced-5-2/advanced?orgId=1&refresh=30s&from=1682676687923&to=1682726481734
Similar happened also during test_read when new node was bootstrapped with replace and during bootstrapping new nodes
db_logs: https://cloudius-jenkins-test.s3.amazonaws.com/cc78a106-e5b6-4b9a-bfca-44c1dce36118/20230429_030853/db-cluster-cc78a106.tar.gz
The text was updated successfully, but these errors were encountered: