Add max-stack option to reassemble array predictions #99
Conversation
|
Hey Calum, thanks for the very comprehensive PR! That report is really interesting to see. I had seen some differences depending on the window position for EQTransformer myself yet, but I had never looked at it systematically. Out of interest, did you check what happens if you try models trained on different datasets? I could imagine the effect is less strong when using INSTANCE, because the waveforms windows in the dataset are longer, increasing the natural variability in pick positions during training. Regarding the PR, I think the max option absolutely makes sense. And I agree, it would be a good choice to make this the default behaviour and I'd even set this as default for all models. It's a breaking change, but we'll only put it in v0.3 and as the old behaviour is still available, I think that's acceptable. I only have three minor points:
Last remark: It's not necessary to overwrite the entries in |
|
Great, thanks for that feedback, and apologies for the length of the text for such a small code change! I thought I would use this as an opportunity to document the motivation for this. I will have a play with INSTANCE now and post an update below this. Related to that and to #96 - the main difference between the two EQTransformer models apparently is the difference in the amount of data augmentation done. I don't know how comparable the augmentation in the seisbench trained models is to either of the EQTransformer models, but that would be interesting to think about further. Thanks for those comments, and apologies for not meeting the black and test needs! That was just lazy. Regarding the pre-commit hook: I had already created a python 3.10 env and attempted to set up the pre-commit hook in there, but the strict requirement of targeting python 3.8 in the .pre-commit-config.yml configuration meant that that was not possible in that env. I haven't tested whether this works in the recommended python 3.9 env in the contributing guide, but I wonder if you can set the language_version to
|
|
Perfect, thanks for the comprehensive updates. I'll merge now. Thanks once more for this contribution! And don't worry about the long report, I think it's really interesting to explicitly visualize the differences and I guess the question of translation invariance for pickers will also pop up in papers eventually. Thanks also for pointing out the pre-commit issue. I'll adjust the language version to |
For details see discussion in comments to #99
For details see discussion in comments to #99
|
Thanks for merging that. I made a couple of videos of the INSTANCE trained model for the same two earthquakes and stations (with my obvious NZ bias having two NZ based stations). For both of these each frame is showing a single 60s window, so there is no overlap. SNZO (INSTANCE weights) - regional, broadband sensorFor the SNZO regional earthquake there are some variations between windows, but the P and S peak predictions are mostly quite stable. The detection prediction window is quite different in both examples to the detection windows given by the original EQTransformer model. In some windows there is a secondary spike in the P prediction value around the S-phase. INSTANCE_SNZO_shifts.mp4EORO (INSTANCE weights) - local, short-period sensorFor the local earthquake case there is quite a bit of variation. Some windows have spikes in the P prediction value around the S-arrival despite both phases being within the window, and there are generally quite strong variations between windows. Stacking using the max-stack method for this would probably give a poor result. INSTANCE_EORO_shifts.mp4We are planning on doing more testing of the various trained weights available using some of our well-picked manual catalogues, and I don't think that these two examples are necessarily representative of the general output for these models, but they do seem to have quite different performance to the original EQTransformer models. The "STEAD" weights retrained in seisbench show slightly different results, and still have a lot of variability. They never reach the quite the same target detection prediction shape, but the P and S picks seem robust: SNZO (STEAD weights)STEAD_EQT_overlap_0.0s_SNZO.mp4EORO (STEAD weights)STEAD_EQT_overlap_0.0sEORO.mp4Edit (@yetinam, 22/06/16 10:23): Slightly fixed formatting |
|
Thanks for the follow-up. Really interesting to see these differences. At least parts of them (the better invariance to pick location in INSTANCE) match my intuition. Looking forward to the results from your systematic analysis! |
Possible enhancement/discussion point
Currently prediction time-series from overlapping windows are combined into one prediction time-series spanning the entire stream fed to the model. To combine these overlapping windows the average of these windows is taken. For EQTransformer combining by taking the mean is not ideal as the prediction value depends quite strongly on when the phase occurs within the 60s window used for prediction.
Consider the below case for the same earthquake recorded on site SNZO (and reported in the EQTransformer paper:
P at 10s
t 10s
P at 20s
P at 30s
In this example the main issue is likely that the whole event does not fit in the detection window when the P arrival is much later than 20s into the window. The result of this when overlapping windows and stacking as the mean of the overlaps is that the predictions are degraded by windows for which the P arrival is not at the optimum position:
This gets worse for larger overlaps:
And even worse for a more general case where the first window is not the "ideal" window:
The key point arising from this is that stacking as the average of overlapping prediction windows, at least for EQTransformer, results in degraded prediction arrays and resulting predictions. This can result in missing detections or picks. In EQTransformer itself it looks like this issue is circumvented by picking on each window individually and combining the picks later, although this does seem to result in pick duplication.
I suggest that instead of either of the above options it might be better to pick on the combined predictions, but combined by taking the maximum values in overlapping windows. This assumes that each discrete window is either "correct" (if the arrivals occur in "optimal" locations in the window) or under predicting.
Using the adaptation in the PR (you might prefer a different implementation, and I would suggest that max_stack is the default at least for EQTransformer) the final example above results in:
I think that this gives a "better" result that is at least closer to what I think the original intention of EQTransformer was. In the examples below with a closer earthquake you can see that the degradation in prediction quality isn't just happening when events do not fully fit in the window used. These events use a short-period station in the SAMBA network:
P-arrival 10s into window:
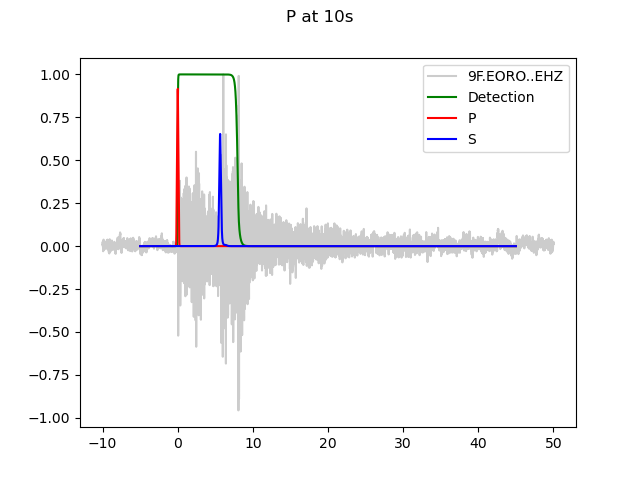
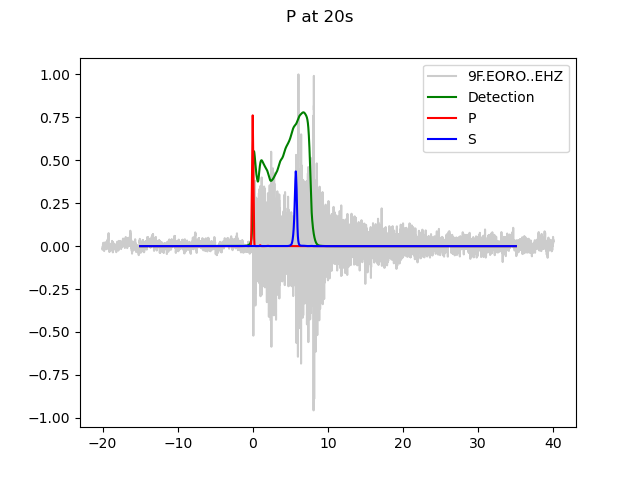
P-arrival 20s into window, degradation apparent:
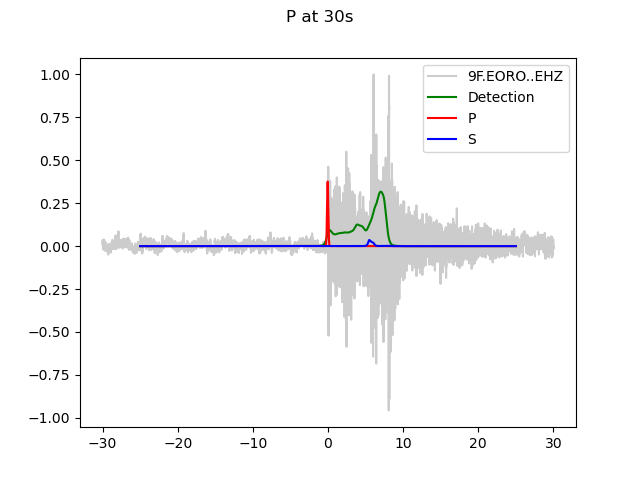
P-arrival 30s into window, S-pick unlikely to be made.
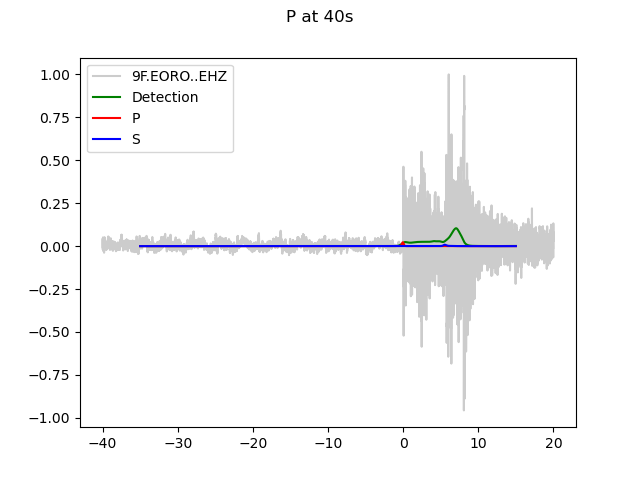
P-arrival at 40s, detection would not be made, and no P or S picks.
An aside on overlaps in EQTransformer
I ran into this when playing with overlaps - A student at VUW (Olivia) noticed that when she put her P arrivals in different places in her window for testing she got very different results and sometimes did not make a pick. This can be seen in the video below where a clear earthquake recorded at SAMBA site EORO is sometimes picked and sometimes missed when using an 18s overlap. Note that using the max-stack does not solve this issue because, depending on when your data start relative to the earthquake, there may never be a window that has the arrival in the optimal position. In the video below the data and predictions are as above, Each frame is the result of a prediction from a different chunk of data - each frame steps that by 5 seconds. A 120s window is used to ensure that multiple overlapping windows are used. The dashed lines are the thresholds of 0.5 and 0.3 suggested at one point in the EQTransformer paper.
seisbench_EQT_overlap_18.0s.mp4
The video below shows the same for a 30s overlap:
seisbench_EQT_overlap_30.0s.mp4
And finally with a 55s overlap. In this example the frame step is 0.1s so the video is much slower, but this serves to show more realistically the variability in pick skill and quality based on uncontrollable event timing:
seisbench_EQT_overlap_55.0s.mp4
Using the max-stack option creates a more stable result with the 55s overlap:
seisbench_EQT_overlap_55.0s_max_stack.mp4