- Input layer (receives data and passes it on)
- Hidden layer
- Output layer
- Weights between the layers
- Activation function (per hidden layer) (Sigmoid activation function)
- Feed-forward (perception) neural network (relays data directly from the front to the back)
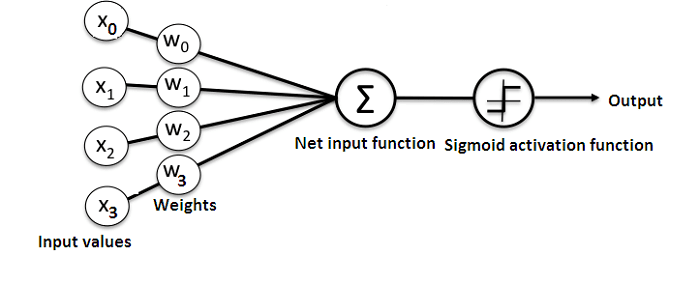
input * weight + bias = output
| Input | Output | |
|---|---|---|
| Data 1 | 0 - 0 - 1 | 0 |
| Data 2 | 1 - 1 - 1 | 1 |
| Data 3 | 1 - 0 - 1 | 1 |
| New Case | 1 - 0 - 0 | ? |
Every input will have a weight (positive or negative). This implies that an input having a big number of positive weight or a big number of negative weight will influence the resulting output more.
Procedure for the training process:
Taking inputs from the training dataset,
- Perform some adjustments based on their weights, and siphon them via a method that computes the output of the neural net
- Compute the back-propogated error rate. In this case it is the difference between the neuron's predicted output and the expected output of the training dataset
- Based on the extent of the error, perform some minor weight adjustments using the Error Weighted Derivative formula
- Iterate this process an arbitrary number of times (we chose 15000). Every iteration, the whole training set is processed simultaneously
exp- for generating the natural exponentialarray- for generating a matrixdot- for multiplying matricesrandom- for generating random numbers (we'll seed the random numbers to ensure their efficient distribution)