by Shizuo Kaji, 2021

The codes provide a scheme for pretraining deep neural networks with synthetic images and mathematically defined labels that captures topological information in images. The pretrained models can be finetuned for image classification tasks to achieve an improved performance compared to those models trained from scratch.
Convolutional neural networks, built upon iterative local operations, are good at learning local features of the image such as texture, but they tend to pay less attention to larger structures. Our method provides a simple way to encourage them to learn global features through a specifically designed task based on topology. Furthermore, our method requires no real images nor manual labels, hence it overcomes some of the lately concerned topics in computer vision such as data collection and annotation, including the cost of manual labour and fairness issues.
With mathematically generated images annotated with mathematically defined labels, this code trains any CNN with no images nor labels, that is, completely in an unsupervised manner. Labels are computed by persistent homology, which are used as the regression target for the pretraining task. Persistent homology encodes topological information of the image so the trained CNN is expected to focus more on the shape rather than the texture, contrasting to ImageNet pretrained models.
This is a companion code for the paper "Teaching Topology to Neural Networks with Persistent Homology" by Shizuo Kaji and Yohsuke Watanabe, in preparation.
To sum up,
- The model acquires robust image features based on topology
- The scheme works with virtually any neural network architectures
- No data collection nor manual labelling is required. Therefore, the resulting model is free from fairness and bias issues.
MIT Licence
-
a modern GPU
-
Python 3: Anaconda is recommended
-
PyTorch >= 1.8
-
tensorboard
-
persim: install by the following command
% pip install persim
-
CubicalRipser: install by the following command
% pip install git+https://github.com/shizuo-kaji/CubicalRipser_3dim
% python main.py --numof_dims_pt=200 --label_type persistence_image -t2 'generate' -u 'resnet50' --max_life 80 60 -lm 'pretraining' -c /temp/ph_cache -pb 0.5 -pc 0.5 --beta_range 1.0 2.0 -n 400000 -nv 1000 -o 'result'
Training images are generated on the fly and cached under '/temp/ph_cache/' (-c /temp/ph_cache) together with their persistent homology. Note that the directory should be writable. Note also that the contents of the directory will be completely erased at the beginning. 400000 training images (-n 400000) and 1000 validation images (-nv 1000) will be generated. Half of them (-pc 0.5) are colour and the rest are grayscale. Half of them (-pb 0.5) are binarised. The frequency parameter beta_range (--beta_range 1.0 2.0) control the frequency profile of the generated images.
You will find the weight file (e.g., resnet50_pt_epoch90.pth) under the directory 'result/XX', where XX is automatically generated from the date.
Different types of persistent-homology-based labelling (vectorisation) can be specified, for example, by (--label_type 'persistence_lifecurve').
The 0-dimensional (resp. 1-dimensional) homology cycles with life time up to 80 (resp. 60) will be used for the labelling ('--max_life 80 60').
The label will be 200 dimensional (--numof_dims_pt=200).
A full list of command-line options can be found by
% python main.py -h
Instead of synthetic images, you can use any existing image dataset for training with the labels generated by persistent homology by
% python main.py --numof_dims_pt=200 --label_type persistence_image -t2 'path_to_dataset' -u 'resnet50' --max_life 80 60 -lm 'pretraining'
The pretrained model can be finetuned for any downstream tasks. The pretraining code saves the weights in a standard PyTorch model format (e.g., 'result/XX/resnet50_pt_epoch90.pth'), so you can use your own code to load the pretrained model.
Our code can be used for finetuning as well. (Note that our code does not aim at achieving high performance for downstream tasks. It has very basic features which is suitable only for performance comparison):
% python main.py -t 'data/CIFAR100/train' -val 'data/CIFAR100/test' -pw 'result/XX/resnet50_pt_epoch90.pth' -o 'result' -e 90 -lm 'finetuning'
The CIFAR100 dataset can be obtained by
% python util/ImageDatasetsDownloader.py --dataset CIFAR100
The Animal dataset can be obtained from here, or use the script as follows:
% python util/ImageDatasetsDownloader.py --dataset animal
The downloader script ImageDatasetsDownloader.py is a modification of the original.
% python main.py --val data/CIFAR100/test --lm evaluation -pw 'result/XX/resnet50_finetuning_epoch90.pth'

The table shows the classification accuracies of the CIFAR100 dataset and the Animal dataset with models pretrained in different datasets and tasks.
- Scratch indicates without any pretraining (random initialisation)
- Label uses the class label both in pretraining and finetuning
- ImageNet model is provided by the torchvision library.
- FractalDB-1k (FractalDB-10k) are synthetic dataset generated consisting of fractals. The pretrained models are obtained from the web page.
- PH- models are pretrained with our code (with 400k images) with different PH vectorisations (specified by --label_type); PH-PI with the persistence image, PH-LS with the persistence landscape, PH-BC with the Betti number curve, and PH-HS with the birth-life histogram
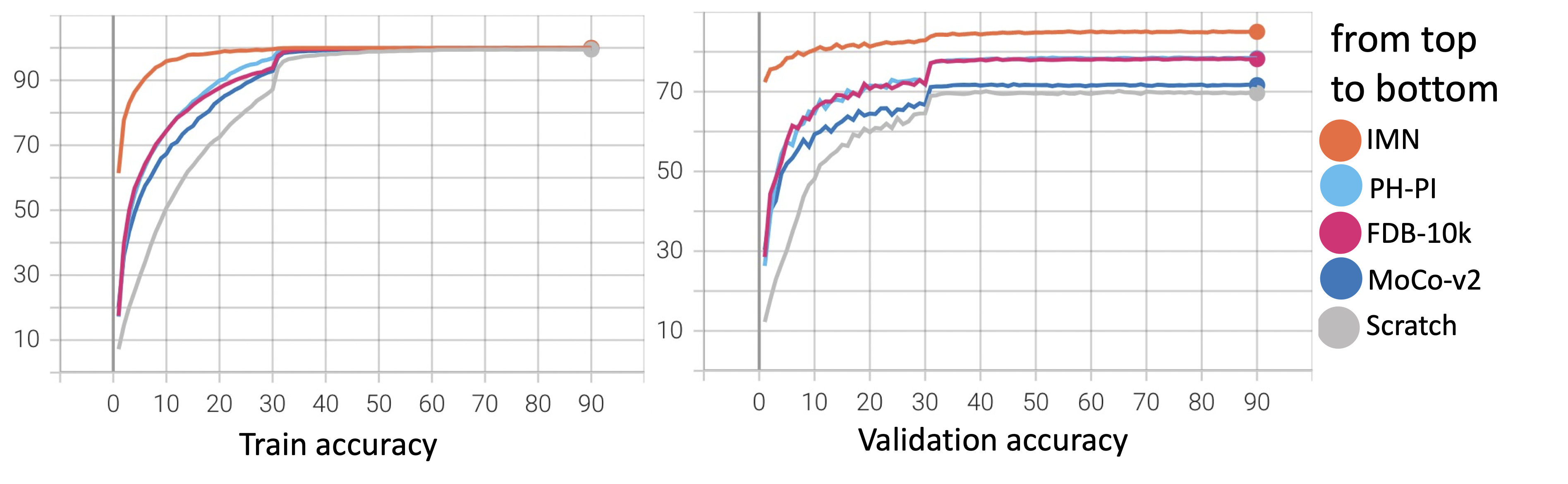
The graph shows the transition of training (left) and validation (right) accuracy.
Note that the purpose of the experiment is to show the effectiveness of our method but not to maximise the performance. So the hyper-parameters are fixed (not optimised) and the performances with different pretraining conditions are compared.