This repository contains the code for the paper "Audeo: Audio Generation for a Silent Performance Video", which is avilable here, published in NeurIPS 2020. More samples can be found in our project webpage and Youtube Video.
{kind=link}
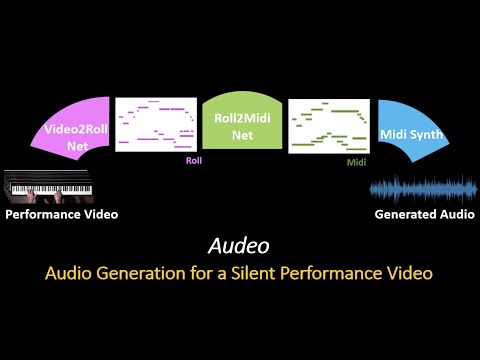
We present a novel system that gets as an input, video frames of a musician playing the piano, and generates the music for that video. The generation of music from visual cues is a challenging problem and it is not clear whether it is an attainable goal at all. Our main aim in this work is to explore the plausibility of such a transformation and to identify cues and components able to carry the association of sounds with visual events. To achieve the transformation we built a full pipeline named ‘Audeo’ containing three components. We first translate the video frames of the keyboard and the musician hand movements into raw mechanical musical symbolic representation Piano-Roll (Roll) for each video frame which represents the keys pressed at each time step. We then adapt the Roll to be amenable for audio synthesis by including temporal correlations. This step turns out to be critical for meaningful audio generation. In the last step, we implement Midi synthesizers to generate realistic music. Audeo converts video to audio smoothly and clearly with only a few setup constraints. We evaluate Audeo on piano performance videos collected from Youtube and obtain that their generated music is of reasonable audio quality and can be successfully recognized with high precision by popular music identification software.
We use Youtube Channel videos recorded by Paul Barton to evaluate the Audeo pipeline. For Pseudo Midi Evaluation, we use 24 videos of Bach Well-Tempered Clavier Book One (WTC B1). The testing set contains the first 3 Prelude and Fugue performances of Bach Well-Tempered Clavier Book Two (WTC B2) The Youtube Video Id can be found in here. For Audio Evaluation, we use 35 videos from WTC B2 (24 Prelude and Fugue pairs and their 11 variants), 8 videos from WTC B1 Variants, and 9 videos from other composers. Since we cannot host the videos due to copyright issues, you need to download the videos yourself.
All videos are set at the frame of 25 fps and the audio sampling rate of 16kHz. The Pseudo GT Midi are obtained via Onsets and Frames framework (OF). We process all videos and keep the full keyboard only and remove all frames that do not contribute to the piano performance (e.g., logos, black screens, etc). The cropped piano coordinates can be found in here (The order is the same as in Video_Id file. We trim the initial silent sections up to the first frame in which the first key is being pressed, to align the video, Pseudo GT Midi, and the audio. All silent frames inside each performance are kept.
For your convenience, we provide the following folders/files in Google Drive:
- input_images: examples of how the images data should look like.
- labels: training and testing labels of for training/testing Video2Roll Net. Each folder contains a pkl file for one video. The labels are dictionaries where key is the frame number and value is a 88 dim vector. See Video2Roll_dataset.py for more details.
- OF_midi_files: the original Pseudo ground truth midi files obtained from Onsets and Frames Framework.
- midi: we process the Pseudo GT Midi files to 2D matrix (Piano keys x Time) and down-sampled to 25 fps. Then for each video, we divide them into multiple 2 seconds (50 frames) segments. For example 253-303.npz includes the 2D matrix from frame 253 to frame 302.
- estimate_Roll: the Roll predictions obtained from Video2Roll Net. Same format as the midi. You can directly use them for training Roll2Midi Net.
- Roll2Midi_results: the Midi predictions obtained from Roll2Midi Net. Same format as the midi and estimate_Roll. Ready for Midy Synth.
- Midi_Synth: synthesized audios from Roll2Midi_results.
- Video2Roll_models: contains the pre-trained Video2RollNet.pth.
- Roll2Midi_models: contains the pre-trained Roll2Midi Net.
- Video2Roll Net
- Please check the Video2Roll_dataset.py and make sure you satisfy the data formats.
- Run Video2Roll_train.py for training.
- Run Video2Roll_evaluate.py for evaluation.
- Run Video2Roll_inference.py to generate Roll predictions.
- Roll2Midi Net
- Run Roll2Midi_train.py for training.
- Run Roll2Midi_evaluate.py for evaluation.
- Run Roll2Midi_inference.py to generate Midi predictions.
- Midi Synth
- Run Midi_synth.py to use Fluid Synth to synthesize audio.
- Pytorch >= 1.6
- Python 3
- numpy 1.19
- scikit-learn 0.22.1
- librosa 0.7.1
- pretty-midi 0.2.8
Please cite "Audeo: Audio Generation for a Silent Performance Video" when you use this code:
@article{su2020audeo,
title={Audeo: Audio generation for a silent performance video},
author={Su, Kun and Liu, Xiulong and Shlizerman, Eli},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}