Implement cross-validated calibration #3851 #4009
Conversation
|
This is great! Thanks! |
3b08714
to
3410ab7
Compare
src/shogun/evaluation/Calibration.h
Outdated
| #include <shogun/lib/config.h> | ||
| #include <shogun/machine/Machine.h> | ||
|
|
||
| #ifndef _CALIBRATION_H__ |
There was a problem hiding this comment.
move this to the beginning of the file with the define as well.... this way the above includes will be included only once even if shogun/evaluation/Calibration.h included more than once
| CBinaryLabels* CCalibration::apply_binary(CFeatures* features) | ||
| { | ||
|
|
||
| CBinaryLabels* result_labels = (CBinaryLabels*)m_machine->apply(features); |
There was a problem hiding this comment.
this explicit casting will cause a lot of trouble if the returned label is not binary of the machine :) you should either do a dynamic_cast to check for this or simply get_label_type() == LT_BINARY
There was a problem hiding this comment.
Should I use SG_ERROR to indicate that the machine should return binary labels when the labels are not binary?
There was a problem hiding this comment.
Hello @vigsterkr, I have used the approach that you have mentioned (using get_label_type and REQUIRE). However, shogun seems to have a LabelsFactory class which has methods for doing the same thing. Is that the recommended way of doing this?
There was a problem hiding this comment.
mmm oh yeah labelfactory, indeed its the best option
| { | ||
| index_t num_calibration_machines = | ||
| m_calibration_machines->get_num_elements(); | ||
| CMulticlassLabels* result_labels = |
There was a problem hiding this comment.
same as above... do a safe typecheck
| result_labels->get_multiclass_confidences(i); | ||
| for (index_t j = 0; j < num_samples; ++j) | ||
| { | ||
| confidence_values[j] = confidence_values[j] / temp_confidences[j]; |
There was a problem hiding this comment.
this could be simply:
confidence_values[j] /= temp_confidences[j];
| { | ||
| index_t num_calibration_machines = | ||
| m_calibration_machines->get_num_elements(); | ||
| CMulticlassLabels* result_labels = |
| } | ||
| } | ||
|
|
||
| for (index_t i = 0; i < num_classes; ++i) |
| temp_values = result_labels->get_multiclass_confidences(i); | ||
|
|
||
| #pragma omp parallel for | ||
| for (index_t j = 0; j < temp_values.vlen; j++) |
| m_calibration_method = calibration_method; | ||
| } | ||
|
|
||
| void CCrossValidatedCalibration::init() |
| ~CSigmoidCalibrationMethod(); | ||
|
|
||
| private: | ||
| float64_t a, b; |
| } | ||
|
|
||
| CSigmoidCalibrationMethod::CSigmoidCalibrationMethod() : CCalibrationMethod() | ||
| { |
There was a problem hiding this comment.
need to init a and b variables and SG_ADD them
There was a problem hiding this comment.
Should they be initialized to 0?
There was a problem hiding this comment.
yep that's a good value as initial value
|
Thanks a lot for the detailed review. I'll make all the required changes and make a pr. From my understanding, in general, I have to make the following rectifications:
|
|
@durovo yes more or less that's the idea. as soon as you fix those the travis builds should be green. the reason they fail now is because you miss SG_ADD |
|
@vigsterkr was faster with reviewing :) One comment: Let's maybe first make it work without parallel omp, as that might complicate things quite a bit. We can work on that once the other comments around duplicate code and style are resolved. We could then solve parallel xvalidation and parallel calibration in the same go. Also, what I would love to see is using the x-validation code in shogun to calibrate, rather than copying it (@vigsterkr mentioned this in his comments). Great first start, thanks for the effort. Let's get this going, make sure to ask in IRC if you have questions or get stuck. Looking forward to the update |
| * This program is free software; you can redistribute it and/or modify | ||
| * it under the terms of the GNU General Public License as published by | ||
| * the Free Software Foundation; either version 3 of the License, or | ||
| * (at your option) any later version. |
There was a problem hiding this comment.
pls use a BSD header, see e.g. https://github.com/shogun-toolbox/shogun/blob/develop/src/shogun/statistical_testing/BTestMMD.h
| index_t num_samples; | ||
|
|
||
| // normalize the probabilities | ||
| for (index_t i = 0; i < num_classes; ++i) |
There was a problem hiding this comment.
all of this can be done in a vectorised fashion using linalg, see e.g. https://github.com/shogun-toolbox/shogun/blob/develop/src/shogun/preprocessor/KernelPCA.cpp#L92
There was a problem hiding this comment.
Yes, I'm currently trying to vectorize wherever possible.
|
|
||
| extern MultiLabelTestEnvironment* multilabel_test_env; | ||
|
|
||
| #ifdef HAVE_LAPACK |
There was a problem hiding this comment.
what is LAPACK needed for here?
There was a problem hiding this comment.
I borrowed this from another test. I will write proper test cases after we discuss the api. Or should I write them now?
| { | ||
| SGVector<float64_t> scores = pred->get_multiclass_confidences(i); | ||
| if (i == 0) | ||
| confidence_sums = scores; |
There was a problem hiding this comment.
rather than writing unit tests here, a good sanity check would be to reproduce the plots in http://scikit-learn.org/stable/_images/sphx_glr_plot_calibration_curve_002.png
You could do that via say Python bindings. Once those work, then we can start adding more unit tests ...
Let me know what you think
There was a problem hiding this comment.
That looks like a great idea. I will try doing that.
There was a problem hiding this comment.
The python interfaces for these files are generated automatically right? Or do I have to add these files to some list? I am asking because I am not able to access these (CrossValidatedCalibration, Calibration, etc) from the shogun module in Python.
There was a problem hiding this comment.
@durovo yeah as of this state the python interface will not contain these methods.. you'll need to add it to some definition files
but that should be another PR. for the time being you should write unit tests for this and test it from the C++ API
3410ab7
to
3776f46
Compare
|
I have tried to make all the suggested changes. However, I have not added omp everywhere which was suggested by @vigsterkr. As @karlnapf suggested, I will add it after I know that the code works correctly without it. I could add it now if required.. |
|
@durovo its fine to do the openmp part later... the point was rather that you should do it in other part of the code as well as use linalg:: when possible. |
| namespace shogun | ||
| { | ||
|
|
||
| class CSigmoidCalibrationMethod : public CCalibrationMethod |
There was a problem hiding this comment.
doxygen. please make sure at least that there's a brief description of the method itself
There was a problem hiding this comment.
Understood, I'll add the descriptions for all methods (and params) and classes.
| result = apply_once(temp_machine, data); | ||
| result_labels = CLabelsFactory::to_multiclass(result); | ||
|
|
||
| for (index_t i = 1; i < num_machines; ++i) |
There was a problem hiding this comment.
The result from the first machine has already retrieved just before the loop. This is a dirty hack that I used because I couldn't find any method to get the number of samples in the features.
There was a problem hiding this comment.
I would still start the loop at 0 for readability
There was a problem hiding this comment.
Understood. However, what is the standard way of getting the number of samples from a given set of feature? (i.e. how do I know how many labels will be there in the predictions before actually calling apply?)
There was a problem hiding this comment.
You can still get the first element to do that.
And then you should ensure that all of the features have the same number of elements
There was a problem hiding this comment.
Wait, isnt that just get_num_vectors ?
| SGVector<float64_t> confidence_sums; | ||
| confidence_sums = pred->get_multiclass_confidences(0); | ||
|
|
||
| for (index_t i = 1; i < num_classes; ++i) |
There was a problem hiding this comment.
same as above... why index from 1?
|
@durovo make sure that the next time you submit that the unit tests are passing, see: on travis CI |
|
@vigsterkr strange.. I'm sure that the unit tests are passing on my computer. EDIT: My apologies, I had not tried running ctest. I had just used make test which did not show the memory errors. |
|
|
||
| for (index_t i = 1; i < num_classes; ++i) | ||
| { | ||
| SGVector<float64_t> scores = pred->get_multiclass_confidences(i); |
There was a problem hiding this comment.
I suggest you use setUp to set up your cross estimator, and then have multiple tests that test different characteristics.
- just calling pred (without asserting anything)
- the sum probability thing you did
- other things that are meaningful
|
Any updates here? |
|
Mmmmh weird. I don't understand this error and never managed to re-produce it locally. Let us know how you get on with it, and if you need help. You can ping me in irc anytime |
|
@karlnapf I think the problem is related to some package installed using conda. For now, I'm using a vm for development. I will try experimenting a bit later to figure out the exact reason behind the problem. |
|
If you have a conda version of shogun installed you need to make sure it is not used in the compilation process .... |
|
Can you define the log loss? |
|
I don't have the conda version of shogun installed. The reason behind the problem seems to be something else. From what I understand, logarithmic loss should decrease after calibration since in a way we are optimizing this metric. |
|
Maybe I misunderstood you.. are you asking me to define the log loss function myself? If that is what you were asking, then I yes certainly. Should I make a new class for it or define it as a throwaway function within the test? |
|
I see, we will need to implement that under |
|
I think for testing this, some simpler tests would be a better start. A really simple case with a Mock model that outputs a fixed class probability, and then see whether the calibration works on that one. I guess before writing tests, you could even first try to reproduce the plots for the sklearn calibration example (or something similar). |
|
As usual, let me know if you need more input on that |
|
Understood. Log loss could come later I guess :). I will try some sanity checks just as you suggested and then write the tests. |
|
@karlnapf shogun/src/shogun/mathematics/Statistics.cpp Line 824 in c87d584 t (line 863). In the following paper, the target labels are used to set the values of t (see page 10).https://www.csie.ntu.edu.tw/~cjlin/papers/plattprob.pdf Is this intentional? Wouldn't this produce somewhat different results? Also, does the splitting strategy randomize the subsets?I managed to set up the python bindings and was trying to compare this implementation's results with sklearn's. |
|
|

|
@karlnapf the curve improves when I modify the fit_sigmoid function to use the true labels. Should I change that too? |
|
Hi! |
|
Understood :). Thanks a lot. |
|
Re the sigmoid fit, are you talking about the line EDIT: False alarm, the scores do actually include the bias, so checking them for +1 -1 is totally OK |
|
Question: Why does the calibrated one in Shogun appears to not be calibrated in the plot ? :) |
There was a problem hiding this comment.
Hey!
First of all, thanks for all this work! This is really useful! And sorry for the long delay (partly due to holidays/new years, and partly due to the size of this patch)
We need to talk about about the code design here. This is too many new classes and too much redundant code.
I don't like all the replicated x-validation code. What about we re-use the existing code? I would imagine that x-validation could accept call back functions of what to do with every fold and does all the bookkeeping around it. Your wrapped class would then only contain the calibration code (and maybe could use your strategy pattern for the way to calibrate).
A final thing is. I would appreciate if you could strip this PR down to a bare minimum (not yet covering all the cases) so that we have an easier time reviewing it. The longer a PR is, the longer it usually takes for someone to take it up. You can easily split this task into multiple PR (keep your work though). There is too many new classes in this one, too much scrolling ...
A good sequence of PRs could be
- modify CCrossValidation to be able to deal with callbacks (in a way that would allow to build wrappers like the one you did), and make existing code work with these modifications
- one after another:
- calibration method base class & implementation & test
- wrapper class, implementation, test
- a clean up PR that adds docs, and addresses minor issues that came up during the code reviews
- example cookbook, notebook addition (the plot you made is cool for that), etc
We are really excited to get this in, so let's keep on iterating! Maybe ping me in irc if you have questions
| @@ -0,0 +1,282 @@ | |||
| /* | |||
| * Copyright (c) The Shogun Machine Learning Toolbox | |||
| * Written (w) 2012 - 2013 Heiko Strathmann | |||
There was a problem hiding this comment.
you might want to add you own name here :)
| @@ -0,0 +1,113 @@ | |||
| /* | |||
| * Copyright (c) The Shogun Machine Learning Toolbox | |||
| * Written (w) 2012 - 2013 Heiko Strathmann | |||
| namespace shogun | ||
| { | ||
|
|
||
| class CCalibration : public CMachine |
There was a problem hiding this comment.
Is Calibration the best name? Could be ambiguous... CalibratedClassifier?
There was a problem hiding this comment.
CalibratedClassifier does seem like a better name
| namespace shogun | ||
| { | ||
|
|
||
| class CCalibration : public CMachine |
There was a problem hiding this comment.
This class needs a @brief description to tell users what it is doing
- it is a meta class that wraps a classifier
- it performs x-validation to...
- ... calibrate the probability outputs
- this is expensive
- what method is used to calibrate
- etc
| namespace shogun | ||
| { | ||
|
|
||
| class CCalibrationMethod : public CMachine |
There was a problem hiding this comment.
I find it a bit weird that both CCalibration and CCalibrationMethod both inherit from CMachine
|
|
||
| extern MultiLabelTestEnvironment* multilabel_test_env; | ||
|
|
||
| #ifdef HAVE_LAPACK |
|
|
||
| for (index_t i = 1; i < num_classes; ++i) | ||
| { | ||
| SGVector<float64_t> scores = pred->get_multiclass_confidences(i); |
| } | ||
|
|
||
| SG_DEBUG("starting unlocked calibration\n", get_name()) | ||
| /* tell machine to store model internally |
There was a problem hiding this comment.
pls dont copy code comments around
|
|
||
| /* produce output for desired indices */ | ||
| CCalibration* calibrator = new CCalibration(); | ||
| calibrator->set_machine((CMachine*)m_machine->clone()); |
There was a problem hiding this comment.
this replicates the data as well .... slow
| CFeatures* features; | ||
| CLabels* labels; | ||
|
|
||
| if (get_global_parallel()->get_num_threads() == 1) |
There was a problem hiding this comment.
Just realised we really don't want to copy/replicate this buggy x-validation codes ...
|
@karlnapf Thanks a lot for the valuable feedback! I don't mind the delays at all, I understand that you must be busy with other work as well. I have already added the descriptions to my local repo but I have not pushed it yet. Maybe I wasn't clear about the fact that I didn't push any code this time. I was just discussing the calibration curves and checking if the |
|
@karlnapf I still have some doubts regarding the shogun/src/shogun/mathematics/Statistics.cpp Line 865 in c87d584 if (labels[i] > 0) and we should take labels as an input to the function. Please correct me if I'm wrong.
|
1 similar comment
|
@karlnapf I still have some doubts regarding the shogun/src/shogun/mathematics/Statistics.cpp Line 865 in c87d584 if (labels[i] > 0) and we should take labels as an input to the function. Please correct me if I'm wrong.
|
|
The libsvm implementation also uses the target labels https://github.com/cjlin1/libsvm/blob/88a1881f03ca139beff93170d7e6f36477fabe54/svm.cpp#L1733 |
|
Think when is |
|
@karlnapf Sorry, for pestering you about this, however, I still don't think it is correct. From what I read, with platt scaling we are fitting our predictions (i.e. |
|
Hey! |
|
Yes, I will fix this. :) |

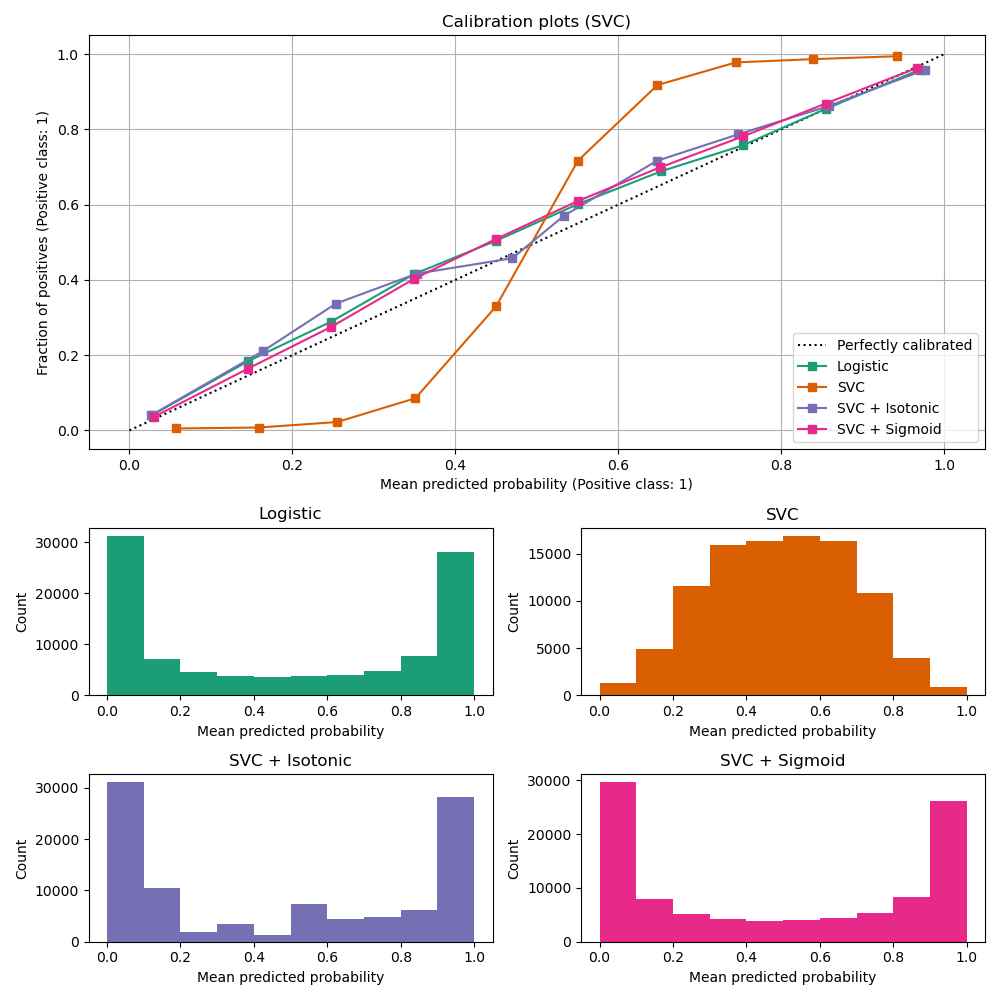{kind=link}
|
Hey that is great! I will review the other one now and then we can get this here in |
Implement a cross-validated calibration scheme (see #3851 ). This is still a work in progress. I will be completing the following tasks after discussing the API:
EDIT:
Fixed the code to conform to the style guidelines.