Writing lyrics has always been a challenging task as it involves not only creativity but also inspiration. With the introduction and development of various neural network-based methodologies that have shown quite a promise in applications to a wide range other fields, it is promising to see how these new technologies can cater to the domain of musical creativity. Even though there has been significant amount of research done focusing on musical composition, it is not the same for musical song writing. This project demonstrates the effectiveness of Recurrent Neural Networks in an efforts to generate song lyrics. The goal of this project is to try out different model architectures and understand how recurrent Neural networks are able to learn the song lyric structures. The experiments were conducted on an English Song dataset. In addition to that, a web-based inference tool is developed, which allows us to easily generate lyrics when we provide input.
RNN
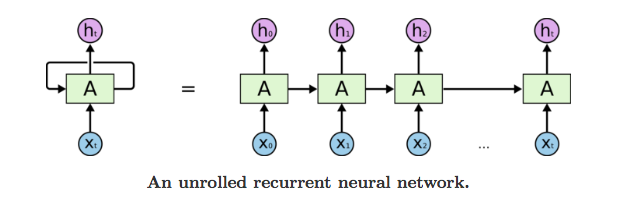
A recurrent neural network (RNN) is a class of artificial neural network where connections between units form a directed graph along a sequence. This allows it to exhibit dynamic temporal behavior for a time sequence. Unlike feedforward neural networks, RNNs can use their internal state (memory) to process sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition. Recurrent Neural Network comes into the picture when any model needs context to be able to provide the output based on the input. Sometimes the context is the single most important thing for the model to predict the most appropriate output.
Problem of Long Term Dependencies Sometimes we only need to look at recent information to perform the present task. For example : Consider a language model trying to predict next word based on previous ones.
PREDICT : "THE CLOUDS ARE IN ..." We don't need to further context as it is obvious that the word is sky. In such cases, where the gap between the relevant information and the place that is needed to predict is small , RNN can learn to use the past information. But there can be cases where we need to remember large content to predict the next word .
PREDICT : I grew up in France .It is often described as a country with six sides. Three are coasts. The others are borders with neighbouring countries.There are mountains in which are snow-capped all year round. I speak ........."
Recent information suggests that the next word is probably the name of a language but if we want to narrow down which language, we need context of France. Therefore, it is possible that the gap between the relevant information and the point where it is needed to become very large. When gap grows, Simple RNN is unable to learn and predict correct information.
Although Simple RNN should theoretically be able to retain at time t information about inputs seen many timesteps before, in practice, such long-term dependencies are impossible to learn. This is due to the vanishing gradient problem, an effect that is similar to what is observed with non-recurrent networks (feedforward networks) that are many layers deep: as we keep adding layers to a network, the network eventually becomes untrainable. The LSTM and GRU layers are designed to solve this problem.
LSTM NETWORK The underlying Long Short-Term Memory ( LSTM ) algorithm was developed by Hochreiter and Schmidhuber in 1997; it was the culmination of their research on the vanishing gradient problem.
Long Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies. LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!
All recurrent neural networks have the form of a chain of repeating modules of neural network. In standard RNNs, this repeating module will have a very simple structure, such as a single tanh layer.

LSTMs also have this chain-like structure, but the repeating module has a different structure. Instead of having a single neural network layer, there are four, interacting in a very special way. The key to LSTMs is the cell state. The cell state is kind of like a conveyor belt. It runs straight down the entire chain, with only some minor linear interactions. It’s very easy for information to just flow along it unchanged. The LSTM does have the ability to remove or add information to the cell state, carefully regulated by structures called gates. Gates are a way to optionally let information through. They are composed out of a sigmoid neural net layer and a pointwise multiplication operation. The sigmoid layer outputs numbers between zero and one, describing how much of each component should be let through. A value of zero means “let nothing through,” while a value of one means “let everything through!” An LSTM has three of these gates, to protect and control the cell state.
GRU GRU (Gated Recurrent Unit) aims to solve the vanishing gradient problem which comes with a standard recurrent neural network. GRU can also be considered as a variation on the LSTM because both are designed similarly and, in some cases, produce equally excellent results.The GRU unlike LSTM dont not have cell state instead they have hidden state. To solve the vanishing gradient problem of a standard RNN, GRU uses, so called, update gate and reset gate. Basically, these are two vectors which decide what information should be passed to the output. The special thing about them is that they can be trained to keep information from long ago, without washing it through time or remove information which is irrelevant to the prediction.
Update Gate:The update gate helps the model to determine how much of the past information (from previous time steps) needs to be passed along to the future. That is really powerful because the model can decide to copy all the information from the past and eliminate the risk of vanishing gradient problem.
Reset Gate: The reset gate is used from the model to decide how much of the past information to forget.
