Grammatical error correction (GEC) is the task of detection and correction of grammatical errors in ungrammatical text. Grammatical errors include errors such as spelling mistake, incorrect use of articles or prepositions, subject-verb disagreement, or even poor sentence construction. GEC has become an important NLP task, with applications ranging from auto-correct for email or text editors to a language learning aid.
Over the past decade, neural machine translation-based approaches to GEC, which generate the grammatical version of a sentence from its ungrammatical form, have dominated the field. However, their slow inference speed, large data requirement, and poor explainability has led to research toward text-edit approaches, which make modifications to ungrammatical sentences to produce their grammatical form.
In our work, we model GEC as a two-step problem that involves edits on the character level. The first subtask is deletion, where we fine tune a Reformer, an efficient character-level transformer, to predict whether or not to delete each character. The second step is insertion, where we predict which characters to insert between existing characters to produce a grammatical sentence. These operations can be trained independently, using the longest common subsequence between the ungrammatical and grammatical sentence as an intermediary label.
This repository contains code to recreate models generated for our project. This project was developed as part of coursework for COMPSCI-685: Advanced Natural Language Processing at UMass Amherst, Fall '21.
Download datasets from following locations:
Prepare the FCE dataset once downloaded using following code:
python utils/prepare_clc_fce_data.py <INPUT> --output <OUTPUT_FILE> Generate labelled data from FCE data by running following code:
python utils/process_FCE_data.py <OUTPUT_PATH> --truth <GRAMMATICAL_TEXT_PATH> --actual <ORIGINAL_TEXT_PATH>We propose a text-editing approach for GEC with two important differences from existing text-edit approaches:
- text-edits at the character level, and
- the division of GEC into two independent sub-tasks - deletion and insertion
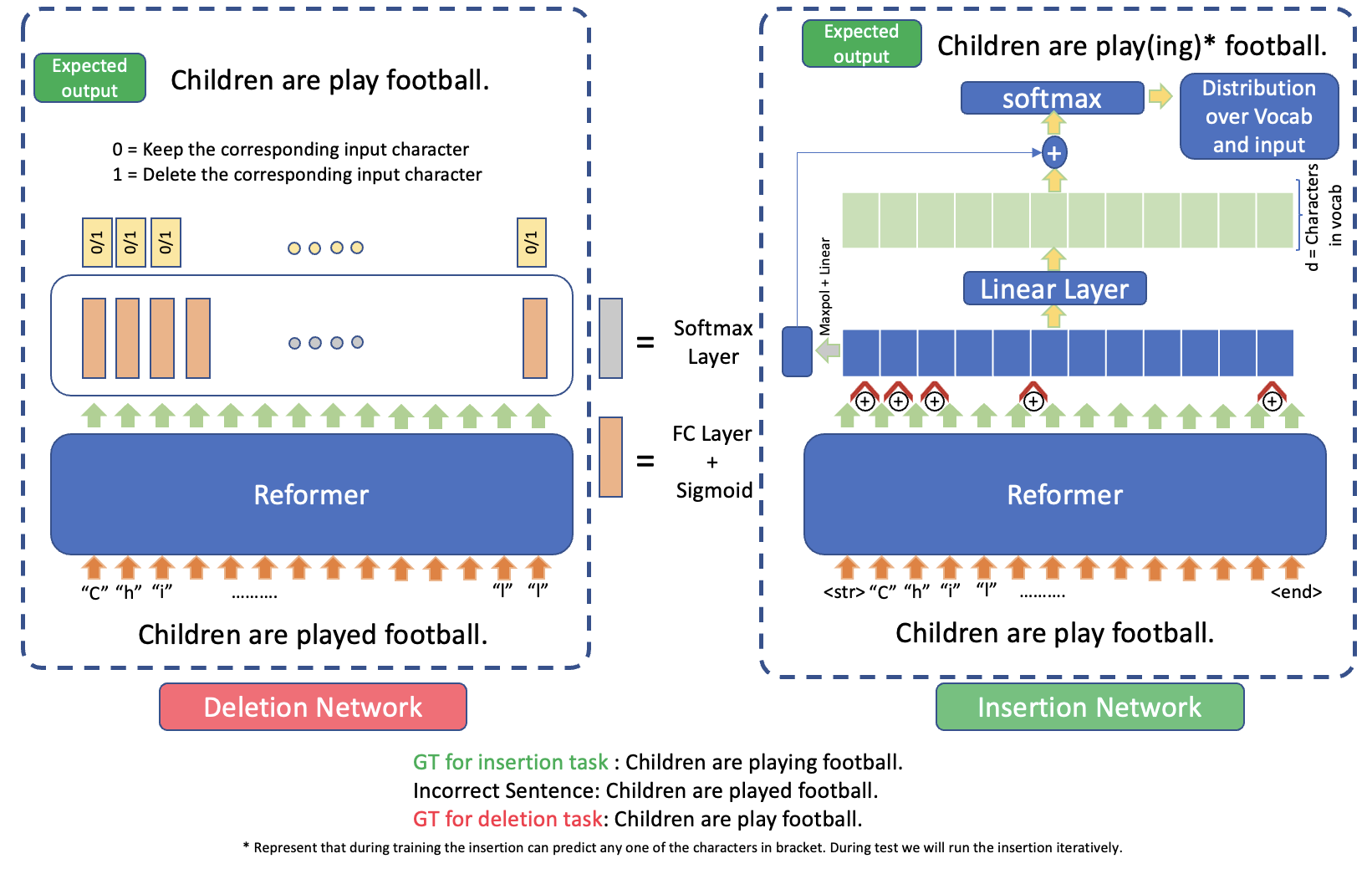
Since we treat the character deletion and character insertion subtasks as two independent problems, we implement and train two different models. Both the deletion and insertion models extend the Reformer, an efficient, character-level transformer.
The models for our project can be generated by executing following script:
python -m code.train -m <model>where -m flag determines the model to train (deletion or insertion), and -c flag followed by the path to a checkpoint allows the trainer to load a checkpoint. Alternatively model can be trained by running main.ipynb notebook.
Model can be tested by running the script:
python code.testFor the purpose of this project, we divided the FCE dataset into training and validation sets using a 9:1 split: 30,935 training examples and 3,555 validation examples. We trained the deletion and insertion models completely independently on the FCE training set using only Google Colab. We leveraged PyTorch Lightning, a wrapper around PyTorch, to help structure our project and simplify our training code. We evaluated each model on the validation set every half epoch, and stored checkpoints of the models with the lowest validation loss in Google Drive. We stopped training when no improvements in validation loss were made for five consecutive validation checks.
The best deletion model was trained for eight epochs with a learning rate of 1e-4. The best insertion model was trained for nineteen epochs with a learning rate of 1e-3. Both models were trained with a batch size of 32 using the Adam optimizer. The model for deletion model can be found here, while model for insertion model can be found here.
- Adam Viola (aviola@umass.edu)
- Rushikesh Dudhat (rdudhat@umass.edu)
- Shubham Shetty (shubhamshett@umass.edu)
- Pranjali Parse (pparse@umass.edu)