Fix pathologically slow translate groups on Linux #973
Conversation
Major performance improvement on GCC with libstdc++.
|
|
|
Ohhhh I can't wait go get to a PC to try this! |
|
OK I tried it - on this model #932 (comment) the time to set the last translate group to 6 copies is:
|
|
By the way the hot path is still moving all the entities "one down" from the insertion point. This is at 10000 samples/s so a full 12.7 seconds of the 15 total is spent there.
|
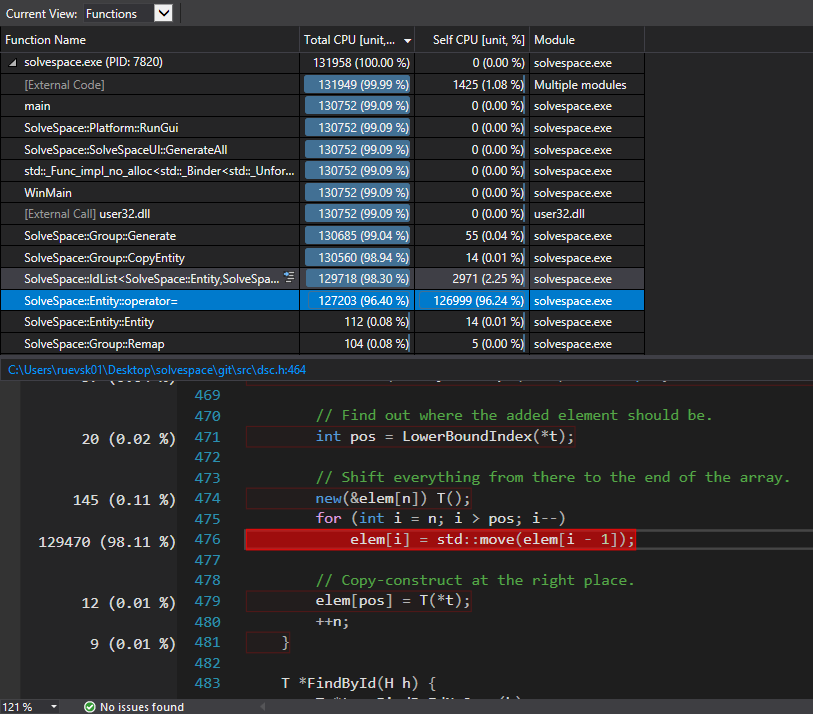
|
Yes, it is still doing a lot. The Just now I can make something as simple as a keyboard case without tearing my hair out. :) Perhaps a different data structure entirely would be appropriate, but I don't have any obvious favourites. The other thing that came to my mind was postponing the sort, which looked complicated. |
|
Wow, I think I touched that last before you. Blows my mind these are different performances, I would have expected nearly equivalent assembly after the optimizer had its way. |
|
@rpavlik it seems the people on the C++ committee have a new definition of "in-place". It needs to allocate extra space, can take O(N logN) time, and uses custom comparator. No idea why it would take worse than linear time give the need to allocate more space. Seem like a good function to avoid. |
|
Could we just do an insert instead of manually moving things? |
I'll try it. Anyway I am deep into it #939 (comment) But |
Major performance improvement on GCC with libstdc++, see my comments in #939. Relates to discussion in #932.
All tests passed, nothing interesting in memcheck showed up.
I think this belongs in 3.0 and is obvious enough.
I've tried to use
std::move_backwardsbut it didn't look better.