Preparation before Training
본 글은 AI Hub에서 제공하는 '한국어 음성데이터'에 대해 학습 진행을 위한 과정을 기록한 글입니다.
AI Hub 음성 데이터는 다음 링크에서 신청 후 다운로드 하실 수 있습니다.
AI Hub 한국어 음성 데이터 : http://www.aihub.or.kr/aidata/105
GitHub Repository : https://github.com/sooftware/End-to-end-Speech-Recognition
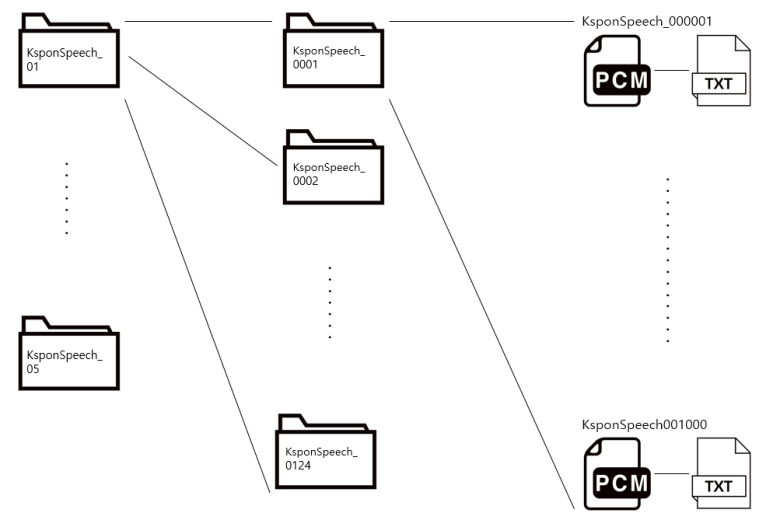
데이터는 총 123GB로 크게 5개의 폴더로 이루어져 있고, 각 폴더 안에는 124개의 폴더가 있다. 그리고 그 폴더 안에는 1,000개씩의 PCM-TXT 파일로 구성되어 있다. 조용한 환경에서 2,000여명이 발성한 한국어 1,000시간의 데이터로 구성되어 있다. 총 파일의 개수는 622,545개의 PCM-TXT 파일로 구성되어 있다.
※ 작업의 편의를 위하여 아래부터 이루어지는 작업은 모든 파일을 하나의 폴더 안에 모아서 작업했습니다 ※
-
KsponSpeech_FILENUM.pcm
-
KsponSpeech_FILENUM.txt
"b/ 아/ 모+ 몬 소리야 (70%)/(칠 십 퍼센트) 확률이라니 n/"
전처리를 위해 필요한 기본 함수들을 정의해보자.
def filenum_padding(filenum):
if filenum < 10:
return '00000' + str(filenum)
elif filenum < 100:
return '0000' + str(filenum)
elif filenum < 1000:
return '000' + str(filenum)
elif filenum < 10000:
return '00' + str(filenum)
elif filenum < 100000:
return '0' + str(filenum)
else:
return str(filenum)AI Hub 데이터셋에서 파일 번호는 '000001', '002545', '612543' 와 같은 형식으로 이루어져 있다.
이러한 형식에 맞춰주기 위하여 파일 번호를 입력으로 받아 해당 포맷에 맞춰주는 함수를 미리 정의해둔다.
def get_path(path, fname, filenum, format):
return path + fname + filenum + format텍스트 파일의 경로를 잡아주는 함수를 미리 정의해둔다.
Example )
BASE_PATH = "E:/한국어 음성데이터/KsponScript/"
FNAME = 'KsponScript_'
filenum = 1348
format = '.txt'
print(get_path(BASE_PATH,FNAME,filenum_padding(filenum),".txt"))Output
'E:/한국어 음성데이터/KsponSpeech/KsponScript_001348.txt'AI Hub에서 기본적으로 제공하는 음성에 대한 텍스트는 다음과 같다.
(철자전사) / (발음전사), 노이즈, 더듬는 소리 등 세밀하게 레이블링 되어 있다.
우리 팀은 Sound-To-Text 를 최대한 정확하게 하는 것이 목표였기에 다음과 같은 전처리 과정을 거쳤다.
- Raw Data
"b/ 아/ 모+ 몬 소리야 (70%)/(칠 십 퍼센트) 확률이라니 n/"
- b/, n/, / .. 등의 잡음 레이블 삭제
"아/ 모+ 몬 소리야 (70%)/(칠 십 퍼센트) 확률이라니"
- 제공된 (철자전사)/(발음전사) 중 발음전사 사용
"아/ 모+ 몬 소리야 칠 십 퍼센트 확률이라니"
- 간투어 표현 등을 위해 사용된 '/', '*', '+' 등의 레이블 삭제
"아 모 몬 소리야 칠 십 퍼센트 확률이라니"
다음은 위와 같은 전처리를 위해 사용한 코드이다.
(A) / (B) 일 때, B만을 가져와주는 함수이다.
(철자전사) / (발음전사) 중 발음전사를 선택하기 위해 정의했다.
test1 = "o/ 근데 (70%)/(칠십 퍼센트)가 커 보이긴 하는데 (200)/(이백) 벌다 (140)/(백 사십) 벌면 빡셀걸? b/"
test2 = "근데 (3학년)/(삼 학년) 때 까지는 국가장학금 바+ 받으면서 다녔던 건가?"
def bracket_filter(sentence):
new_sentence = str()
flag = False
for ch in sentence:
if ch == '(' and flag == False:
flag = True
continue
if ch == '(' and flag == True:
flag = False
continue
if ch != ')' and flag == False:
new_sentence += ch
return new_sentence
print(bracket_filter(test1))
print(bracket_filter(test2))Output
'o/ 근데 칠십 퍼센트가 커 보이긴 하는데 이백 벌다 백 사십 벌면 빡셀걸? b/'
'근데 삼 학년 때 까지는 국가장학금 바+ 받으면서 다녔던 건가?'문자 단위로 특수 문자 및 노이즈 표기 필터링해주는 함수이다.
특수 문자를 아예 필터링 해버리면 문제가 되는 '#', '%'와 같은 문자를 확인하고, 문제가 되는 특수 문자는 해당 발음으로 바꿔주었다.
import re
test1 = "o/ 근데 칠십 퍼센트가 커 보이긴 하는데 이백 벌다 백 사십 벌면 빡셀걸? b/"
test2 = "c# 배워봤어?"
def special_filter(sentence):
SENTENCE_MARK = ['?', '!']
NOISE = ['o', 'n', 'u', 'b', 'l']
EXCEPT = ['/', '+', '*', '-', '@', '$', '^', '&', '[', ']', '=', ':', ';', '.', ',']
new_sentence = str()
for idx, ch in enumerate(sentence):
if ch not in SENTENCE_MARK:
# o/, n/ 등 처리
if idx + 1 < len(sentence) and ch in NOISE and sentence[idx+1] == '/':
continue
if ch == '#':
new_sentence += '샾'
elif ch not in EXCEPT:
new_sentence += ch
pattern = re.compile(r'\s\s+')
new_sentence = re.sub(pattern, ' ', new_sentence.strip())
return new_sentence
print(special_filter(test1))
print(special_filter(test2))Output
'근데 칠십 퍼센트가 커 보이긴 하는데 이백 벌다 백 사십 벌면 빡셀걸?'
'c샾 배워봤어?'< . >, < , > 같은 문장 부호는 음성인식 태스크에서 중요하지 않을 뿐더러 음성신호만으로 예측하기 어렵다고 생각하여 제외하였다. < ? >, < ! > 는 음성 신호로부터 예측 가능하고 중요한 문장 부호라고 생각하여 필터링하지 않았다.
위에서 정의한 2 함수를 이용해서 문장을 필터링해주는 함수
test = "o/ 근데 (70%)/(칠십 퍼센트)가 커 보이긴 하는데 (200)/(이백) 벌다 (140)/(백 사십) 벌면 빡셀걸? b/"
def sentence_filter(raw_sentence):
return special_filter(bracket_filter(raw_sentence))
print(sentence_filter(test))Output
'근데 칠십 퍼센트가 커 보이긴 하는데 이백 벌다 백 사십 벌면 빡셀걸?'위의 과정을 끝내면 < % > 특수문자가 남게되는데, 해당 특수문자는 '프로', '퍼센트' 두 가지 발음이 가능하므로, 직접 확인한 결과 총 8개의 파일에서 등장했고, 4개의 **'프로'**와 4개의 '퍼센트' 이루어지는 것을 확인하고 수작업으로 변환했다.
위와 같이 AI Hub에서 제공되는 텍스트는 일정한 포맷의 '한글'로 구성되어 있다. 위의 한글 텍스트로는 학습을 시킬수가 없으므로, 컴퓨터가 이해할 수 있도록 '숫자'로 바꾸어 줘야 한다.
그러기 위해서 먼저, 데이터셋이 어떠한 문자들로 이루어져 있는지를 파악해야한다.
그럼 데이터셋에서 등장하는 모든 문자를 확인을 해보자.
import pandas as pd
from tqdm import trange # display progress
BASE_PATH = "E:/한국어 음성데이터/KsponSpeech/"
FNAME = 'KsponSpeech_'
TOTAL_NUM = 622545
label_list = []
label_freq = []
print('started...')
for filenum in trange(1,TOTAL_NUM):
f = open(get_path(BASE_PATH,FNAME,filenum_padding(filenum),".txt"))
sentence = f.readline()
f.close()
for ch in sentence:
if ch not in label_list:
label_list.append(ch)
label_freq.append(1)
else:
label_freq[label_list.index(ch)] += 1
# sort together Using zip
label_freq, label_list = zip(*sorted(zip(label_freq, label_list), reverse=True))
label = {'id': [0, 1, 2], 'char': ['<pad>', '<sos>', '<eos>'], 'freq': [0, 0, 0]}
for idx, (ch, freq) in enumerate(zip(label_list, label_freq)):
label['id'].append(idx)
label['char'].append(ch)
label['freq'].append(freq)
""" dictionary to csv """
label_df = pd.DataFrame(label)
label_df.to_csv("aihub_labels.csv", encoding="utf-8", index=False)위의 코드를 실행시켜서 정상적으로 종료됐다면 다음과 같은 파일이 생길 것이다.
| id | meaning |
|---|---|
| <s> | Start Of Sentence |
| </s> | End Of Sentence |
| _ | PAD |
( 위의 문자들은 수동으로 추가 )
| id | char | freq |
|---|---|---|
| 0 | 5774462 | |
| 1 | . | 640924 |
| 2 | 그 | 556373 |
| 3 | 이 | 509291 |
| . | . | . |
| . | . | . |
| 2334 | <s> | 0 |
| 2335 | </s> | 0 |
| 2336 | _ | 0 |
수동으로 추가해 준 3개의 레이블을 포함하여 총 2,337개의 문자 레이블이 완성되었다.
우리 팀은 위의 레이블 리스트 중 1번씩 등장한 문자에 주목했다.
'갗', '괞', '긃' 등의 생소한 문자가 약 300개 정도를 차지했는데 우리 팀은 이러한 레이블은 노이즈가 될 것이라고 생각했고, 이에 대한 처리를 고민했다. 1번씩 등장한 파일들을 확인해서 하나하나 수작업으로 레이블을 바꿔주려 했지만, 실제로 음성 파일을 들어보게 되면 바꿔주기가 상당히 애매했다.
| id | char | freq |
|---|---|---|
| 0 | 5774462 | |
| 1 | . | 640924 |
| 2 | 그 | 556373 |
| 3 | 이 | 509291 |
| . | . | . |
| . | . | . |
| 2037 | <s> | 0 |
| 2038 | </s> | 0 |
| 2039 | _ | 0 |
그래서 우리는 이렇게 1번씩 등장한 문자가 포함된 파일은 테스트 데이터로 사용하고, 2번 이상 등장한 문자들만 있는 파일들로만 트레이닝 데이터를 구성했다. 이렇게 1번씩 등장한 300여개의 문자들이 포함된 파일들을 제외를 해서, 위의 표처럼 2,040개의 문자로만 트레이닝을 시킬 수 있었다.
- train_labels.csv : 1번씩 등장한 문자를 제외한 2,040개의 문자 레이블
- test_labels.csv : 데이터셋에서 등장한 2,337개의 문자 레이블
링크 : https://github.com/sh951011/Korean-Speech-Recognition/tree/master/data/label
이제 위에서 만든 Character label을 이용해서 한글로 이루어진 텍스트를 숫자로 바꿔보자.
먼저 만들어둔 문자 레이블 파일을 이용하여 문자를 id로, id를 문자로 만드는 딕셔너리 변수를 만든다.
import pandas as pd
def load_label(filepath):
char2id = dict()
id2char = dict()
ch_labels = pd.read_csv(filepath, encoding="cp949")
id_list = ch_labels["id"]
char_list = ch_labels["char"]
freq_list = ch_labels["freq"]
for (id, char, freq) in zip(id_list, char_list, freq_list):
char2id[char] = id
id2char[id] = char
return char2id, id2char이제 char2id 변수를 이용하여 한글 텍스트 문장을 숫자로 바꿔보자.
한글 텍스트를 숫자 레이블로 변환해주는 함수
test = '근데 칠십 퍼센트가 커 보이긴 하는데 이백 벌다 백 사십 벌면 빡셀걸?'
def sentence_to_target(sentence, char2id):
target = ""
for ch in sentence:
target += (str(char2id[ch]) + ' ')
return target[:-1]
print(sentence_to_target(test, char2id))Output
'35 11 0 318 119 0 489 551 156 6 0 379 0 42 3 144 0 14 4 11 0 3 248 0 355 15 0 248 0 34 119 0 355 24 0 588 785 104 12'텍스트를 미리 만들어둔 문자 레이블을 이용하여 숫자로 바꿔주었다.
숫자끼리는 띄어쓰기로 구분해주었다.
문장 마지막에 붙는 띄어쓰기는 의미가 없어서 target[:-1]로 제거해준 뒤 반환했다.
잘 변환되었는지 확인하기 위해 이 숫자 레이블을 다시 한글 텍스트로 변환해보자.
숫자 레이블을 한글 텍스트로 변환해주는 함수
test = '35 11 0 318 119 0 489 551 156 6 0 379 0 42 3 144 0 14 4 11 0 3 248 0 355 15 0 248 0 34 119 0 355 24 0 588 785 104 12'
def target_to_sentence(target, id2char):
sentence = ""
targets = target.split()
for n in targets:
sentence += id2char[int(n)]
return sentence
print(target_to_sentence(test, id2char))Output
'근데 칠십 퍼센트가 커 보이긴 하는데 이백 벌다 백 사십 벌면 빡셀걸?'기존 한글 텍스트로 정상적으로 변환된 것을 확인했다.
이로써 한글 텍스트에서 숫자레이블로, 숫자레이블에서 한글 텍스트로의 변환을 자유자재로 할 수 있게 되었다.
이제 이 함수들을 이용해서 전체 데이터셋에 대하여 변환해주기만 하면 된다.
import pandas as pd
from tqdm import trange # display progress
BASE_PATH = "E:/한국어 음성데이터/KsponSpeech/"
FNAME = 'KsponSpeech_'
NEW_FNAME = 'KsponScript_'
TOTAL_NUM = 622545
char2id, id2char = load_label("test_labels.csv")
print('started...')
for filenum in trange(1,TOTAL_NUM):
sentence, target = None, None
with open(get_path(BASE_PATH,FNAME,filenum_padding(filenum),".txt"), "r") as f:
sentence = f.readline()
with open(get_path(BASE_PATH, NEW_FNAME, filenum_padding(filenum),".txt"), "w") as f:
target = sentence_to_target(sentence, char2id)
f.write(target)위 까지의 과정을 통해서 기존 Raw 데이터셋에서 우리가 원하는 데이터셋의 형태로의 변환 및 숫자 레이블로의 변환까지 마쳤다.
이제 학습을 진행하기 위해 위와 같은 트레이닝 / 테스트 데이터 리스트를 만들어보자.
import pandas as pd
TOTAL_NUM = 622545
TRAIN_NUM = int( 622545 * 0.98 )
TEST_NUM = TOTAL_NUM - TRAIN_NUM
train_data_list = {'audio':[], 'label':[]}
test_data_list = {'audio':[], 'label':[]}
aihub_labels = pd.read_csv("test_labels.csv", encoding='cp949')
rare_labels = aihub_labels['char'][2037:]먼저 우리는 총 1,000시간 중 980시간을 훈련데이터, 20시간을 테스트데이터로 사용할 것이기 때문에 총 파일 개수의 98%에 해당하는 숫자를 TRAIN_NUM으로 계산해주고 나머지 숫자를 TEST_NUM으로 정의해주었다.
미리 만들어 둔 test_labels.csv 파일을 불러오고, 1번만 언급된 문자들은 rare_labels에 저장해준다.
from tqdm import trange
fname = 'KsponSpeech_'
target_fname = 'KsponScript_'
audio_paths = []
target_paths = []
for filenum in trange(1, TOTAL_NUM):
audio_paths.append(fname + file_padding(filenum) + ".pcm")
target_paths.append(target_fname + file_padding(filenum) + ".txt")다음으로 오디오 파일과 타겟 텍스트 파일 경로를 리스트에 저장한다.
import random
data_paths = list(zip(audio_paths, target_paths))
random.shuffle(data_paths)
audio_paths, target_paths = zip(*data_paths)1번부터 622545번까지 순서대로 넣었으므로, 순서를 섞어준다.
이때, audio_paths와 target_paths를 같은 순서로 섞어주기 위해 zip()을 이용하여 섞어준다.
from tqdm import trange
path = "G:/한국어 음성데이터/KsponSpeech/"
train_full = False
train_dict = {
'audio': [],
'label': []
}
test_dict = {
'audio': [],
'label': []
}
print('started...')
for idx in trange(length = len(audio_paths)):
audio = audio_paths[idx]
target = target_paths[idx]
if len(train_dict['audio']) == TRAIN_NUM:
train_full = True
if train_full:
test_dict['audio'].append(audio)
test_dict['label'].append(label)
else:
rare_in = False
sentence = None
with open((path+audio).split('.')[0]+".txt") as f:
sentence = f.readline()
for rare in rare_labels:
if rare in sentence:
rare_in = True
break
if rare_in:
test_dict['audio'].append(audio)
test_dict['label'].append(label)
else:
train_dict['audio'].append(audio)
train_dict['label'].append(label)
print("Ended!!!")랜덤하게 섞여진 audio_paths와 target_paths를 이용하여 train_dict와 test_dict를 만든다.
이때 rare_labels에 있는 문자가 포함된 파일은 test_dict로 넣어준다.
test_df = pd.DataFrame(test_dict)
train_df = pd.DataFrame(train_dict)
test_df.to_csv("test_list.csv", encoding='cp949', index=False)
train_df.to_csv("train_list.csv", encoding='cp949', index=False)train_dict와 test_dict를 DataFrame 형태로 변환 후에 to_csv 메서드로 csv 파일로 만들어준다.
- train_list.csv
학습용 데이터 리스트 - 980h
| pcm-filename | txt-filename |
|---|---|
| KaiSpeech_078903.pcm | KaiSpeech_label_078903.txt |
| KaiSpeech_449461.pcm | KaiSpeech_label_449461.txt |
| KaiSpeech_178531.pcm | KaiSpeech_label_178531.txt |
| KaiSpeech_374874.pcm | KaiSpeech_label_374874.txt |
| KaiSpeech_039018.pcm | KaiSpeech_label_039018.txt |
- test_list.csv
테스트용 데이터 리스트 - 20h
| pcm-filaname | txt-filename |
|---|---|
| KaiSpeech_126887.pcm | KaiSpeech_label_126887.txt |
| KaiSpeech_067340.pcm | KaiSpeech_label_067340.txt |
| KaiSpeech_350293.pcm | KaiSpeech_label_350293.txt |
| KaiSpeech_212197.pcm | KaiSpeech_label_212197.txt |
| KaiSpeech_489840.pcm | KaiSpeech_label_489840.txt |
data list 링크 : https://github.com/sh951011/Korean-Speech-Recognition/tree/master/data/data_list
해당 작업에 대하여 에러, 문의사항 모두 환영합니다.
sh951011@gmail.com 으로 연락주시면 감사하겠습니다.