Uniform Length Batching
2020-03-03
현재 AI Hub Dataset #3 모델 학습을 진행중이다.
학습을 진행하다보니, 학습 시간이 지나치게 오래 걸렸다.

그래서 팀원들과 개선할 점을 찾아보다가 텍스트 분야에서 많이 쓰이는 방법인,
비슷한 길이끼리 배치를 묶어주는 기법을 적용할지를 고민했다.
그래서 한번 현재 어떤 식으로 배치가 이뤄지는지를 찍어보았다.

2,039 (PAD_TOKEN) 이 굉장히 많이 찍힌 것을 확인했다.
한 배치를 묶을 때, 모든 시퀀스 길이가 동일해야하므로, 가장 긴 시퀀스에 맞춰서 PAD_TOKEN을 더해주기 때문에 위와 같이 행렬의 대부분을 PAD_TOKEN이 차지하고 있었다.
현재 학습 시간이 오래 걸리는 점을 조금이나마 보완해볼 생각이였는데,
직접 찍어보니 비슷한 길이의 시퀀스로 묶어주기만 해도 학습 속도가 상당히 개선될 것으로 보였다.
그래서 비슷한 길이의 배치로 묶으면 배치가 어떤 식으로 구성되는지를 확인해봤다.
def sort_by_length(self):
""" descending sort by sequence length """
target_lengths = list()
for idx, label_path in enumerate(self.label_paths):
key = label_path.split('/')[-1].split('.')[0]
target_lengths.append(len(self.target_dict[key].split()))
bundle = list(zip(target_lengths, self.audio_paths, self.label_paths, self.augment_flags))
junk, self.audio_paths, self.label_paths, self.augment_flags = zip(*sorted(bundle, reverse=True))먼저 BaseDataset Class에 sort_by_length라는 메서드를 정의해서 타겟 시퀀스의 길이순으로 내림차순 정렬을 했다.
def batch_shuffle(self, remain_drop = False):
""" batch shuffle """
total_audio_batch, total_label_batch, total_augment_flag = [], [], []
audio_paths, label_paths, augment_flags = [], [], []
index = 0
while True:
if index == len(self.audio_paths):
if len(audio_paths) != 0:
total_audio_batch.append(audio_paths)
total_label_batch.append(label_paths)
total_augment_flag.append(augment_flags)
break
if len(audio_paths) == self.batch_size:
total_audio_batch.append(audio_paths)
total_label_batch.append(label_paths)
total_augment_flag.append(augment_flags)
audio_paths, label_paths, augment_flags = [], [], []
audio_paths.append(self.audio_paths[index])
label_paths.append(self.label_paths[index])
augment_flags.append(self.augment_flags[index])
index += 1
remain_audio, remain_label, remain_augment_flag = total_audio_batch[-1], total_label_batch[-1], total_augment_flag[-1]
total_audio_batch, total_label_batch, total_augment_flag = total_audio_batch[:-1], total_label_batch[:-1], total_augment_flag[:-1]
bundle = list(zip(total_audio_batch, total_label_batch, total_augment_flag))
random.shuffle(bundle)
total_audio_batch, total_label_batch, total_augment_flag = zip(*bundle)
audio_paths, label_paths, augment_flags = [], [], []
for (audio_batch, label_batch, augment_flag) in zip(total_audio_batch, total_label_batch, total_augment_flag):
audio_paths.extend(audio_batch)
label_paths.extend(label_batch)
augment_flags.extend(augment_flag)
audio_paths = list(audio_paths)
label_paths = list(label_paths)
augment_flags = list(augment_flags)
if not remain_drop:
audio_paths.extend(remain_audio)
label_paths.extend(remain_label)
augment_flags.extend(remain_augment_flag)
return audio_paths, label_paths, augment_flags그리고 batch_shuffle라는 비슷한 길이로 묶인 배치들끼리 섞어주는 메서드를 구현했다.
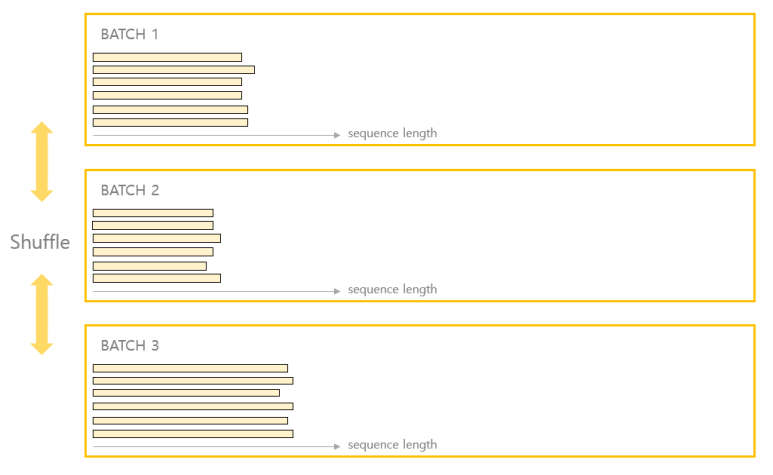
위와 같은 2개의 메서드를 구현 후, 실제 배치들이 어떤 식으로 묶이는지 확인해봤다.
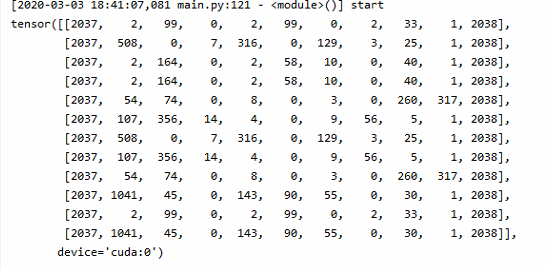
적용 이전의 배치와 확연히 다른 모습을 보이는 것을 확인할 수 있다.
해당 배치에는 2039 (PAD_TOKEN) 이 하나도 들어가 있지 않도록 배치되었다.
PAD_TOKEN이 최소화되어 들어가므로, 디코딩 과정에서 학습 시간을 단축시킬 수 있을 것으로 보인다.