Data Analysis
학습 도중 계속 CUDA OOM (Out-Of-Memory) 에러가 발생하여 데이터 분석을 진행했습니다.
먼저, 미리 저장해뒀던 target_dict pickle 파일을 로드하겠습니다.
import pickle
target_dict = None
with open('./data/pickle/target_dict.bin', "rb") as f:
target_dict = pickle.load(f)target_dict 파일은 다음과 같은 형식으로 이루어져 있습니다.
| Filename | label |
|---|---|
| 'KaiSpeech_label_268389' | '425 482 602 0 42 204 32 ...' |
| 'KaiSpeech_label_181280' | '13 18 0 2 33 0 13 ...' |
| 'KaiSpeech_label_440942' | '8 1 0 333 3 0 333 3 46 0 86 58 ...' |
| 'KaiSpeech_label_360927' | '35 11 0 2 0 194 ...' |
| 'KaiSpeech_label_428848' | '59 43 0 3 0 239 33 6 0 10 300 212 ...' |
원래 학습이 시작되면 모든 파일들을 로딩하면서 target_dict 변수를 만들지만, 매 학습시마다 60만개의 파일 관련 I/O 시간을 줄이기 위해 피클 파일로 저장을 해뒀었습니다.
label_paths = []
targets = []
for (label_path, target) in zip(target_dict.keys(), target_dict.values()):
label_paths.append(label_path)
targets.append(target)다음으로 target_dict를 다루기 쉽게 2개의 리스트로 나눴습니다.
target_lengths = []
for target in targets:
target_lengths.append(len(target.split()))그리고 데이터 각각의 시퀀스 길이를 분석하기 위해 target_lengths라는 리스트에 각 데이터의 시퀀스 길이를 삽입합니다.
import matplotlib.pyplot as plt
import seaborn as sns
sns.boxplot(target_lengths)
plt.show()Output
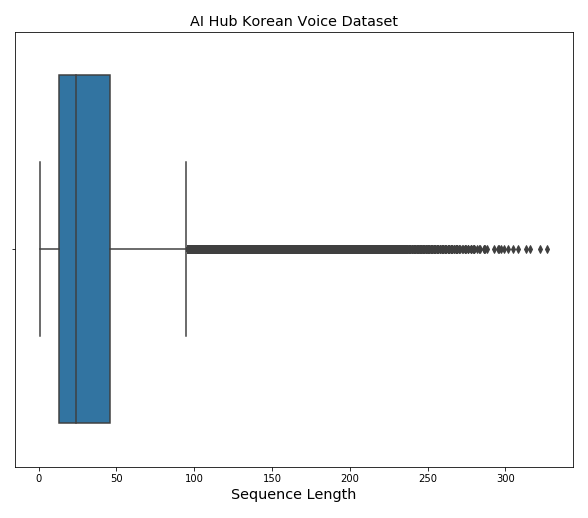
그리고 데이터 분석을 위해 Box-Plot을 그려봤습니다.
Sequence Length 100 정도를 기준으로 Outlier로 판단됩니다.
import numpy as np
np.sum(np.array(target_lengths) > 100)Output
28607
시퀀스 길이가 100 이상인 데이터의 개수를 카운트해 보았습니다.
28607개로 파악됩니다.
Training 데이터의 수는 610,092개이므로, 4.68% 정도의 데이터로 파악됩니다.
28,607개의 데이터는 너무 많다고 판단되어 한번 직접 확인해봤습니다.
먼저 2개의 함수를 미리 정의했습니다.
def label_to_string(labels, id2char, eos_id):
tokens = target.split()
sentence = str()
for token in tokens:
if int(token) == eos_id:
break
sentence += id2char[int(token)]
return sentenceimport csv
def load_label(label_path, encoding='utf-8'):
char2id = dict()
id2char = dict()
with open(label_path, 'r', encoding=encoding) as f:
labels = csv.reader(f, delimiter=',')
next(labels)
for row in labels:
char2id[row[1]] = row[0]
id2char[int(row[0])] = row[1]
return char2id, id2charExecute
char2id, id2char = load_label('./data/label/train_labels.csv', encoding='utf-8')
EOS_TOKEN = int(char2id['</s>'])
scripts = []
for target in targets:
scripts.append(label_to_string(target, id2char, EOS_TOKEN))
성공적으로 실행됐다면, scripts에는 기존 숫자로 되어있던 레이블이 한글로 변환이 되었을 것입니다.
import pandas as pd
data = dict()
data['label_path'] = label_paths
data['target_length'] = target_lengths
data['script'] = scripts
data = pd.DataFrame(data)
data.head()Output
| label_path | target_length | script |
|---|---|---|
| KaiSpeech_label_268389 | 16 | 패션쇼 보느라 정신이 없었어. |
| KaiSpeech_label_181280 | 17 | 나도 그래 나도 겁나 치대잖아. |
| KaiSpeech_label_440942 | 20 | 어. 둘이 둘이만 여러 번 만났었어. |
| KaiSpeech_label_360927 | 23 | 빨리 차리면은 우리도 거기 가서 놀 텐데. |
| KaiSpeech_label_428848 | 104 | 근데 그 선수를 되게 좋아했었어. 그 선수가 되게 싼 가격에 오고 엄청나게 가성비가... |
성공적으로 변환이 된 것을 확인할 수 있었습니다.
저희가 관심있었던 것은 Outlier이기 때문에, Outlier만을 csv파일로 만들어서 분석해보았습니다.
outlier = data[data['target_length'] > 100]
outlier.to_csv('outlier.csv', encoding='cp949', index=False)outlier.csv 파일은 이곳에서 다운받아서 보실 수 있습니다.
분석 결과, 저희 팀은 150 글자를 넘어가는 데이터를 아웃라이어로 결정했습니다.
np.sum(np.array(target_lengths) > 150)Output
8455
약 1.4% 정도의 데이터로 Outlier로 줄일 수 있었습니다.
이 결과를 바탕으로 새로운 target_dict인 new_target_dict를 만들고, pickle 파일로 저장시켜 보겠습니다.
clean_data = data[data['target_length'] < 151]
label_paths = clean_data['label_path']
new_target_dict = dict()
for label_path in label_paths:
new_target_dict[label_path] = target_dict[label_path]
with open('./data/pickle/new_target_dict.bin', "wb") as f:
pickle.dump(new_target_dict, f)위의 코드가 정상적으로 실행됐다면, 저희가 판단한 outlier를 제거한 Training Dataset이 완성되었습니다.
