
- Upload JAR files on S3 Bucket and then add the path in your glue script as shown in image and copy paste the code and make sure to change base s3 path
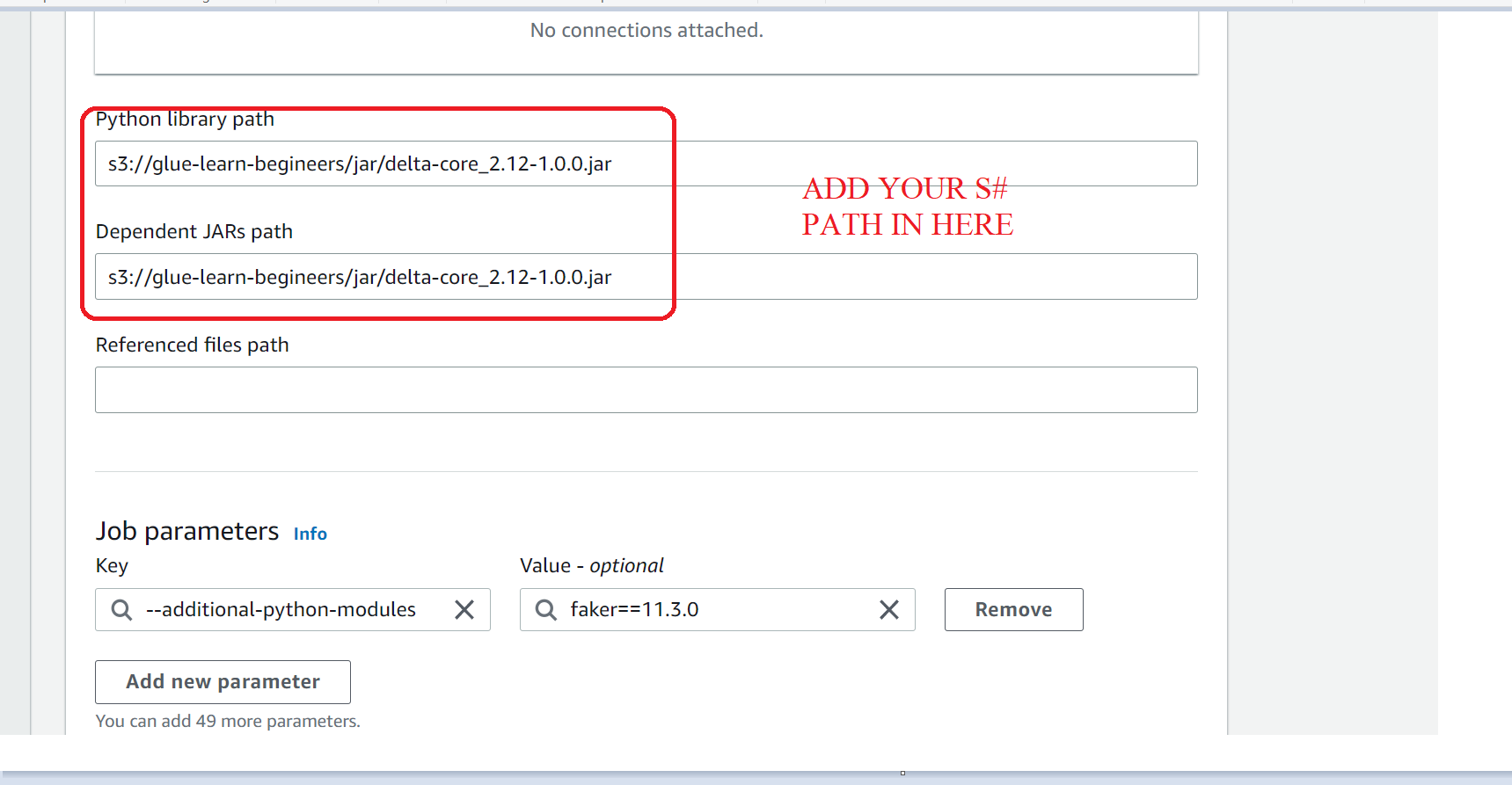
--additional-python-modules : faker==11.3.0
IN GLUE SCRIPT CHANGE HERE
base_s3_path = "s3a://YOUR S3 BUCKET"
-
How to Write | Read | Query Delta lake using AWS Glue and Athena for Queries for Beginners
-
Getting started with Delta lakes Pyspark and AWS Glue (Glue Connector)
-
INSERT | UPDATE |DELETE| READ | CRUD |on Delta lake(S3) using Glue PySpark Custom Jar Files & Athena
-
How do I use Glue to convert existing small parquet files to larger parquet files on Delta Lake
-
Upsert | Find One and Update in Delta Lake Using Glue Pyspark and Convert Small File into Large File
-
Video: https://youtu.be/861mVVgmXw4
-
Getting started with Apache Hudi with PySpark and AWS Glue #1 Intro
-
Different table types in Apache Hudi | MOR and COW | Deep Dive | By Sivabalan Narayanan
-
Insert | Update | Delete On Datalake (S3) with Apache Hudi and glue Pyspark
-
Build a Spark pipeline to analyze streaming data using AWS Glue, Apache Hudi, S3 and Athena