Task id hashing #1444
Task id hashing #1444
Conversation
|
this looks great! |
| param_str = json.dumps(params, separators=(',', ':'), sort_keys=True) | ||
| param_hash = hashlib.md5(param_str.encode('utf-8')).hexdigest() | ||
|
|
||
| param_summary = '_'.join(p[:TASK_ID_TRUNCATE_PARAMS] |
There was a problem hiding this comment.
you should probably remove non-alphanumeric characters from param_summary
There was a problem hiding this comment.
Done, all non-alphanumeric (+ "") converted to "".
|
this is great – would be great if some other people can weigh in. @Tarrasch @econchick @freider ? |
|
It's worth saying that we don't use Hadoop or any of the other integrations so they won't get tested by me. Further input would be good. |
|
hadoop has tests in travis so should be fine |
| task_id_parts = [] | ||
| param_objs = dict(params) | ||
| for param_name, param_value in param_values: | ||
| if param_objs[param_name].significant: |
There was a problem hiding this comment.
Now, since we're not sending this to the scheduler any more. Maybe we should include the insignificant parameters too?
(What I'm suggesting is to remove this one line)
There was a problem hiding this comment.
I'm undecided. Maybe people will want to keep repr() short by marking configuration parameters as insignificant? I don't use this feature so I don't really have an opinion.
There was a problem hiding this comment.
__repr__ is only used to assist debugging right? yeah in that case let's include all params
|
Looks good. :) I know that @ulzha is usually saying wise things when it comes to design. Do you have any thoughts on this Uldis? |
|
@stephenpascoe You should not need to worry about other modules breaking as everything in luigi is (usually) tested by Travis. :) |
|
Sorry for being late for discussion, but I would have loved to see URIfication for task id serialization. Like |
|
@sisidra my concern using |
|
@sisidra, For serialization we have the JSON {'family': ..., 'params': ...} returned by the API. You could URIfy that if you wanted, with correct escaping. |
7c2873c
to
1a2ef69
Compare
|
This branch has been running in production for a week without issue. A couple of tests are failing because of a syntax error in the HTTPretty mocking library which has not been fixed in pypi. AFAIK the only outstanding issue is the version number. I suggest 2.1.1 would be suitable, considering how recently we moved to 2.0. |
|
sgtm. but users have to run a migration script right? |
|
Migration script has been removed. The schema is now automatically upgraded. |
|
that's great. cool. let's merge this! |
|
Will merge on a successful build. Then let's have it sit in master for say two weeks before we publish to PyPI. I'm still a bit scared :) |
|
HTTPretty fix requested at gabrielfalcao/HTTPretty#278 |
|
let's just set the version of httpretty in tox.ini to the latest working version |
0ff8e98
to
a1e4d61
Compare
|
I think the commit history is a bit too dirty for merge. In particular no reverting commits or "fix pep8" commits should be in the commit log. I believe. Having those makes reverting commits much harder for us maintainers. Other than that. Looks good. |
|
Squashed some commits. |
|
All tests passing. Ready to merge? |
|
LET'S MERGE |
|
let's see if this causes any trouble |
|
Great. 👍 |
|
Wow, this finally happened. Amazing execution of this @stephenpascoe! |
|
@stephenpascoe, do you think this will cause breakage for this use case? Lines 98 to 102 in 154c283 I mean people who upgrade notice that all their |
|
@Tarrasch, yes, it looks like it. You could migrate the database by locating each row via |
|
Hmm... I suppose the renaming of tables also isn't easy either since each db renames tables in different ways. |
|
Migration tools like alembic can do it so I guess we could work it out for anything using sqlalchemy. Do you think it is enough to move the table to a backup and start again? |
|
Not sure of exactly what you mean with "move the table to a backup and start again". But happy with any solution that strikes a reasonable work-for-maintainers/work-for-users balance. |
|
in retrospect that mechanism wasn't great to start with, we shouldn't have had it in the code. where is |
|
Unfortunately I believe it's quite widely used. All CopyToTable jobs would be affected. |
I can totally see what tempted the authors to write that, it's so convenient and short! :) |
|
There is also |
|
a dumb temporary fix would be to put back the old task_id code into |
|
is there some automatic way of converting an old task_id into a new style task_id? in that case we can try to migrate the marker tables |
|
We can convert old_task_id to new_task_id in cases where we don't run into the original deserialisation problems (param values containing [ "'=] etc. ) We can convert using an instantiated Task instance if we roll-back the change to |
|
Hmm. I wonder if we can just not care about fixing backward compatibility for the database-target issue. Since luigi is a bit makeish, I think all data will be generated where-ever needed/requested in the dependency chain. I mean, surely people have added parameters and then had all their database uploads being done again without them really caring. The database ingestions are in many cases small compared to the data crunched to produce the ingestion data. |
|
Again thanks for this contribution @stephenpascoe. But I noticed a minor niceness glitch in the visualiser that I think is because of this PR: Before:
After:
I mean that the parameters are formatted like a python dict now and not in the slightly nicer |
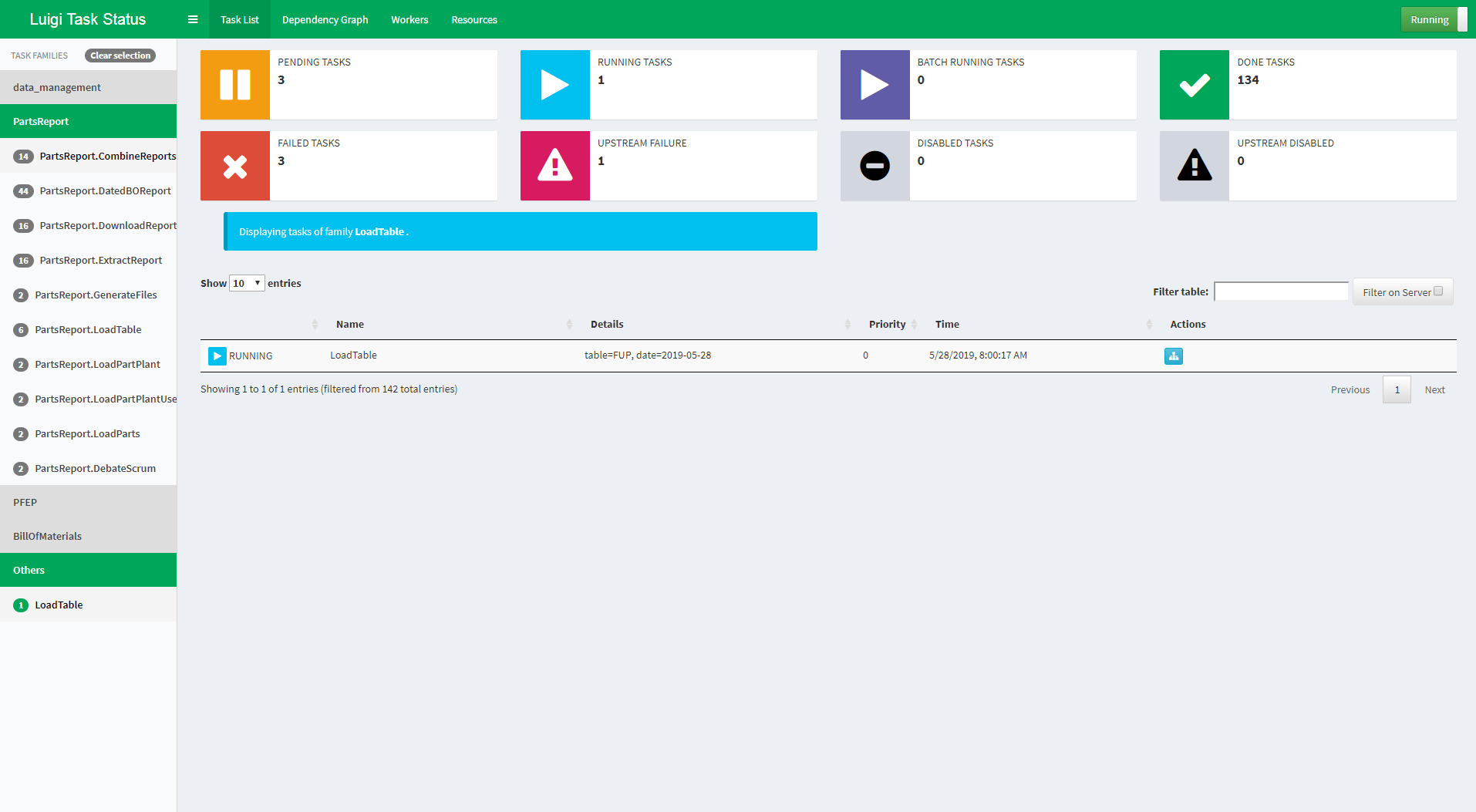

|
Yes, I was aware of this. I can fix it. Stephen Pascoe from iPhone
|
|
Thanks for verifying! Kudos for fixing :) |
New hashed task_ids implemented. See spotify#1444.
Implementing semi-opaque, hashed task_ids as discussed at #1312.
This is the version I will be testing on our infrastructure in the next few weeks. This PR is intended to give my proposal better visibility whilst I test.
The PR replaces task_ids with a value which is reliably unique but you can't extract the full parameter values from it. The actual algorithm is
family_pval1_pval2_pval3_hashwhere:str(task)will return the traditional serialisation.The db_task_history database schema is changed to include tash_id in the tasks table. No further use is made of this column at this stage. A migration script is supplied to add the column to an existing database. This has been tested on MySQL only.
All tests are updated to pass by replacing hard-coded task_ids with reference to
Task.task_id.