GraphQL
Вот три наиболее важные проблемы, которые решает GraphQL:
- Необходимость несколько раз обращаться за данными для рендеринга компонента. GraphQL позволяет получить все необходимые данные за один запрос к серверу.
- Зависимость клиента от сервера. С помощью GraphQL клиент общается на универсальном языке запросов, который: 1) отменяет необходимость для сервера жестко задавать структуру или состав возвращаемых данных и 2) не привязывает клиента к конкретному серверу.
- Неэффективные способы разработки. На GraphQL разработчики описывают необходимые для интерфейса данные с помощью декларативного языка. Разработчики сосредоточены на том, что хотят получить, а не как это сделать. Данные, необходимые для UI, тесно связаны с тем, как эти же данные описываются в GraphQL.
Большая проблема REST API в многочисленности точек назначения (endpoints). Это вынуждает клиентов делать много запросов, чтобы получить нужные данные.
REST API представляет собой набор точек назначения, каждая из которых соответствует ресурсу. Если клиенту нужны разные ресурсы, приходится делать несколько запросов, чтобы собрать все необходимые данные.
REST API не предлагает клиенту язык запросов. Клиент не влияет на то, какие данные возвращает сервер. Просто нет языка, на котором клиент мог бы указать это. Точнее говоря, доступные клиенту средства влиять на сервер очень ограничены.
Например, точка назначения для операции READ позволяет сделать одно из двух:
GET /ResouceName – получить список записей;
GET /ResourceName/ResourceID – получить запись по ID.
Клиент не может указать, например, какие поля записи хочет взять у данного ресурса. Эта информация зашита в самом REST-сервисе, и он всегда вернет все предусмотренные поля независимо от того, какие из них нужны клиенту. В GraphQL эта проблема называется перевыгрузкой (over-fetching) информации, которая не требуется. Перевыгрузка напрасно нагружает сеть и расходует память на стороне клиента и сервера.
Еще одна значимая проблема REST API – версионирование. Необходимость поддерживать несколько версий означает новые точки назначения. Это влечет дополнительные трудности в использовании и поддержке API и может стать причиной дублирования кода на сервере.
GraphQL - это синтаксис, который описывает как запрашивать данные, и, в основном, используется клиентом для загрузки данных с сервера. GraphQL имеет три основные характеристики:
- Позволяет клиенту точно указать, какие данные ему нужны.
- Облегчает агрегацию данных из нескольких источников.
- Использует систему типов для описания данных.
GraphQL был разработан в большом старом Facebook, но даже гораздо более простые приложения могут столкнуться с ограничениями традиционных REST API интерфейсов.
Например представьте, что нужно отобразить список записей (posts), и под каждым опубликовать список лайков (likes), включая имена пользователей и аватары. На самом деле, это не сложно, необходимо просто изменить API posts так, чтобы оно содержало массив likes, в котором будут объекты-пользователи.

Но затем, при разработке мобильного приложения, оказалось что из-за загрузки дополнительных данных приложение работает медленнее. Так что вам теперь нужно два endpoint, один возвращающий записи с лайками, а другой без них.
Добавим ещё один фактор: оказывается, записи хранятся в базе данных MySQL, а лайки в Redis! Что же теперь делать?!
Экстраполируйте этот сценарий на то множество источников данных и клиентских API, с которыми имеет дело Facebook, и вы поймёте почему старый добрый REST API достиг своего предела.
Facebook придумал концептуально простое решение: вместо того, чтобы иметь множество "глупых" endpoint, лучше иметь один "умный" endpoint, который будет способен работать со сложными запросами и придавать данным такую форму, какую запрашивает клиент.
Фактически, слой GraphQL находится между клиентом и одним или несколькими источниками данных; он принимает запросы клиентов и возвращает необходимые данные в соответствии с переданными инструкциями. Запутаны? Время метафор!
Пользоваться старой REST-моделью это как заказывать пиццу, затем заказывать доставку продуктов, а затем звонить в химчистку, чтобы забрать одежду. Три магазина – три телефонных звонка.
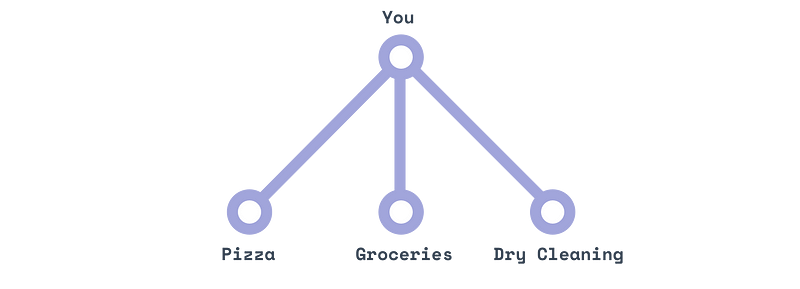
GraphQL похож на личного помощника: вы можете передать ему адреса всех трех мест, а затем просто запрашивать то, что вам нужно («принеси мне мою одежду, большую пиццу и два десятка яиц») и ждать их получения.
На практике GraphQL API построен на трёх основных строительных блоках: на схеме (schema), запросах (queries) и распознавателях (resolvers).
Когда вы о чём-то просите вашего персонального помощника, вы выполняете запрос. Это выглядит примерно так:
query {
stuff
}Мы объявляем новый запрос при помощи ключевого слова query, также спрашивая про поле stuff. Самое замечательное в запросах GraphQL является то, что они поддерживают вложенные поля, так что мы можем пойти на один уровень глубже:
query {
stuff {
eggs
shirt
pizza
}
}Как можно заметить, клиенту при формировании запроса не нужно знать откуда поступают данные. Он просто спрашивает о них, а сервер GraphQL заботится об остальном.
Поля запроса также могут содержать аргументы. Например, если необходимо отобразить конкретный пост, можно добавить аргумент id к полю post:
query {
post(id: "123foo"){
title
body
author{
name
avatarUrl
profileUrl
}
}
}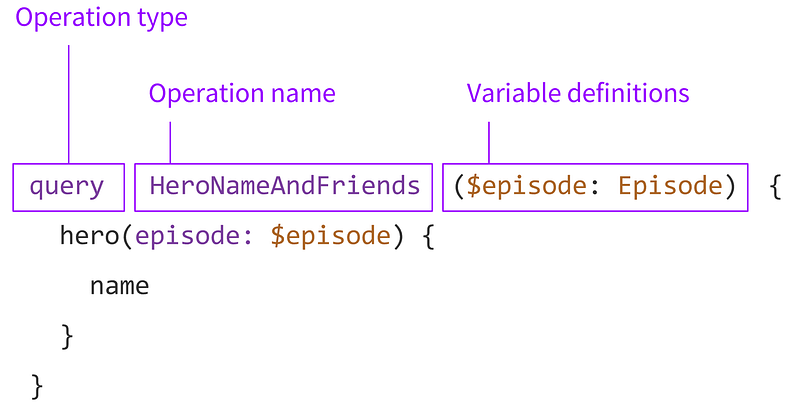
Структура запроса GraphQL
Сервер GraphQL не может знать что делать с входящим запросом, если ему не объяснить при помощи распознавателя (resolver).
Используя распознаватель GraphQL понимает, как и где получить данные, соответствующие запрашиваемому полю. К примеру, распознаватель для поля запись может выглядеть вот так (используя генератор схемы (schema) из набора Apollo GraphQL-Tools):
Query: {
post(root, args) {
return Posts.find({ id: args.id });
}
}Мы помещаем наш распознаватель в раздел Query потому что мы хотим получать запись (post) в корне ответа. Но также мы можем создать распознаватели для подполей, как например для поля author:
Query: {
post(root, args) {
return Posts.find({ id: args.id });
}
},
Post: {
author(post) {
return Users.find({ id: post.authorId})
}
}Ключевое понятие здесь то, что схема запроса GraphQL и структура вашей базы данных никак не связаны. Другими словами, в базе данных может не существовать полей author или commentsCount, но мы можем "симулировать" их благодаря силе распознавателей.
Как было показано выше, можно писать любой код внутри распознавателя. Так что вы можете изменять содержимое базы данных; такие распознаватели называют изменяющими (mutation).
GraphQL поначалу может показаться сложным, потому что это технология, которая затрагивает многие области современной разработки.
Основные преимущества GraphQL:
- это чёткий и ясный API между бэкендом и фронтендом;
- уменьшенные затраты на коммуникации, меньше соединений;
- не надо писать документацию для API;
- не надо придумывать API.
Автор: Анисимов Александр Группа: ИДМ-17-04