optimise dict_from_bytes #289
Comments
That is interesting. I agree, looking at the code there could be some room for improvement in regards of speed. @chrisbeardy you're welcome to tackle on some improvements here 👍 Also we now have WSTRING support in pyads and I just see that it is not supported for structures, yet. I'll open an issue for that. |
|
TLDR
For speedup, I suggest we target these two areas. Improving Tests I conducted these tests on both python 3.6 pyads 3.3.4 and python 3.8 and pyads 3.3.9, both show the same results. I have a relatively quick It is easy to take a quick look the Interestingly using numpy I'm not suggesting we use numpy here as that would seem overkill to add that dependency for just one line. But I will do a PR for using Given that it is already possible to return the ctypes I think trying to optimise this to list case futher using C would likely just make pyads more complex than it needs to be but for use cases of large amounts of data we could add to the documentation a suggestion to use numpy: data_ctype_raw = plc.read_by_name("", c_ubyte * size_of_data, handle=datalog_handle, return_ctypes=True)
data = pyads.dict_from_bytes(np.frombuffer(data_ctype_raw, dtype=np.ubyte).tolist(), DATALOG_STRUCTURE)Now to tackle to the Code Python Code (if you set a breakpoint on the return statement, you can use a debugger to inspect the variables): from ctypes import c_ubyte
import pyads
import time
import numpy as np
def main():
size_of_data = pyads.size_of_structure(DATALOG_STRUCTURE)
size_of_big_data = pyads.size_of_structure(DATALOG_STRUCTURE_BIG)
plc = pyads.Connection(ADS_ADDRESS, ADS_PORT)
plc.open()
datalog_handle = plc.get_handle("MAIN.data")
datalog_big_handle = plc.get_handle("MAIN.dataBig")
data_read_start = time.perf_counter()
data = plc.read_structure_by_name("", DATALOG_STRUCTURE, structure_size=size_of_data, handle=datalog_handle)
data_read_time = time.perf_counter() - data_read_start
plc.write_by_name("MAIN.lastRead", data["currentPointer"], pyads.PLCTYPE_UDINT)
data_read_start = time.perf_counter()
data2 = plc.read_structure_by_name("", DATALOG_STRUCTURE, structure_size=size_of_data, handle=datalog_handle)
data_read_2_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big = plc.read_structure_by_name("", DATALOG_STRUCTURE_BIG, structure_size=size_of_big_data, handle=datalog_big_handle)
data_read_big_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_2 = plc.read_structure_by_name("", DATALOG_STRUCTURE_BIG, structure_size=size_of_big_data, handle=datalog_big_handle)
data_read_big_time_2 = time.perf_counter() - data_read_start
# test with just a read by name and return ctype
data_read_start = time.perf_counter()
data_big_no_to_dict_raw = plc.read_by_name("", c_ubyte * size_of_big_data, handle=datalog_big_handle)
data_read_big_no_to_dict_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_no_to_dict = pyads.dict_from_bytes(data_big_no_to_dict_raw, DATALOG_STRUCTURE_BIG)
data_read_big_to_dict_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_ctype_raw = plc.read_by_name("", c_ubyte * size_of_big_data, handle=datalog_big_handle, return_ctypes=True)
data_read_big_ctype_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_ctype_to_array = [i for i in data_big_ctype_raw]
data_read_big_to_list_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_ctype_to_array = list(data_big_ctype_raw)
data_read_big_to_list_time_2 = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_ctype_to_array = np.frombuffer(data_big_ctype_raw, dtype=np.ubyte).tolist()
data_read_big_to_list_time_3 = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_big_ctype_dict = pyads.dict_from_bytes(data_big_ctype_to_array, DATALOG_STRUCTURE_BIG)
data_read_big_from_list_to_dict_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_ctype_raw = plc.read_by_name("", c_ubyte * size_of_data, handle=datalog_handle, return_ctypes=True)
data_read_ctype_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_ctype_to_array = [i for i in data_ctype_raw]
data_read_to_list_time = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_ctype_to_array = list(data_ctype_raw)
data_read_to_list_time_2 = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_ctype_to_array = np.frombuffer(data_ctype_raw, dtype=np.ubyte).tolist()
data_read_to_list_time_3 = time.perf_counter() - data_read_start
data_read_start = time.perf_counter()
data_ctype_dict = pyads.dict_from_bytes(data_ctype_to_array, DATALOG_STRUCTURE)
data_read_from_list_to_dict_time = time.perf_counter() - data_read_start
plc.release_handle(datalog_handle)
plc.release_handle(datalog_big_handle)
plc.close()
return
ADS_ADDRESS = "169.254.198.195.1.1"
ADS_PORT = 851
DATALOG_LENGTH = 15001
DATALOG_STRUCTURE: pyads.StructureDef = (
("currentPointer", pyads.PLCTYPE_UDINT, 1),
("data1", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data2", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data3", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data4", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data5", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data6", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data7", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data8", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data9", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data10", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data11", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("data12", pyads.PLCTYPE_LREAL, DATALOG_LENGTH),
("cycleCount", pyads.PLCTYPE_UDINT, DATALOG_LENGTH),
("dcTaskTime", pyads.PLCTYPE_STRING, DATALOG_LENGTH),
("lastExecTime", pyads.PLCTYPE_UDINT, DATALOG_LENGTH),
("cycleTimeExceeded", pyads.PLCTYPE_BOOL, DATALOG_LENGTH),
("RTViolation", pyads.PLCTYPE_BOOL, DATALOG_LENGTH),
)
DATALOG_LENGTH_BIG = 60001
DATALOG_STRUCTURE_BIG: pyads.StructureDef = (
("currentPointer", pyads.PLCTYPE_UDINT, 1),
("data1", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data2", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data3", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data4", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data5", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data6", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data7", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data8", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data9", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data10", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data11", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("data12", pyads.PLCTYPE_LREAL, DATALOG_LENGTH_BIG),
("cycleCount", pyads.PLCTYPE_UDINT, DATALOG_LENGTH_BIG),
("dcTaskTime", pyads.PLCTYPE_STRING, DATALOG_LENGTH_BIG),
("lastExecTime", pyads.PLCTYPE_UDINT, DATALOG_LENGTH_BIG),
("cycleTimeExceeded", pyads.PLCTYPE_BOOL, DATALOG_LENGTH_BIG),
("RTViolation", pyads.PLCTYPE_BOOL, DATALOG_LENGTH_BIG),
)
if __name__ == "__main__":
main()PLC Code: Code for only looking at import timeit
import ctypes
import numpy as np
number = 1_000_000 # _000
pylist = list(range(number))
def list_comp():
t = timeit.Timer("data = [i for i in c_array]", globals=globals())
print("[i for i in c_array] : " + str(t.repeat(repeat=5, number=10)))
def to_list():
t = timeit.Timer("data = list(c_array)", globals=globals())
print("list(c_array) : " + str(t.repeat(repeat=5, number=10)))
def using_numpy(dt):
code = f"""\
from_buffer = np.frombuffer(c_array, dtype={dt})
buffer_list = from_buffer.tolist()
"""
t = timeit.Timer(code, globals=globals())
print("np.frombuffer : " + str(t.repeat(repeat=5, number=10)))
print("Int Array")
c_array_type = ctypes.c_int * len(pylist)
c_array = c_array_type(*pylist)
# c_array = (ctypes.c_int * len(pylist))(*pylist)
if type(c_array_type).__name__ == "PyCArrayType":
list_comp()
to_list()
using_numpy("np.int32")
from_buffer = np.frombuffer(c_array, dtype=np.int32)
buffer_list = from_buffer.tolist()
print([i for i in c_array] == list(c_array) == buffer_list)
print("\nBool Array")
c_array = (ctypes.c_bool * len(pylist))(*pylist)
list_comp()
to_list()
print([i for i in c_array] == list(c_array))
print("\nFloat Array")
c_array = (ctypes.c_float * len(pylist))(*pylist)
list_comp()
to_list()
using_numpy("np.float32")
from_buffer = np.frombuffer(c_array, dtype=np.float32)
buffer_list = from_buffer.tolist()
print([i for i in c_array] == list(c_array) == buffer_list)
print("\nChar Array")
pylist = [1] * number
c_array = (ctypes.c_char * len(pylist))(*pylist)
list_comp()
to_list()
print([i for i in c_array] == list(c_array))
print("\nu_byte array - What actually comes into pyads")
c_array = (ctypes.c_ubyte * len(pylist))(*pylist)
list_comp()
to_list()
using_numpy("np.ubyte")
from_buffer = np.frombuffer(c_array, dtype=np.ubyte)
buffer_list = from_buffer.tolist()
print([i for i in c_array] == list(c_array) == buffer_list) |
|
Very interesting that the list() function performs so much better then the list-comprehension. |
|
20% improvement is definetly worth a PR. |
|
@chrisbeardy You already did some optimization with #292. Do you see room for more speed improvement or shall we close the issue? |
|
There is definitely room for improvement here. I have a few ideas but limited time right now. Using struct.unpack better is one. Instead of struck.upacking only one at a time we could do multiple if it's an array etc. That's just one. Also I think there is potential to reorganise to allow unpacking more at a time too. Leave it open for now. |
The current implementation of dict_from_bytes loops over all the items in an array, both of each array in the structure
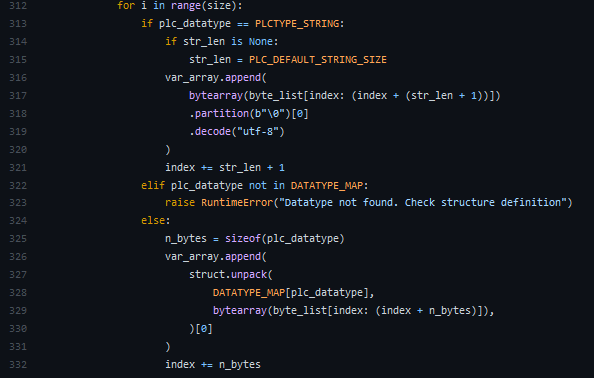
for i in range(size)and of structure if an array of structuresfor structure in range(0, array_size):When reading large arrays this is slow, can this be optimised better use of struct.unpack?
Instead of unpacking one item of the array at a time, can this function be refactored to struct.unpack the whole array at once.
for i in range(size)and changefrom:
to:
I'm also unsure if it is the unpack which is slow too so we could build up an unpack string, then unpack in one go, this would also benefit if
for structure in range(0, array_size)?I've been meaning to tackle this for a while and often when reading large amounts of data I use multiple read_by_names instead as this is actually faster, but you then have to workaround the fact that the data is being read over multiple ADS cycles.
I raise this now as could be thought about when refactoring for #288.
Happy to look at other alternatives too to decrease the time taken to go from bytes to the dictionary, from my testing of large amounts of data, the acatual ADS read of all the bytes is super quick but can take seconds to unpack it into the right format
The text was updated successfully, but these errors were encountered: