- spark_jobs: Spark jobs to ingest data from Kafka and process it in micro batches.
- spark_libs: Spark common libraries for all jobs to process data such as flattening nested json data, .etc
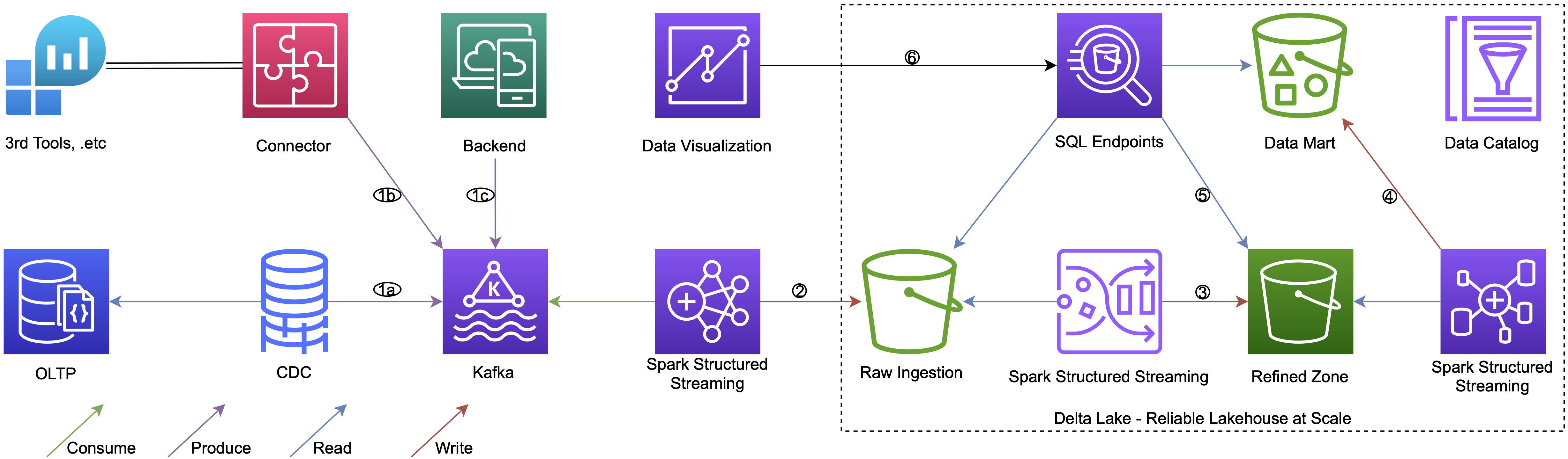
- Regarding to data sources, there can be multiple sources such as:
- OLTP systems logs can be captured and sent to Apache Kafka (1a)
- Third party tools can also be integrated with the Kafka through various connectors (1b)
- And back-end team can produce event data directly to the Kafka (1c)
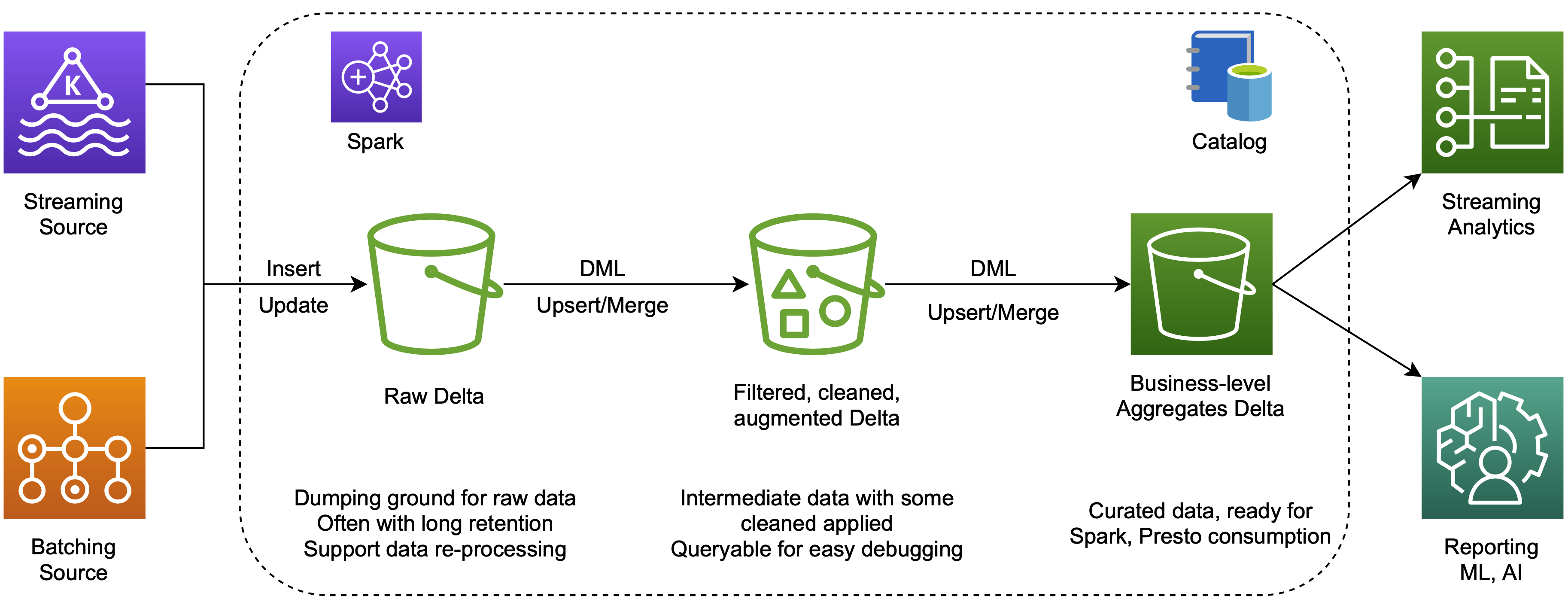
- Once we have the data in the Kafka, we will use Spark Structured Streaming to consume the data and load it into Delta tables in a raw area. Thanks to checkpointing which stores Kafka offsets in this case, we can recover from failures with exactly-once fault-tolerant. We need to enable the Delta Lake CDF feature in these raw tables in order to serve further layers.
- We will use the Spark Structured Streaming again to ingest changes from the raw tables. Then we would do some transformations like flattening and exploding nested data, .etc and load the cleansed data to a next area which is a refined zone. Remember to add the CDF in the refined tables properties.
- Now we are ready to build data mart tables for business level by aggregating or joining tables from the refined area. This step is still in near real-time process because one more time we read the changes from previous layer tables by Spark Structured Streaming.
- All the metadata is stored in the Databricks Data Catalog and all above tables can be queried in Databricks SQL Analytics, where we can create SQL endpoints and use a SQL editor. Beside the default catalog, we can use an open source Amundsen for the metadata discovery.
- Eventually we can build some data visualizations from Databricks SQL Analytics Dashboards (formerly Redash) or use BI tools like Power BI, Streamlit, .etc.