-
CUDA 対応 CUDA が動かない環境では CPU 実行
-
TTS, VTS, HuBERT-VITS, W2V2-VITS に対応
-
marine でのアクセント補正追加
windows 10
ブラウザは chrome でしか動作確認してません
画面右の Releases から WebApp_MoeGoe.zip ダウンロード
2.3 GB になったので github に上げれなくなりました
GoogleDrive からWebApp_MoeGoe_CUDA_0.9.0.zip ダウンロード
https://drive.google.com/file/d/10-nLQEchqgoScmJQrts3XaYv5LX7HRIA/view?usp=sharing
パスに日本語が含まれないフォルダで解凍
ファイル数が多いので時間がかかります、解凍後サイズは 4.3GB ぐらい。torch がでかくて削れません。
モデルデータ( .pth )と設定ファイル( .json )を1セットで好きな名前のフォルダに入れて
models フォルダに入れる
例
./models/AAAAA/model.pth と config.json
./models/BBBBB/model.pth と config.json
./models/CCCCC/model.pth と config.json
HuBERT-VITS 推論用データダウンロード ( 360 MB )
https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt
これが無いと HuBERT 対応のモデルデータが使えません。
models の HuBERT フォルダに入れる
./models/HuBERT/hubert-soft-0d54a1f4.pt
自分で感情設定ファイルを作りたい人は下記のデータも必要です
音声生成のみならこのデータは不要ですので、後からでも大丈夫です
W2V2-VITS 推論用データダウンロード ( 582 MB たまにサイトがかなり重いです )
https://zenodo.org/record/6221127/files/w2v2-L-robust-12.6bc4a7fd-1.1.0.zip?download=1
これが無いと W2V2 対応のモデルデータが使えません。
解凍してできた model.onnx と model.yaml を
models の W2V2 フォルダに入れる
./models/W2V2/model.onnx
./models/W2V2/model.yaml
WebApp_MoeGoe.exe 実行
コンソールに
2 0 2 2 - 1 1 - 1 7 1 6 : 1 3 : 0 9 . 3 5 7 6 0 1 9 [ W : o n n x r u n t i m e : D e f a u l t , o n n x r u n t i m e _ p y b i n d _ s t a t e . c c : 1 6 4 1 o n n x r u n t i m e : : p y t h o n : : C r e a t e I n f e r e n c e P y b i n d S t a t e M o d u l e ] I n i t p r o v i d e r b r i d g e f a i l e d .
Running on :cuda:0
* Serving Flask app 'WebApp_MoeGoe'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:15000
Press CTRL+C to quit
が出れば起動成功
※ WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
この赤字メッセージは使ってるフレームワーク Flask のデフォルトメッセージです
Running on :cuda:0 が出てれば CUDA で実行できてます。
chrome で http://127.0.0.1:15000 にアクセス
このリポジトリにモデルデータは含まれていません
リンク先の利用規約を読んだ上、ダウンロードしてください
CjangCjengh/TTSModels
https://github.com/CjangCjengh/TTSModels
-
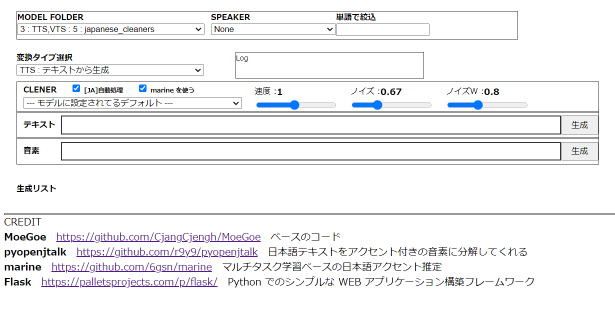
モデルデータを入れたフォルダを選択、次にスピーカーを選んで生成を押してください
-
感情ファイル
自作 npy ファイルは
./models/W2V2/npy/ フォルダの中へ
ファイル名が表示名になります
複数の npy を一つにまとめたタイプの npy には未対応です -
自分で感情ファイルを作りたい場合は
上記の W2V2 データ入れた後に
http://127.0.0.1:15000/createNpy にアクセス
雑な作りですけど、元にしたい音声ファイルドラッグアンドドロップで
./models/W2V2/npy/ファイル名.npy
が作られます
下の思わせぶりな枠の中には結果も何も表示されません
邪魔な .npy ファイルはそのまま削除して構いません
メインページリロードで反映
-
設定項目の CLENER
CLENER は入力文字列を音素表現の文字列に変換する物です
これの種類によって [JA] が必要になったりします -
[JA]自動処理
チェックしておけば必要な CLENER の時は内部で勝手に [JA] で囲みます
もし日本語以外を喋らせたいときは、チェックを外して
自分で各言語のラベルをテキストに入力してください
モデルデータや CLENER によっては元々多言語対応していません
例
[ZH]你好。[ZH] -
marine を使う
日本語変換時のアクセントを補正
詳細は
marine (https://github.com/6gsn/marine) -
その他
エラーチェックが甘いので
なんかエラー出たら、サーバー再起動、ブラウザ再読み込みしてください