An article is an introduction to Microsoft SQL Server's plan optimizer & common operators, and provide an more in-depth view & analysis of slow queries (with example)
Link: https://tcd93.github.io/MSSQL-execution-plan/
Disclaimer: as MSSQL is a closed-source database, I can not prove that this article is 100% correct, all is based on articles online (which I'll include links) and my own experience, so take it with a grain of salt & happy reading!
Note: I don't provide sample data here as it's private & pretty huge, but even if you don't run these data yourself, you should have a pretty good grasp of SQL Server's optimizer after reading this
Tool: Microsoft SQL Server Management Tool (MSSM)

An execution plan is a set of physical operations (operators) that can be performed to produce the required result
The data flow order is from right to left, the thickness of the arrow indicate the amount of data compared to the entire plan; hovering on the icons show extra details

Retrieving the estimated plan is just telling SQL Server to return the execution plan without actually executing it, helpful in debugging
From MSSM (Microsoft SQL Server Management tool), select an SQL block:
- Press
CTRL + L - or: Right click → Display estimated execution plan
- or Query → Display estimated execution plan
In the query menu, tick the “Include Actual Execution Plan” icon

Select & run the query, the plan will be open on a new tab next to result tab
They can differ in cases where the query involves parallelism, variable, hints, current CPU usage… Actual execution plan contains extra runtime information, such as the actual usage metrics (memory grant, actual rows, executions…), and any runtime warnings
 Estimated
vs
Estimated
vs
 Actual
Actual
Actual Plan also include the number of rows processed by each thread, runtime memory allocation...


What happens when a query is submitted?

The algebrizer resolves all the names of various objects, tables, and columns referred to within the query string. It identifies at the individual column level, all the data types (varchar, datetime…) for the objects being accessed. It also determines the location of aggregates (SUM, MAX…)
The algebrizer outputs a binary tree which gives the optimizer knowledge of the logical query structure and the underlying tables and indexes, the output also includes a hash representing the query, the optimizer uses it to see if there is already a plan for this stored in plan cache & whether it’s still valid, if there’s one, then the process stops and the cached plan is reused, if not, then it'll compile out an execution plan based on statistics & cost
Once the query is optimized, the generated execution plan may be stored in the plan cache and be executed step-by-step by the physical operators in that plan
The estimated cost is based on a complex mathematical model, and it considers various factors, such as cardinality, row size, expected memory usage and number of sequential and random I/O operations, parallelism overhead…
This number is meaningless outside of the query optimizer's context and should be used for comparison only

- Operator Cost: Cost taken by the operator
- Subtree Cost: Cumulative cost associated with the whole subtree up to the node
The query optimizer finds a number of candidate execution plans for a given query, estimates the cost of each of these plans and selects the plan with the lowest cost.
For some queries, the optimizer cannot consider every possible plan for every query, it actually has to consider both the cost of finding potential plans and the costs of plans themselves


Whenever a query is run for the first time in SQL Server, it is compiled and a query plan is generated for the query. Every query requires a query plan before it is actually executed. This query plan is stored in SQL Server query plan cache, when that query is run again, SQL Server doesn’t need to create another query plan
The duration that a query plan stays in the plan cache depends upon how often a query is executed. Query plans that are used more often, stay in the query plan cache for longer durations, and vice-versa
Cache is not used when specific hints are specified (RECOMPILE hint)
Why is it important?
- The statistics contain information about tables and indexes such as number of rows, the histogram, the density of values from a sample of data; these values are stored in system tables
- Costs are generated based on statistics, if the stats are incorrect or out-of-date (stale), cost will be wrongly calculated, and the optimizer may choose a sub-optimal plan
- Statistics can be updated automatically, periodically, or manually
Histogram measures the frequency of occurrence for each distinct value in a data set
To create the histogram, SQL server split the data into different buckets (called steps) based on the value of first column of the index. Each record in the output is called as bucket or step
The maximum number of bucket is 200, this can cause problems for larger set of data, where there can be points of skewed data distributions, leading to un-optimized plans for special ranges
For example, customer A usually makes 5 purchases per week, but suddenly, at a special day (like Black Friday), he made over 10000 transactions, that huge spike might not get captured in the transaction bucket, and the query for that week would likely get much slower than normal as the
optimizer'd still think he makes very little purchases in that week
In MSSM, expand Table > Statistics > Double click a stat name; some stat names are auto-generated, some are user-defined

This is a sample histogram of column MasterID from Customer table:

Explanation for the 4th bucket:
RANGE_ROWS: There are 2861 rows with keys from 4183 - 62833EQ_ROWS: There are 272 rows with key 62834DISTINCT_RANGE_ROWS: There are 47 distinct rows with keys from 4183 - 62833
Now if we selects 30% of the 4th bucket (21778 = (62833 - 4183) * 0.3 + 4183):
SELECT * FROM Customer WHERE MasterID BETWEEN 4183 AND 21778This is the generated plan:

There are 2861 rows from ID 4183 - 62833, so if we’re selecting 30% of that range, it should also results in 30% of 2861 which is 858 rows, that’s the estimated number of the optimizer
Density is the ratio of unique values with in the given column or a set of columns

Let's go with this query:
DECLARE @N INT = 4178
SELECT * FROM Customer WHERE MasterID = @N
Histogram cannot be used when we're using parameter, it then falls back to Density, which is estimated as Total rows * Density = 1357786 * 2.020488E-05 = 27.43 rows - but in actuality there is 2134 rows! (as showed in Histogram EQ_ROWS attribute). Optimizer failed pretty hard there 🤔
- Memory Grant value (kb) can only be seen in Actual execution mode
- This memory is used to store temporary rows for sort, hash join & parallelism exchange operators
- SQL Server calculates this based on statistics, lack of available memory grant causes a
tempdbspill (tempDB is a global resource that is used to stores all temporary objects)
In SQL server 2012+, a yellow warning icon is displayed in plan explorer when the processor detects a spill (not enough RAM to store data)
For SQL server 2008R2, check the “sort warnings” event in SQL profiler to detect memory spill
By adding a “order by” clause to the above example, we can produce a sort warnings event in SQL Profiler


The engine only granted 1136 KB of memory buffer to perform sorting, but in reality the operation needed way more because actual rows are much higher than estimated returned rows, so the input data has to be split into smaller chunks in tempDB to accommodate the granted space to be sorted, then extra passes are performed to merge these sorted chunks
To fix this, we can simply add the RECOMPILE hint to the query, this forces the parse to replace the @N parameter with actual value, therefore correctly using the Histogram table
Index is a set of ordered values stored in 8kb pages, the pages form a B+tree structure, and the value contains pointer to the pages in the next level of the tree
The pages at the leaf nodes can be data pages (clustered index) or index pages (non-clustered index)
Clustered index (CI) is the table itself, 1 table can only have 1 CI; NonCI’s leaf may refer to the CI’s key, so any changes to the CI’s key will force changes to every NonCI’s structures

With scan, we need to scan 6 pages to reach key 28, whereas going top-down (seek), we just need to read 2 index pages and 1 data page (3 logical/physical reads = 3 * 8kb = 24kb)
Seek & scan can be combined, where a seek happens first to find where to start scanning, this is still displayed as an index seek operator in plan view
| Icon | Name | Description |
|---|---|---|
 |
Sort | Reads all input rows, sorts them, and then returns them in the specified order |
Sort is a blocking operation, it has to read all data into RAM, and sort it. It is both time & memory consuming
If the data is too big for granted memory, a spill happens, making Sort less efficient
| Icon | Name | Description |
|---|---|---|
 |
Index seek / Non-clustered index seek | Finds a specific row in an index, based on key value; and optionally continues to scan from there in logical (index) order |
 |
Index scan / Non-clustered index scan | Reads all data from an index, either in allocation order or in logical (index) order |
 |
Key lookup | Reads a single row from a clustered index, based on a key that was retrieved from a non-clustered index on the same table. A Key lookup is a very expensive operation because it performs random I/O into the clustered index. For every row of the non-clustered index, SQL Server has to go to the Clustered Index to read their data. We can take advantage of knowing this to improve the query performance |
 |
Table scan | Reads all data from a heap table, in allocation order |
| Icon | Name | Description |
|---|---|---|
 |
Hash match/aggregate | Builds a hash table from its first input, then uses that hash table to either join to its second input, or produce aggregated values |
 |
Joins two inputs that are ordered by the join key(s), exploiting the known sort order for optimal processing efficiency | |
 |
Stream aggregate | Computes aggregation results by reading a sorted input stream and returning a single row for each set of rows with the same key value |
 |
Nested loop | Joins two inputs by repeatedly executing the second input for each row in the first input |
| Icon | Name | Description |
|---|---|---|
 |
Distribute streams | The parallelism operators, also known as exchange operators, manage the distribution of rows between threads in parallel plans |
 |
Repartition streams | |
 |
Gather streams |
| Icon | Name | Description |
|---|---|---|
 |
Table spool | Stores its input rows in an internal worktable; this worktable can then be used to re-process the same data |
 |
Index spool | Stores its input rows in an internal, indexed worktable; this indexed worktable can then be used to re-process specific subsets of the data |
- O(n.m) / O(nlog(m))*
- Require data sorted: No
- CPU cost: Low
- Memory grant: Maybe
- Spill-able?: No
- Blocking: No / Semi**
-
Optimal for:
- Small outer input → Small/Medium (indexed) inner input
- Low cardinality data
- OLTP
 this gif demonstrates “brute-force” type of NL
this gif demonstrates “brute-force” type of NL
(*) SQL Server can use multiple ways to optimize a nested loop (to get Big O of nlog(m) time complexity)
- Spool in inner loop to maximize reusability
- Perform index seek on inner loop
- Prefetch data in inner loop
(**) Order inner loop implicitly to create Semi-blocking nested loop
Example plan:

Scans IX_agent index, for each agent, seek the corresponding customer asynchronously from IX_custid, forward the result whenever it's available
When
WithUnorderedPrefetchis set to False, the index-seek-result result will be forwarded only when the previous ordered key is fetched & forwarded
Example plan:


- Scans
IX_tnx_typeindex - May implicitly perform an (partial) "order by" to create less random seeks; hence the high memory usage
- If memory does not fit, it’ll fill what it can, so it does not spill
- Although getting just 10 rows, the above plan still requires 189,312 KB of sorting space
- Concurrent runs of above query cause high RESOURCE_SEMAPHORE wait, leading to slower performance (fixed in 2016)
- The sort method & memory grant algorithm is different to a normal sort operator, there’s no guarantee that it is faster than same query without optimization
- This is treated as a “safety net” in case the statistics are out-of-date
- O(n + m)
- Require data sorted: No
- CPU cost: High
- Memory grant: Yes
- Spill-able?: Yes
- Blocking: Yes
-
Optimal for:
- Medium build input → Medium/Large probe input
- Medium/high cardinality data
- Scales well with parallelism
- O(n + m)
- Require data sorted: Yes
- CPU cost: Low
- Memory grant: No
- Spill-able?: No
- Blocking: No
-
Optimal for:
- Evenly sized inputs
- One to many
- Scales badly parallelism
This is the explain plan produced from the following query:
SELECT [product].id, [tnx_table].amount...
FROM tnx_table
INNER JOIN product
ON [tnx_table].prod_id = [product].id
First, the engine scans the IX_prod index, in parallel, the distribution of rows among threads can be considered as “random”; each time the query runs, each thread will handle different number of rows

After scanning, SQL Server repartitions the rows in each thread, arranging them in a deterministic order, rows are now distributed “correctly” among threads; each time the query runs, each thread will handle same number of rows
This operator requires some buffer space to do the sorting
Next, it'll allocate some space to create a bloom filter (bitmap)

When the second index scan starts, it also include a probe action that checks on the bitmap net. If the bit is “0”, that means the key does not exists in the first index, if the bit is “1”, that means the key may exists in the first index and can pass through into repartition streams

With bitmap, the actual number of rows after the scan is reduced
With the two sources ready & optimized, the Hash join operation can be done quickly in parallel and finally merged together
Here's a summary chart (note that mod % 2 & mod % 10 are not actual MS hash function implementation):

In this example, values in thread 1 & 2 pass through the bloom filter (with hash function mod % 10) and only 7 bits is turned on, when thread 3 & 4 come and look up on the bitmask, any value which divided by 10 returns a remainder of 1, 6 or 9 would get filtered, these are the false negative matches. The rest, continue on and be filtered again by the hash match function, with much less need for memory
Types of scan:
Unordered scan (Allocation Order Scan) using using internal page allocation information
- Favorable for Hash match
Ordered scan, the engine will scan the index structure
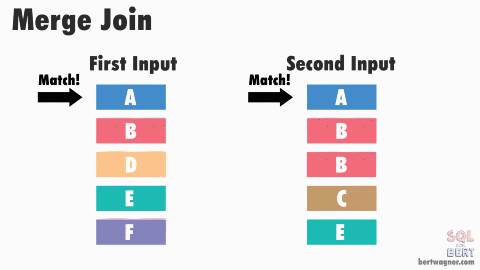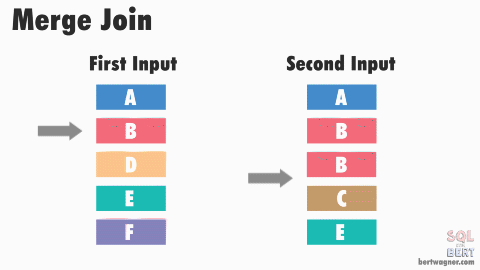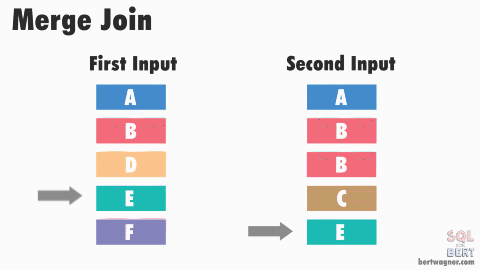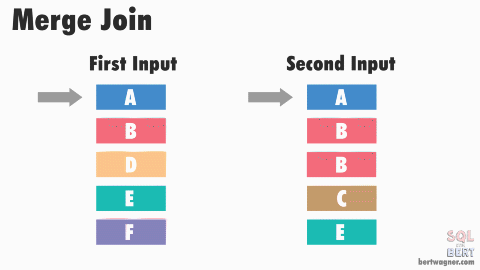
- Favorable for Merge join
- During order-preserving re-partition exchange, it does not do any sorting, it just keep the order of output stream the same as the input stream
This is a side-by-side comparation of a merge join & hash join, both produce same set of records
The query is simple:
--hash
select f.custid, d.Week, sum(f.Amount)
from Fact f
inner join DimDate d
on f.RptDate = d.PK_Date
-- where d.PK_Date >= '2020-01-01' (uncomment to get merge join plan)
group by f.custid, d.WeekMerge join plan is evaluated by adding a where clause filter by date, the optimizer will now go for index seek in the DimDate table, but 2020-01-01 is way lower than the actual data range in Fact table, so both queries produce same result
 Merge
vs
Merge
vs
 Hash
Hash
Since the index seek generate an ordered result set, optimizer tries to make use of an merge join plan, but data from Fact table's clustered index scan are not yet ordered, the engine must do it implicitly in the ordered repartition streams operator, thus giving very high cost compared to the hash join one
We can keep track of these symptoms by monitoring the CXPACKET & SLEEP_TASK wait types (for SQL Server 2008)
Where the fun begins
In normal circumstances, both queries' performance is very similar (around 5s for 200k records)
Now, put the system CPU under load (by running many queries at same time using SQL Stress Test), the merge join becomes slower the more threads used, whereas hash join's performance is very consistent (when CPU at 90% load, merge took 13s)
 Merge
vs
Merge
vs
 Hash
Hash
Why?
In merge, the order-preserving exchange operator has to run sequentially to get pages from the scan, so at this point it is actually running in single thread mode, and when the CPU is under pressure, it’ll have to wait up to 4ms (a quantum, see SQLOS) to get the next batch of pages
In hash, at no point the execution is done synchronously, parallel execution is used at 100% power, so it is very effective
SQLOS
We've only touched the surface of SQLOS - a operating system sitting between SQL Server & real OS to manage services such as thread, memory. There's a lot of interesting thing going on behind the scene, I'll write up another article for this at another time
Consider the SQL:
--get all "above-average" transactions by products
select prod_id, tran_date, amount, avg_amount
from (
select prod_id, custid, tran_date, amount,
avg(amount) over (partition by prod_id) avg_amount
from tnx_table
where tran_date between ... and ...
) i
where stake >= avg_stake
order by prod_idoption (maxdop 1)), execution time drops to 1 second

This is the last part of the plan

In this example, lots of exchange spill events are caught
An exchange spill is like a tempdb spill, it is a buffer overflow event that happens inside of a thread
Here's a visualized version of the above plan:

Because of the uneven distribution of data in threads (skewed data), the ones that have more rows (1 & 4) are more likely to wait for thread 2 & 3 to keep returned rows in order, while piling up their internal buffer, eventually leading to a spill
To fix this, we need to eliminate the skewness by splitting up data into two parts:
with [avg] as (
select prod_id, avg(amount) amount, min(tran_date) min_tdate, max(tran_date) max_tdate
from tnx_table
where tran_date between ... and ...
group by prod_id
)
select a.prod_id, a.tran_date, a.amount, [avg].amount avg_amount
from tnx_table a
inner join [avg]
on a.amount >= [avg].amount
and a.prod_id = [avg].prod_id
and a.tran_date between [avg].min_tdate and [avg].max_tdate
order by prod_idNow it executes instantly:

Keep in mind that exchange spill can happen with any blocking operator:


Distribute rows from a single-threaded operation across multiple threads
Common types:
- Hash (for Hash join)
- Round-Robin (for Nested Loop join)
- Broadcast (for small set of input)
A spool is created when the optimizer thinks that data reuse is important (prevent multiple seeks or scans on same index/heap)
There are two types of spool: lazy & eager
-
Eager Spool catches all the rows received from another operator (ex: Index scan, concatenation...) and store these rows in TempDB (blocking)
-
Lazy Spool is similar to eager spool, but it only reads and stores the rows in a temporary table only when the parent operator actually asks for a row (non-blocking)
Lazy Spool
We're using the previous plan example of gather streams, without parallelism

We’ll see that there are 3 lazy spool operators, but it is actually just one instance (by hovering on it, they have the same primary node id)
The data flow goes as below:
- The operator scan the transaction table to continuously retrieve all data
- Once a segment got all records of a same customer, it copies all rows into a table spool, those rows are then used as the outer input of a nested loop (1)
- For each loop (1), it scan the entire spool, calculate the average transaction amount of that customer (aggregate), the result is a single row that get passed as outer input into another nested loop (2)
- The processor scan the spool again, row-by-row to compare with the number from step 3, returning rows that are less than that number
- When the index scan is done for another batch of customer rows, the spool is truncated and refill with new data, repeat until all customers are done

The number of customers in the transaction table is 19758
The spool is rebound 19759 times meaning it got truncated & repopulated 19758 times for each customer + 1 time on the first creation
Eager Spool
QUERY: Add 100 to all MasterIDs in the customer table

Due to MasterID being key in a non-clustered index (IX_master), updating it will physically change it’s location (move towards the right end of the b-tree), if the scan operation is from left to right, then the updated row might be reread & updated again
The eager spool is created to temporary store old rows, making sure that each row is read only once