"The regex-centric, fast and flexible lexical analyzer generator for C++"
Flex reimagined. Fast, flexible, adds Boost 💪
RE/flex is faster than Flex while providing a wealth of new features. RE/flex is also much faster than regex libraries such as Boost.Regex, C++11 std::regex, PCRE2 and RE2. For example, tokenizing a representative C source code file into 244 tokens takes only 13 microseconds:
| Command / Function | Software | Time (μs) |
|---|---|---|
| reflex --fast | RE/flex | 13 |
| flex -+ --full | Flex | 17 |
| reflex --full | RE/flex | 29 |
| boost::spirit::lex::lexertl::actor_lexer::iterator_type | Boost.Spirit.Lex | 40 |
| reflex -m=boost-perl | Boost.Regex | 230 |
| pcre2_match() | PCRE2 (pre-compiled) | 318 |
| reflex -m=boost | Boost.Regex POSIX mode | 450 |
| flex -+ | Flex | 3968 |
| RE2::Consume() | RE2 (pre-compiled) | 5088 |
| RE2::Consume() | RE2 POSIX mode (pre-compiled) | 5420 |
| std::cregex_iterator() | C++11 std::regex | 14784 |
Note: Best times of 10 tests with average time in microseconds over 100 runs (using clang 8.0.0 with -O2, 2.9 GHz Intel Core i7, 16 GB 2133 MHz LPDDR3).
- Compatible with Flex to eliminate a learning curve, making a transition to RE/flex frustration-free.
- Includes many examples, such as a tokenizer for C/C++ code, a tokenizer for Python code, a tokenizer for Java code, and more.
- Works with Bison and supports reentrant, bison-bridge, bison-locations and
Bison 3.0 C++ interface
%skeleton "lalr1.cc". - Extensive documentation in the online User Guide.
- Adds Unicode support with Unicode property matching
\p{C}and C++11, Java, C#, and Python Unicode properties for identifier name matching. - Adds indent/nodent/dedent anchors to match text with indentation, including
\t(tab) adjustments. - Adds lazy quantifiers to the POSIX regular expression syntax, so hacks are no longer needed to work around greedy repetitions in Flex.
- Adds word boundary anchors to the POSIX regular expression syntax.
- Adds an extensible hierarchy of pattern matcher engines, with a choice of regex engines, including the RE/flex regex engine and Boost.Regex.
- Adds freespace mode option to improve readability of lexer specifications.
- Adds
%classand%initto customize the generated Lexer classes. - Adds
%includeto modularize lexer specifications. - Generates clean source code that defines an MT-safe (reentrant) C++ Lexer class derived from an abstract lexer class template, parameterized by matcher class type.
- Multiple lexer classes can be combined and used in one application.
- Configurable Lexer class generation to customize the interface for various parsers, including Yacc and Bison.
- Generates scanners for lexical analysis on files, C++ streams, and (wide) strings, with automatic fast conversion of UTF-16/32 to UTF-8 for matching Unicode on UTF-encoded input files.
- Generates lex.yy.cpp files while Flex generates lex.yy.cc files (in C++ mode with flex option -+), to distinguish the generated files.
- Generates Graphviz files to visualize FSMs with the Graphviz dot tool.
- Conversion of regex expressions, for regex engines that lack regex features.
- The RE/flex regex library makes C++11 std::regex and Boost.Regex much easier to use in plain C++ code for pattern matching on (wide) strings, files, and streams.
The RE/flex repo includes tokenizers for Java, Python, and C/C++.
This is a forked version of RE-Flex from Genivia/RE-flex that strives to be use a fully GNU Autotool-compliant build system while adding additional features and code cleanup. Major changes and features from the original version will be incorporated if possible.
Before you start, it is important to understand there are two sets of dependancies decided by where you obtained the source code. If you cloned the source directly from a git repository, you will need to have installed maintainers tools in addition to the main project dependancies. This is generally true for many projects using the Autotool build system as it separates dependancies needed to maintain the package from dependancies needed to use the package. These maintainer dependancies are:
If you obtained RE-Flex from a distribution tarball (you downloaded the file reflex-X.Y.Z.tar.gz from somewhere, you only need a recent C++ compiler. If this is the case, skip to Building from a distribution otherwise continue on to Cloning from a git repository below.
Running the examples require the following:
First, clone the repository into a convenient location
$ git clone https://github.com/tegtmeye/RE-flex.git
Navigate into the newly cloned repository on your local machine and bootstrap the autotool build process by running autoreconf -fi.
$ cd RE-flex
$ autoreconf -fi
Skip to the Building and installing step below.
If you download the distribution tarball corresponding to the current release, it will be named something similar to reflex-X.Y.Z.tar.gz. Unpack the tarball by issuing the following:
$ tar zxf reflex-X.Y.Z.tar.gz
This will result in a new directory named reflex-X.Y.Z. Navigate into the directory and then continue on to Building and installing below.
$ cd reflex-X.Y.Z.tar.gz
At this point, there will be a script named configure that analyses your environment and prepares the build. This configure script accepts configuration and installation options. To view these options, run:
$ ./configure --help
A common configure option is to set the installation location. If missing, the installation location defaults to /usr/local
$ ./configure --prefix=/path/to/install/location
Next, run configure with the appropriate optons included (here represented by [OPTIONS])
$ ./configure [OPTIONS]
The configure script will run many tests printing a summary of the results. If it cannot detect a required tool or compiler feature, the configure script will exit with an error message. If configuration is successful, build the reflex package by issuing the make command. The build system supports parallelized builds by including the -j option (as in make -j).
$ make
After this successfully completes, you can optionally check the build by issuing:
$ make check
Which runs several tests located in the tests directory along with building and running the contents of examples.
Finally install reflex by running:
$ make install
You may need to install with elevated privileges depending on the installation location--for example if installing in the default location /usr/local.
$ sudo make install
This installs reflex according to standard GNU directory layout where the reflex executable is installed in $(prefix)/bin, the library is installed in $(prefix)/lib, header files are installed in $(prefix)/include and documentation including examples are installed in $(prefix)/share.
Detailed information on building and installing is available in the INSTALL file.
These libraries and packages are only required if you need the functionality in your project. The RE/Flex installation does not depend on them.
-
To use Boost.Regex as a regex engine with the RE/flex library and scanner generator, install Boost and link your code against the boost regex library.
-
To visualize the FSM graphs generated with the reflex option
--graphs-file, install Graphviz dot.
This version of RE/flex currently does not support building on Windows. The original version provided build instructions and an actual distributed Windows executable. Unfortunately, the details of the build, including which versions of Windows was supported, and testing of this executable was not included. Therefore, Windows-specific support and the included executable have been removed.
Contributions of a complete and transparent Windows build are welcome.
The unsupported instructions provided by the original RE/flex are as follows.
Use
reflex/bin/reflex.exefrom the command line or add a Custom Build Step in MSVC++ as follows:
select the project name in Solution Explorer then Property Pages from the View menu (see also custom-build steps in Visual Studio);
add an extra path to the
reflex/includefolder in the Include Directories under VC++ Directories, which should look like$(VC_IncludePath);$(WindowsSDK_IncludePath);C:\Users\YourUserName\Documents\reflex\include(this assumes thereflexsource package is in your Documents folder).enter
"C:\Users\YourUserName\Documents\reflex\bin\reflex.exe" --header-file "C:\Users\YourUserName\Documents\mylexer.l"in the Command Line property under Custom Build Step (this assumesmylexer.lis in your Documents folder);enter
lex.yy.h lex.yy.cppin the Outputs property;specify Execute Before as
PreBuildEvent.If you are using specific reflex options such as
--flexthen add these in step 3.Before compiling your program with MSVC++, drag the folders
reflex/libandreflex/unicodeto the Source Files in the Solution Explorer panel of your project. Next, runreflex.exesimply by compiling your project (which may fail, but that is OK for now as long as we executed the custom build step to runreflex.exe). Drag the generatedlex.yy.handlex.yy.cppfiles to the Source Files. Now you are all set!In addition, the
reflex/vsdirectory contains batch scripts to build projects with MS Visual Studio C++.
There are two ways you can use this project:
- as a scanner generator for C++, similar to Flex;
- as an extensible regex matching library for C++.
For the first option, simply build the reflex tool and run it on the command line on a lexer specification:
$ reflex --flex --bison --graphs-file lexspec.l
This generates a scanner for Bison from the lexer specification lexspec.l and
saves the finite state machine (FSM) as a Graphviz .gv file that can be
visualized with the Graphviz dot tool:
$ dot -Tpdf reflex.INITIAL.gv > reflex.INITIAL.pdf
$ open reflex.INITIAL.pdf
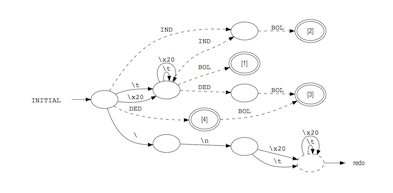
Included in the installation are several examples designed to illustrate the features of RE/flex. They are located in $(prefix)/share/doc/reflex/examples/. To quickly get started, simply copy this directory to a convenient, writable location (your home directory for example) and run make.
$ cp -r /path/to/share/doc/reflex/examples $HOME/.
$ cd examples
$ make
The example directory includes a minimalist makefile that reflects the appropriate build settings at the time of RE/flex's installation. This will work for 90% of users. If however you have a non-standard installation, you may need to adjust the build rules at the top of the makefile.
Run the reflex --help to see a full list of command-line options.
For the second option, simply use the new RE/flex matcher classes to start pattern matching on strings, wide strings, files, and streams.
You can select matchers that are based on different regex engines:
- RE/flex regex:
#include <reflex/matcher.h>and usereflex::Matcher; - Boost.Regex:
#include <reflex/boostmatcher.h>and usereflex::BoostMatcherorreflex::BoostPosixMatcher; - C++11 std::regex:
#include <reflex/stdmatcher.h>and usereflex::StdMatcherorreflex::StdPosixMatcher.
Each matcher may differ in regex syntax features (see the full documentation), but they have the same methods and iterators:
matches()returns nonzero if the input matches the specified pattern;find()search input and returns nonzero if a match was found;scan()scan input and returns nonzero if input at current position matches;split()returns nonzero for a split of the input at the next match;find.begin()...find.end()filter iterator;scan.begin()...scan.end()tokenizer iterator;split.begin()...split.end()splitter iterator.
For example:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to check if the birthdate string is a valid date
if (reflex::BoostMatcher("\\d{4}-\\d{2}-\\d{2}", birthdate).matches() != 0)
std::cout << "Valid date!" << std::endl;
With a group capture to fetch the year:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to check if the birthdate string is a valid date
reflex::BoostMatcher matcher("(\\d{4})-\\d{2}-\\d{2}", birthdate);
if (matcher.matches() != 0)
std::cout << std::string(matcher[1].first, matcher[1].second) << " was a good year!" << std::endl;
To search a string for words \w+:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search for words in a sentence
reflex::BoostMatcher matcher("\\w+", "How now brown cow.");
while (matcher.find() != 0)
std::cout << "Found " << matcher.text() << std::endl;
The split method is roughly the inverse of the find method and returns text
located between matches. For example using non-word matching \W+:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search for words in a sentence
reflex::BoostMatcher matcher("\\W+", "How now brown cow.");
while (matcher.split())
std::cout << "Found " << matcher.text() << std::endl;
To pattern match the content of a file that may use UTF-8, 16, or 32 encodings:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search and display words from a FILE
FILE *fd = fopen("somefile.txt", "r");
if (fd == NULL)
exit(EXIT_FAILURE);
reflex::BoostMatcher matcher("\\w+", fd);
while (matcher.find())
std::cout << "Found " << matcher.text() << std::endl;
fclose(fd);
Same again, but this time with a C++ input stream:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
// use a BoostMatcher to search and display words from a stream
std::ifstream file("somefile.txt", std::ifstream::in);
reflex::BoostMatcher matcher("\\w+", file);
while (matcher.find())
std::cout << "Found " << matcher.text() << std::endl;
file.close();
Stuffing the search results into a container using RE/flex iterators:
#include <reflex/boostmatcher.h> // reflex::BoostMatcher, reflex::Input, boost::regex
#include <vector> // std::vector
// use a BoostMatcher to convert words of a sentence into a string vector
reflex::BoostMatcher matcher("\\w+", "How now brown cow.");
std::vector<std::string> words(matcher.find.begin(), matcher.find.end());
Use C++11 range-based loops with RE/flex iterators:
#include <reflex/stdmatcher.h> // reflex::StdMatcher, reflex::Input, std::regex
// use a StdMatcher with std::regex to to search for words in a sentence
for (auto& match : reflex::StdMatcher("\\w+", "How now brown cow.").find)
std::cout << "Found " << match.text() << std::endl;
RE/flex also allows you to convert expressive regex syntax forms such as \p
Unicode classes, character class set operations such as [a-z--[aeiou]],
escapes such as \X, and (?x) mode modifiers, to a regex string that the
underlying regex library understands and will be able to use:
std::string reflex::Matcher::convert(const std::string& regex, reflex::convert_flag_type flags)std::string reflex::BoostMatcher::convert(const std::string& regex, reflex::convert_flag_type flags)std::string reflex::StdMatcher::convert(const std::string& regex, reflex::convert_flag_type flags)
For example:
#include <reflex/matcher.h> // reflex::Matcher, reflex::Input, reflex::Pattern
// use a Matcher to check if sentence is in Greek:
static const reflex::Pattern pattern(reflex::Matcher::convert("[\\p{Greek}\\p{Zs}\\pP]+", reflex::convert_flag::unicode));
if (reflex::Matcher(pattern, sentence).matches() != 0)
std::cout << "This is Greek" << std::endl;
We use convert with optional flag reflex::convert_flag::unicode to make .
(dot), \w, \s and so on match Unicode and to convert \p Unicode character
classes.
Conversion is fast (it runs in linear time in the size of the regex), but it is
not without some overhead. Making converted regex patterns static as shown
above saves the cost of conversion to just once to support many matchings.
This version of RE/flex strives to adhere to best-practices in terms of code quality, project organization, and deployment to overcome some of the original fragility at the time the project was forked.
Contributions in-line with these goals are encouraged.
A full list of the reflex executable options are available using the help option:
$ reflex --help
A man page is also installed
$ man reflex
HTML documentation is also installed and available by pointing your browser to $(prefix)/share/doc/reflex/html/index.html where $(prefex) is the installation prefix. For example, on Mac OS, issuing the following will open the documentation web page in your default browser.
$ open /usr/local/share/doc/reflex/html/index.html
RE/flex was originally written by Robert van Engelen, Genivia Inc and includes contributions by others.
Updating the build system to Autotools by Michael B Tegtmeyer
RE/flex is distributed under the BSD 3 clause license - see the COPYING for details.